







0.论文摘要
合并多个摄像机视图进行检测减轻了拥挤场景中遮挡的影响。在多视图检测系统中,我们需要回答两个重要问题。首先,我们应该如何从多个视图中聚合线索?第二,我们应该如何从空间上相邻的位置聚集信息?为了解决这些问题,我们引入了一种新的多视图检测器MVDet。在多视图聚合期间,对于地面上的每个位置,现有方法使用多视图anchor box特征作为表示,这可能会限制性能,因为预定义的anchor box可能不准确。相比之下,通过特征图透视变换,MVDet采用无anchor点表示,特征向量直接从多个视图中的相应像素采样。对于空间聚合,与以前需要在神经网络之外进行设计和操作的方法不同,MVDet采用完全卷积的方法,在多视图聚合要素图上使用大卷积核。所提出的模型是端到端可学习的,在Wildtrack数据集上实现了88.2%的MODA,比最先进的模型高出14.1%。我们还在新引入的合成数据集MultiviewX上提供了MVDet的详细分析,这使我们能够控制遮挡水平。
1.研究背景
遮挡是许多计算机视觉任务面临的基本问题。具体来说,在检测问题中,遮挡带来了很大的困难,并且已经提出了许多方法来解决它。一些方法集中于单视图检测问题,例如,基于部分的检测[35,25,48],损失设计[46,39],以及学习非最大抑制[13]。其他方法从多个线索联合推断对象,例如RGB-D[10,12,27]、激光雷达点云[6]和多个RGB相机视图[8,3]。在本文中,我们重点研究了来自多个RGB相机视图(多视图)的行人检测。
多视角行人检测通常具有来自多个校准摄像机的同步帧作为输入[8,29,3]。这些摄像机聚焦在同一个区域,
并且具有重叠的视野(参见图1)。相机校准提供2D图像坐标(u,v)和3D世界位置(x,y,z)之间的匹配。我们将3D世界中z=0的点称为地平面(鸟瞰视图)。对于地平面上的每个点,基于三维人体宽度和高度假设,通过投影计算其在多个视图中对应的边界框,然后存储。由于边界框可以通过表格查找检索,多视图行人检测任务通常评估地平面上的行人占用情况[8,3]。
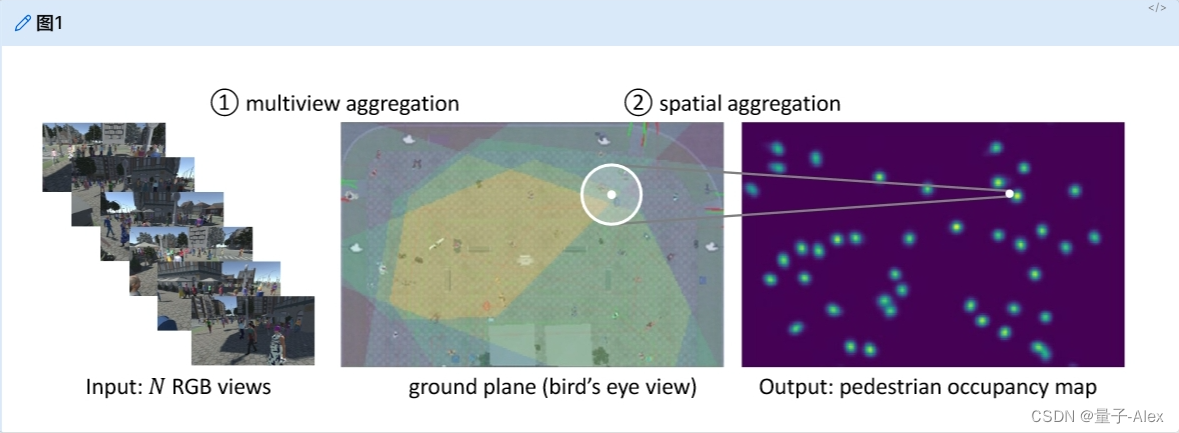
图1。多视角行人检测系统概述。左图:系统将来自N台摄像机的同步帧作为输入。中间:摄像机视野在地平面上重叠,多视图线索可以在地平面上聚合。右图:系统输出行人占用图(POM)。这里有两个重要的问题。首先,我们如何聚合多个线索。第二,如何聚合空间邻居信息进行联合考虑(大白圈),对行人占用情况做出综合决策(小白圈)。
解决遮挡和拥挤带来的模糊性是多视角行人检测的主要挑战。在遮挡状态下,很难确定一个人是否存在于某个位置,或者存在多少人以及他们在哪里。为了解决这个问题,必须关注多视图检测的两个重要方面:第一,多视图聚合,第二,空间聚合(图1)。多视图信息的聚合是必不可少的,因为具有多视图是单视图检测和多视图检测之间的主要区别。以前,对于给定的地平面位置,多视图系统通常选择基于anchor的多视图聚合方法,并用多视图anchor box特征表示特定的地平面位置[4,1,17]。然而,研究人员发现,基于anchor的方法的性能可能会受到单目视图系统中预定义anchor box的限制[49,16,43],而根据预定义的人体3D高度和宽度计算的多视图anchor box也可能不准确。空间邻居的聚集对于遮挡推理也是至关重要的。以前的方法[8,29,1]通常采用条件随机场(CRF)或平均场推断来共同考虑空间邻居。这些方法通常需要特定的潜在项设计或卷积神经网络(CNN)之外的额外操作。
