







整体概览
思维导图
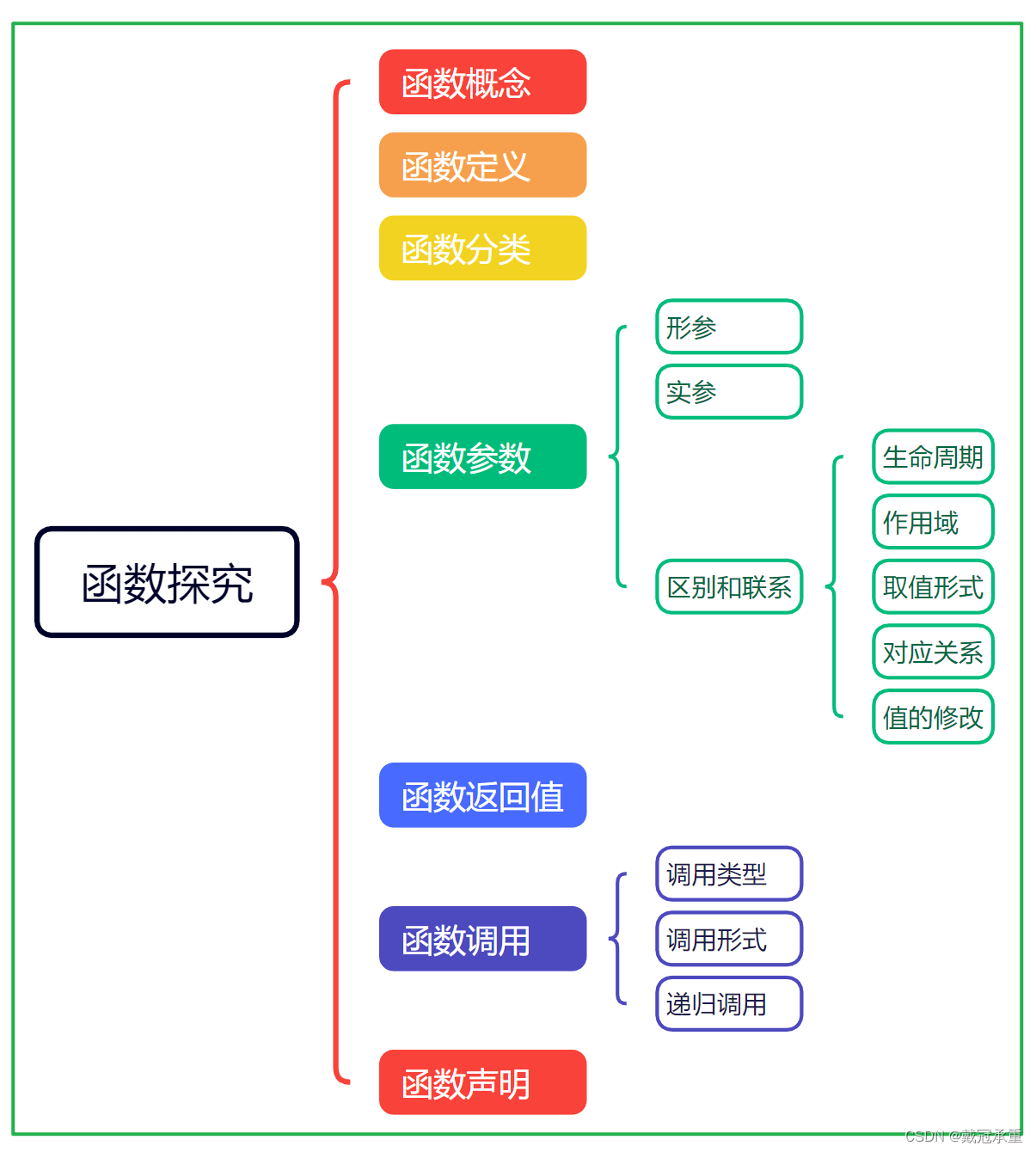
函数的概念
函数是一段代码块,用于执行特定任务,并可在程序中多次调用。函数被视为一个独立的模块。
函数的作用是封装代码,以便于复用和分模块开发等。
函数定义
定义函数需要说明返回值类型、函数名、参数和内部代码。
定义结构如下所示:
dateType funName(dateType1 param1...)
