







实验是设计用于验证假设的,我们希望所设计的实验能得出结论性的结果。实验中会收集并分析数据,进而得出结论。推断(inference)一词反映了这样一个意图:将从有限数据集上得到的实验结果应用于更大的过程或总体。
A/B 测试将实验分成两个组开展,进而确定两种处理、产品、过程等中较优的一个。在两组实验中,一般会有一组采用现有的标准处理,或者是不执行任何处理,称为对照组,而另一组称为实验组。实验中的一个典型假设是实验组要优于对照组。

(一)名词解释
总体:一个大型数据集,或是一个构想的数据集。------某应用的所有用户
样本:大型数据集的一个子集。------实验组与对照组用户
检验统计量:用于检验处理效果的度量。
均值:变量值的算数平均数。
方差:各变量值与其算术平均数离差平方的算术平均数。标准差是方差的平方根。
参数:用来描述总体特征的概括性数字度量
大数定理:当试验条件不变时,随机试验重复多次以后,随机事件的频率近似等于随机事件的概率。
中心极限定理:对独立同分布且有相同期望和方差的n个随机变量,当样本量很大时,随机变量
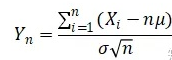 近似服从标准正态分布N(0,1)。
近似服从标准正态分布N(0,1)。
简单随机抽样:在不对总体分层的情况下,做随机抽样所得到的样本。
(二)参数估计:用样本统计量去估计总体参数。
点估计:用样本估计量的值直接作为总体参数
区间估计:点估计的基础上,给出总体参数的一个概率范围。
(三)假设检验
假设检验是根据一定的假设条件,由样本推断总体的一种方法。
假设检验的基本思想是小概率反证法思想,小概率思想认为小概率事件在一次试验中基本上不可能发生,在这个方法下,我们首先对总体作出一个假设,这个假设大概率会成立,如果在一次试验中,试验结果和原假设相背离,也就是小概率事件竟然发生了,那我们就有理由怀疑原假设的真实性,从而拒绝这一假设。
• 零假设的逻辑理念体现为没有特殊事件发生,任何观察到的效果都是由随机偶然导
致的。
• 假设检验假定零假设为真,创建“零模型”(一种概率模型),并检验所观察到的效
果是否是该模型的合理结果。
零假设:完全归咎于偶然性的假设。
备择假设:与零假设相反,即实验者希望证实的假设。
单向检验:在假设检验中,只从一个方向上计数偶然性结果。一种有方向的备择假设(即 B 比 A 好)。这种情况下,我们可以使用单向(或“单尾”)假设检验。
双向检验:在假设检验中,从正反两个方向上计数偶然性结果。想要假设检验使我们免受任意方向上偶然性的愚弄,那么备择假设应该是双向的(即A 不同于 B,它可能更大,或是更小)。在这种情况下,我们要使用双向(或“双尾”)假设。
第I类错误:H0为真,H1为假时,拒绝H0,犯第I类错误(即错误地拒绝H0)的概率记为alpha。
第II类错误:H0为假,H1为真时,接受H0,犯第II类错误(即错误地接受H0)的概率记为beta。
α 是一个概率值,表示原假设为真时, 拒绝原假设的概率,也称为抽样分布的拒绝域。在这两类错误中,相对更加严重的是第 I 类错误,所以 α 的取值应尽可能小。
显著性水平 p是指在原假设为真的条件下,样本数据拒绝原假设这样一个事件发生的概率(越小越不能拒绝原假设,实验样本却在小概率情况下发生,说明观察值不能代表样本整体,所以越接受备择假设)。例如,我们根据某次假设检验的样本数据计算得出显著性水平 p = 0.04;这个值意味着如果原假设为真,我们通过抽样得到这样一个样本数据的可能性只有 4%。
当p-value<alpha时,即原假设成立的概率小于预设的显著性水平,可拒绝原假设。p-value只说明两个样本有没有显著性差异,并不说明差异的大小。
因此,至于α水平,它是我们人为设定的拒绝域,通常来说我们会把它设定为0.05,这意味着,当原假设为真时,我们的抽样只有5%的可能性落在该区域内。P < α(小概率事件发生,拒绝原假设)表达的是在一次抽样中出现当前结果及更极端结果的可能性比我们认为的在一次抽样中不可能发生的小概率事件的概率更小,也就是说我们的观察结果比我们设定的拒绝程度更加极端。 所以在样本量不变的情况下,P值比α水平越小,我们就越有信心认为这个样本不属于原假设分布代表的总体,就越有信心拒绝原假设。