在本文中,我们提出了一种简单而有效的方法,MVDet,这是迄今为止还没有在文献中探索的多视图检测。首先,对于多视图聚合,由于基于不准确的anchor box的表示会限制系统性能,而不是基于anchor的方法[4,1,17],MVDet选择具有在多个视图中的相应像素处采样的特征向量的无anchor表示。具体来说,MVDet通过透视变换投影卷积特征图,并连接多个投影的特征图。第二,对于空间聚合,为了最大限度地减少CNN之外的人工设计和操作,MVDet采用了完全卷积的解决方案,而不是CRF或平均场推理[8,29,1]。它在聚合的地平面特征图上应用(学习的)卷积,并使用大感受野来共同考虑地平面相邻位置。所提出的全卷积MVDet可以以端到端的方式进行训练。我们在两个大规模数据集上证明了MVDet的有效性。在真实世界的数据集Wildtrack上,MVDet实现了88.2%的MODA[15],比以前的最先进水平增加了14.1%。在合成数据集MultiviewX上,MVDet也在多级遮挡下取得了有竞争力的结果。
2.相关工作
2.1 Monocular view detection 单目检测
检测是计算机视觉中最重要的问题之一。像faster R-CNN[28]和SSD[21]这样基于anchor的方法实现了很好的性能。最近,寻找预定义的anchor可能会限制性能,提出了许多无anchor方法[49,36,16,43,7,18]。在行人检测方面,一些研究人员通过头—脚点检测[32]或中心和比例检测[22]来检测行人边界框。行人检测中的遮挡处理引起了研究界的极大关注。基于部分的检测器非常受欢迎[25,35,24,46],因为被遮挡的人只能部分观察到。霍桑等人。[13]学习遮挡行人的非最大抑制。排斥损失[39]被提出来排斥边界盒。
2.2 3D object understanding with multiple information sources
结合多个信息源,如深度、点云和其他RGB相机视图,研究了3D对象理解。对于多视图三维物体分类,苏等。[33]使用最大池化来聚合来自不同2D视图的特征。对于三维目标检测,来自RGB图像和激光雷达点云的聚合信息被广泛研究。陈等。[5]研究了立体图像的三维目标检测。[17]中研究了3Danchor点的视图聚合,研究人员从RGB相机和激光雷达鸟瞰图中提取每个3Danchor点的特征。梁等。[19]从K个最近邻激光雷达点的相机视图特征计算鸟瞰视图中每个点的特征,作为多层感知器输出。平截头体点网[27]首先从RGB图像生成2D边界框建议,然后将它们挤压到3D观察平截头体。姚等。编辑3D车辆模型的属性,以创建内容一致的车辆数据集[44]。
2.3 Multiview pedestrian detection
