







 主成分分析(PCA)是一种常见的数据降维算法,通过找到最大化方差的方向向量来减少数据的维度,从而实现数据压缩和可视化。PCA与线性回归不同,它关注的是投影误差而非预测误差。PCA过程包括数据预处理、协方差矩阵计算、奇异值分解等步骤。错误使用PCA可能包括用于防止过拟合和默认作为学习过程的一部分,而正则化可能是更好的解决方案。
主成分分析(PCA)是一种常见的数据降维算法,通过找到最大化方差的方向向量来减少数据的维度,从而实现数据压缩和可视化。PCA与线性回归不同,它关注的是投影误差而非预测误差。PCA过程包括数据预处理、协方差矩阵计算、奇异值分解等步骤。错误使用PCA可能包括用于防止过拟合和默认作为学习过程的一部分,而正则化可能是更好的解决方案。
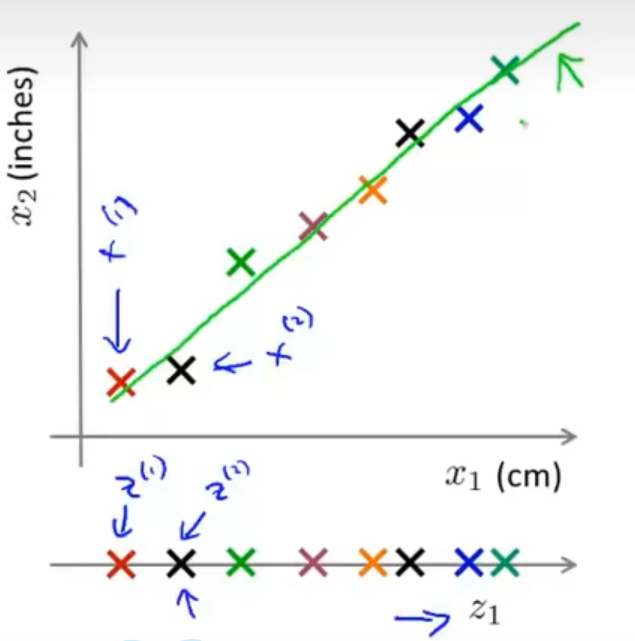
降维是指在某些限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程(较本质的解释)。换言之,降维其更深层次的意义在于有效信息的提取综合及无用信息的摈弃。数据降维算法是机器学习算法中的大家族,与分类、回归、聚类等算法不同,它的目标是将向量投影到低维空间,以达到某种目的如可视、数据压缩,或是做分类。
主成分分析(PCA)是常用的降维算法。在PCA中,我们要做的是找到一个低维平面,当我们将所有数据都投影到该平面上时,希望投影误差(Projection error)能尽可能地小(与投影后对应之间的点距离的平方值)。
将2维降至1维的情况中,PCA要做的是去找到一个数据投影后能够最小化投影误差的方向向量。对于将 n 维降至 k 维的情况,PCA要做的是找到 k 个方向向量来对数据进行投影来最小化投影误差。
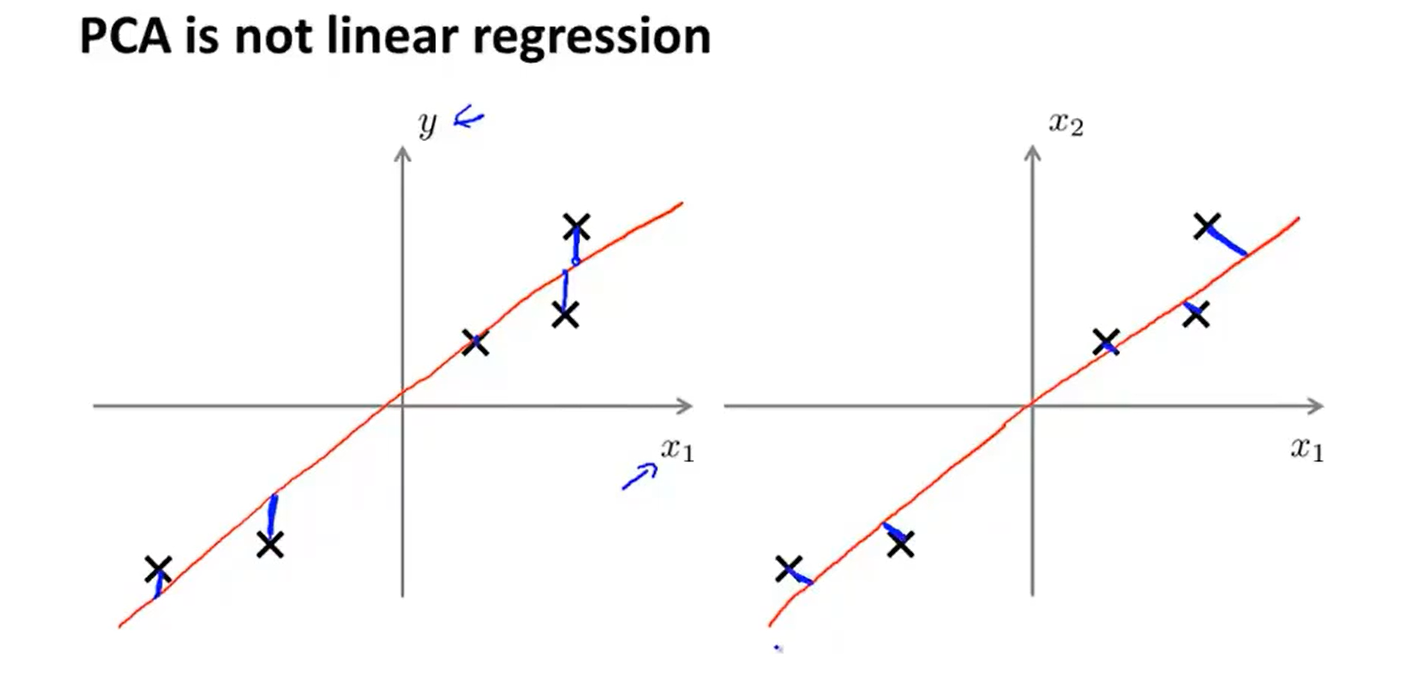
需要注意的是,主成分分析与线性回归是两种不同的算法。如下图所示,左边的是线性回归的误差(垂直于横轴投影),右边是主成分分析的误差(垂直于方向向量投影)。主成分分析最小化的是投影误差;线性回归尝试的是最小化预测误差。
主成分分析算法的过程:
①对数据进行预处理
计算出所有特征的均值
然后令
如果特征是在不同的数量级上,我们还需要将其除以标准差 ,
为标准差。
②n维->k维
计算协方差矩阵
③奇异值分解
计算协方差矩阵的特征向量,
取矩阵U的前 k 列得到 ,
然后
我们希望在平均均方误差与训练集的总方差的比例,尽可能小的情况下选择尽可能小的 k 值。如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。

重建压缩:
通过以上主成分分析算法的过程,我们已经知道了如何降维,那么,我们降维之后,又怎么重建到原来的n维呢?
其实也不难,我们,
。
PCA算法的错误使用:
一个常见的错误使用PCA算法的情况是,将其用于防止过拟合(减少了特征的数量)。减少数据维度来防止过拟合的方法不是解决过拟合问题的好方法,不如尝试正则化处理。原因在于主成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。
另一个常见的错误是,默认地将主成分分析作为学习过程中的一部分,这虽然在很多时候都有效果,但最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主成分分析。

















 1439
1439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









