







作用:
用来加入非线性因素,因为线性模型的表达力不够。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。例如y=ax+b,当x很大,y会增大,随着网络深度的叠加,y会一直膨胀,这样深度网络就失去了意义。激活函数通过给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。输出层可能会使用线性激活函数,但在隐含层都使用非线性激活函数,一般加在每层的后面,影响每层的输出值。
常见的激活函数:
①sigmoid函数
又称 Logistic函数,非线性激活函数。X可以是正无穷到负无穷,y在0-1之间,即通过该函数能够把输入值“压缩”到0~1之间。
取值过高或呈现饱和态,所以最优取值为-3~3之间。适用于输出值为大于0的情况
函数表达式:
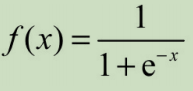
图像:
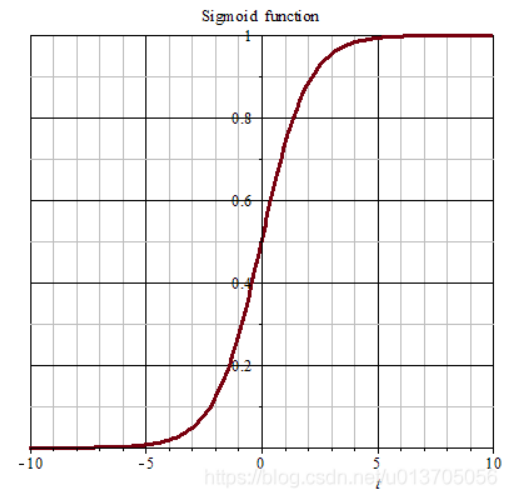
优点:
1.输出范围有限
2.连续函数,便于求导
缺点:
1.sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和现象,意味着函数会变得很平,并且对输入的微小改变会变得不敏感。在反向传播时,当梯度接近于0,权重基本不会更新,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练
2.sigmoid函数的输出不是0均值的,会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响。
3.计算复杂度高,因为sigmoid函数是指数形式。
②Tanh函数
也称为双曲正切函数,非线性激活函数。Sigmoid函数的值域升级版,y在-1~1之间
同样具有饱和态问题,输入值不能过高
函数表达式:
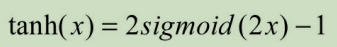
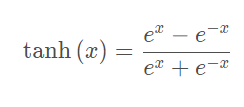
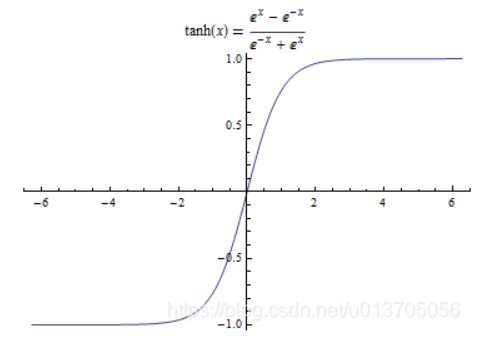
Tanh函数是 0 均值的,因此实际应用中 Tanh 会比 sigmoid 更好。但是仍然存在梯度饱和与exp计算的问题。
③Relu函数
整流线性单元(Rectified linear unit,ReLU)是现代神经网络中最常用的激活函数,大多数前馈神经网络默认使用的激活函数。
大于0的留下,否则都为0
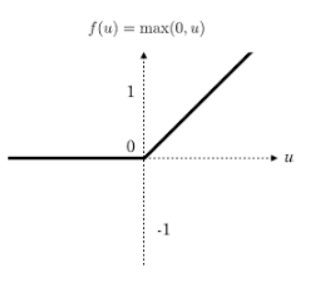

优点:
- 收敛速度比 sigmoid 和 tanh 快
2.在x>0区域上,不会出现梯度饱和、梯度消失的问题
3.计算复杂度低,不需要进行指数运算,只要一个阈值就可以得到激活值
缺点:
1.ReLU的输出不是0均值的
2.ReLU在负数区域被kill的现象叫做dead relu。ReLU在训练的时很“脆弱”。在x<0时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
产生这种现象的两个原因:参数初始化问题;learning rate太高导致在训练过程中参数更新太大。
解决方法:采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
④Leaky ReLU函数
为了解决dead ReLU现象。用一个类似0.01的小值来初始化神经元,从而使得ReLU在负数区域更偏向于激活而不是死掉。这里的斜率都是确定的。
如图所示,在输入小于0时,虽然输出值很小但是值不为0。leakyrelu激活函数一个缺点就是它有些近似线性,导致在复杂分类中效果不好。















 9246
9246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