(四)检验方法
常用的假设检验方法有 z 检验、t 检验和卡方检验等,不同的方法有不同的适用条件和检验目标。
1、有关平均值参数u的假设检验
根据是否已知方差,分为两类检验:U检验和T检验。
如果已知方差,则使用U检验,如果方差未知则采取T检验。
2、有关参数方差σ2的假设检验
F检验是对两个正态分布的方差齐性检验,简单来说,就是检验两个分布的方差是否相等
3、检验两个或多个变量之间是否关联
卡方检验属于非参数检验,主要是比较两个及两个以上样本率(构成比)以及两个分类变量的关联性分析。根本思想在于比较理论频数和实际频数的吻合程度或者拟合优度问题。
-------U检验又称Z检验。
Z检验是一般用于大样本(即样本容量大于30)平均值差异性检验的方法(总体的方差已知)。它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数的差异是否显著。
Z检验步骤:
第一步:建立虚无假设 H0:μ1 = μ2 ,即先假定两个平均数之间没有显著差异,
第二步:计算统计量Z值,对于不同类型的问题选用不同的统计量计算方法,
1、如果检验一个样本平均数(X)与一个已知的总体平均数(μ0)的差异是否显著。其Z值计算公式为:
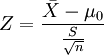
其中:
X是检验样本的均值;
μ0是已知总体的平均数;
S是总体的标准差;
n是样本容量。
2、如果检验来自两个的两组样本平均数的差异性,从而判断它们各自代表的总体的差异是否显著。其Z值计算公式为:

----------T检验
主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布。目的是用来比较样本均数所代表的未知总体均数μ和已知总体均数μ0。
T统计量计算公式: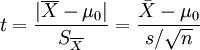
自由度:v=n - 1
T检验的步骤
第一步:建立虚无假设H0:μ1 = μ2,即先假定两个总体平均数之间没有显著差异;
第二步:计算统计量T值,对于不同类型的问题选用不同的统计量计算方法
1、如果要评断一个总体中的小样本平均数与总体平均值之间的差异程度,其统计量T值的计算公式为:
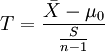
2、如果要评断两组样本平均数之间的差异程度,其统计量T值的计算公式为:
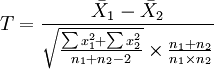
第三步:根据自由度df=n-1,查T值表,找出规定的T理论值并进行比较。理论值差异的显著水平为0.01级或0.05级。不同自由度的显著水平理论值记为T(df)0.01和T(df)0.05
第四步:比较计算得到的t值和理论T值,推断发生的概率,依据下表给出的T值与差异显著性关系表作出判断。
第五步:根据是以上分析,结合具体情况,作出结论。
实际应用中,T检验可分为三种:单样本T检验、配对样本T检验和双独立样本T检验
------------卡方检验又称X2检验,就是检验两个变量之间有没有关系。
属于非参数检验,主要是比较两个及两个以上样本率(构成比)以及两个分类变量的关联性分析。根本思想在于比较理论频数和实际频数的吻合程度或者拟合优度问题。
X2计算公式为:
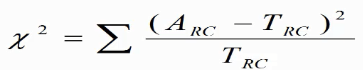
--------------F检验法是检验两个正态随机变量的总体方差是否相等的一种假设检验方法。
F统计量计算公式:
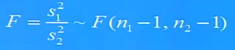
(五)样本量计算的python实现
Python统计包statsmodels.stats.power中,有一个NormalIndPower,GofChisquarePower
工具,可以用其中的solve_power函数实现。
Solve_power函数中的参数如下:
(1)参数effect_size : Z:两个样本均值之差/ 标准差 (原来样本值*(1-原来样本值))的开方
卡方:
(2)nobs1:样本1的样本量,样本2的样本量=样本1的样本量*ratio
(3)alpha:显著性水平,一般取0.05
(4)power:统计功效,一般去0.8
(5)ratio: 样本2的样本量/样本1的样本量,一般取1
(6)alternative:字符串str类型,默认为‘two-sided’,也可以为单边检验:’larger’ 或’small’
例:目前的点击率CTR是0.3,我们要想提升10%,将点击率提升到0.33,测试组和对照组的样本量相同。
from statsmodels.stats.power import NormalIndPower
import math
effect_size = 0.03/math.sqrt(0.3*(1-0.3))
ztest = NormalIndPower()
num = ztest.solve_power(
effect_size = effect_size,
nobs1 = None,
alpha = 0.05,
power= 0.8,
ratio=1,
alternative = 'two-sided')
print (num)
import numpy as np
import pandas as pd
from scipy import stats
Z检验:statsmodels.stats.weightstats.ztest(x1, x2=None, value=0, alternative='two-sided', usevar='pooled', ddof=1.0)[source]
T检验:t_estm = stats.t.rvs(df=df, loc=loc, scale=scale, size=sample_size)|stat, p = stats.ttest_ind(male_df['Temperature'],female_df['Temperature']) 双样本
ks = stats.t.fit(temp)
df = ks[0]
loc = ks[1]
scale = ks[2]
t_estm = stats.t.rvs(df=df, loc=loc, scale=scale, size=sample_size)
stats.ks_2samp(temp, t_estm)
卡方检验:chi_estm = stats.chi2.rvs(df=df, loc=loc, scale=scale, size=sample_size)
chi_square = stats.chi2.fit(temp)
df = chi_square[0]
loc = chi_square[1]
scale = chi_square[2]
chi_estm = stats.chi2.rvs(df=df, loc=loc, scale=scale, size=sample_size)
stats.ks_2samp(temp, chi_estm)
补充:置信区间计算理解
















 1389
1389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