在多视角行人检测中,首先,聚合来自多个RGB摄像机的信息至关重要。在[4,1]中。搜索者为多视图2Danchor融合多个信息源。给定人的宽度和高度的固定假设,首先计算所有地平面位置及其对应的多视图2Danchor box。然后,[4,1]中的研究人员用相应的anchor box特征来表示地平面位置。在[8,41,29]中,单视图检测结果被融合。第二,为了聚集空间邻居信息,利用了平均场推断[8,1]和条件随机场(CRF)[29,1]。在[8,1]中,场景中的总占用率被视为能量最小化问题,并用CRF解决。弗勒特等人。[8]首先估计一定占用率下的理想2D图像,然后将它们与真实的多视图输入进行比较。巴克等人。[1]构造高阶势作为CNN估计和生成的理想图像之间的一致性,并以组合的方式用CNN训练CRF,并在Wildtrack数据集上实现最先进的性能[3]。
2.4 Geometric transformation in deep learning
仿射变换和透视变换等几何变换可以对计算机视觉中的许多现象进行建模,并且可以用一组固定的参数显式计算。Jaderberg等人[14]提出了空间Transformer model网络,该网络学习用于2D RGB输入图像的平移和旋转的仿射变换参数。Wu等[40]估计投影参数并从3D骨架投影2D关键点。Yan等[42]通过透视变换将一个3D体积转换为2D剪影。[38]中通过估计实例级仿射变换研究了几何感知场景文本检测。对于交叉视图图像检索,Shi等[30]应用极坐标变换使特征空间中的表示更接近。Lv等为车辆的新型视图合成提出一个透视感知生成模型[23]。
3.核心思想
在这项工作中,我们重点研究了多视图场景中的遮挡行人检测问题,并设计了MVDet来处理模糊度。MVDet的特点是无anchor多视图聚合,减轻了以前工作中不准确anchor box的影响[6,17,4,1],以及不依赖于CRF或平均场推断的完全卷积空间聚合[8,29,1]。如图2所示,MVDet将多个RGB图像作为输入,并输出行人占用图(POM)估计。在接下来的章节中,我们将介绍建议的多视图聚合(第3.1节)、空间聚合(第3.2节)以及训练和测试配置(第3.3节)。
3.1 Multiview Aggregation
多视图聚合是多视图系统中非常重要的一部分。在本节中,我们将解释MVDet中减轻不准确anchor box影响的无anchor聚合方法,并将其与几种替代方法进行比较。
3.1.1 Feature map extraction
在MVDet中,首先,给定N个形状为 [ H i , W i ] [H_i, W_i] [Hi,Wi]的图像作为输入( H i H_i Hi和 W i W_i Wi表示图像高度和宽度),所提出的架构使用CNN来提取N个C通道特征图(图2)。
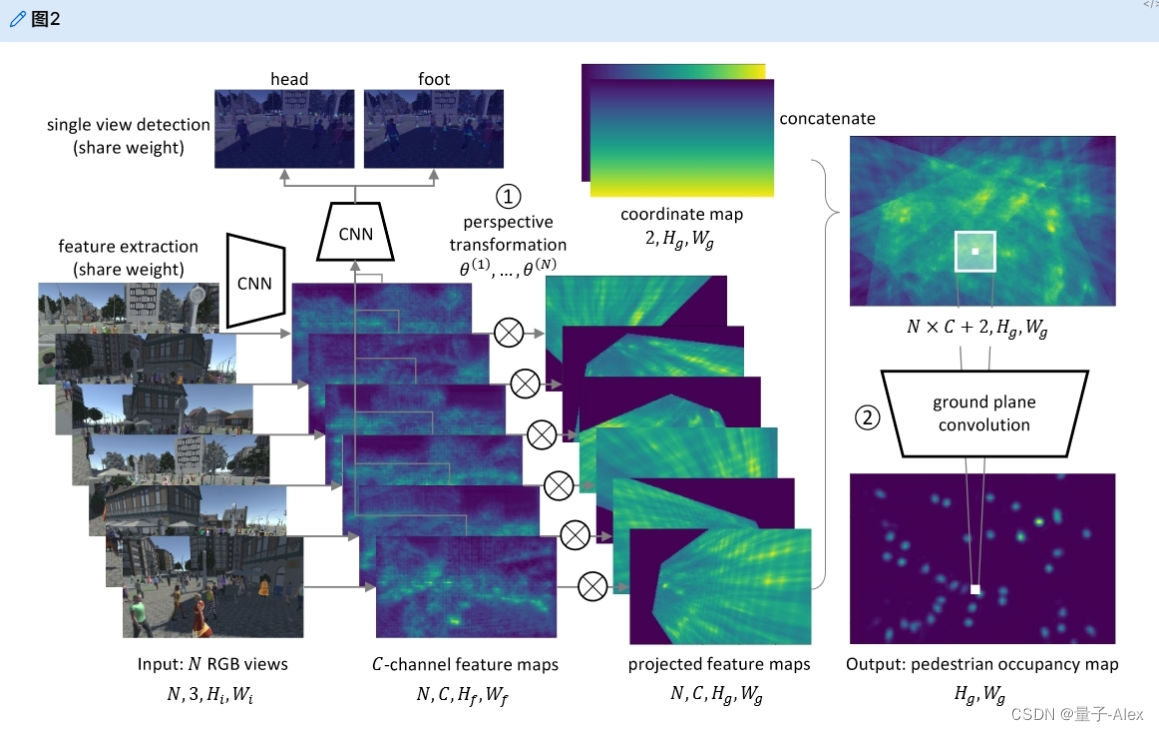
图二。MVDet架构。首先,给定来自N个摄像机的形状 [ 3 , H i , W i ] [3, H_i, W_i] [3,Hi,Wi]的输入图像,所提出的网络使用CNN来提取每个输入图像的C通道特征图。这里的CNN特征提取器在N个输入中共享权重。接下来,我们将C通道特征图重塑为 [ H f , W f ] [H_f , W_f ] [Hf,W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