{
body;
}
dateType是返回值的数据类型,可以是C语言中任意的数据类型,如基本类型int、指针类型char*等。使用return语句返回返回值,并赋给调用函数。- void类型是空类型,表示没有返回值。
funName是函数名,本质上是一种标识符。因此,命名规则和变量名相同。在程序中,可以通过变量名访问变量保存的数据;同样,可以通过函数名来执行函数封装的代码。dateType1 param1是形参,本质就是一个变量,但是没有初始化。参数用于接收传递给函数的数据。body是函数的核心代码,使用花括号{}包围,形成一个作用域。
例如,定义一个交换函数,用于交换两个变量的值:
#include <stdio.h>
void swap(int* num1, int* num2)
{
int tmp = *num1;
*num1 = *num2;
*num2 = tmp;
}
int main()
{
int num1 = 10;
int num2 = 20;
swap(&num1, &num2);
printf("%d %d\n", num1, num2);
return 0;
}
运行结果:20 10
其中,通过传递变量的地址,函数内部可以修改变量的值,从而实现对外部变量的修改。
注意:函数内部不能再定义新的函数。例如,函数不能嵌套定义在main函数内部,只能定义在main函数外部,因为main函数本身就是一个函数定义。
函数的分类
函数可以分为库函数和自定义函数。
- 自定义函数可以进一步分为有参函数和无参函数。
- 有参函数可以接收用户传递的数据,而无参函数不接受数据。
库函数是事先编写好,分门别类地放在指定的头文件中。
自定义函数由程序员自行设计。
例如常见的库函数:输出函数
printf("%s\n", "我是库函数");
常见的自定义函数:二分查找函数
BinaryFind(int arr[], int num);
函数的参数
函数名右边用括号()包围的变量,称为参数。
例如,在strlen(str)中,str就是strlen函数的参数。
函数可以接收零个或者多个参数,参数用于接收并传递值给函数内部使用。
在函数使用过程中,参数会出现在函数调用处的实参和函数定义处的形参两个地方。
形参
形参是函数定义中的参数,本质是一个变量,需要指定数据类型和变量名。但是它们没有保存数据,而是等待被赋值,用于接收函数被调用时传递的数据。
实参
实参是函数调用中的参数,可以是数据或变量,是具体的数据,用于传递给函数内部使用。
以下是一个例子:
//创建一个结构体类型
typedef int SLDataType;
typedef struct Seqlist
{
SLDataType* a; //存储空间
int size; //实际数据量
int capacity; //容量
}SL;
//顺序表初始化
void SLInit(SL* s)
{
assert(s);
s->a = (SLDataType*)malloc(sizeof(SLDataType) * 4);
s->capacity = 4;
s->size = 0;
}
int main()
{
//创建一个结构体变量
SL s1;
//顺序表初始化
SLInit(&s1);
return 0;
}
-
在
main函数中,s1是一个结构体变量。 -
在调用
SLInit(&s1)函数时,&s1是传递给SLInit函数的实参。 -
在
SLInit(SL* s)函数中,s是接收结构体变量地址的形参。
形参和实参的区别和联系
生命周期
形参只在函数调用时创建,并分配内存空间。调用结束后,形参的内存空间就会被释放。
实参不受函数调用影响,创建和释放由主调函数负责。
作用域
形参实际上是函数内部的局部变量,只能在函数内部使用。
实参不能直接在被调函数内部使用,只能将实参的值传递给被调函数使用。
取值形式
形参和实参都可以是常量、变量、表达式、数组、函数等。但实参必须具有确定的值,而形参在赋值前没有确定的值。
对应关系
由于将实参的值传递给形参,仅是一次赋值操作,因此形参和实参的数量、数据类型和顺序都必须一致。(除非发生隐式转换)。
值的修改
实参可以通过赋值操作改变形参的值,但是修改形参不会改变实参。因为实参和形参分处于不同的作用域,使用不同的内存空间,所以形参的改变无法影响实参。
以下是一个示例:
//创建一个结构体类型
typedef int SLDataType;
typedef struct Seqlist
{
SLDataType* a; //存储空间
int size; //实际数据量
int capacity; //容量
}SL;
//顺序表初始化
void SLInit(SL* s)
{
assert(s);
s->a = (SLDataType*)malloc(sizeof(SLDataType) * 4);
s->capacity = 4;
s->size = 0;
}
int main()
{
//创建一个结构体变量
SL s1;
//顺序表初始化
SLInit(&s1);
return 0;
}
- 生命周期
- 函数
SLInit(SL* s)的形参s只有在该函数被调用时被创建。当该函数执行后,形参s会被销毁(内存返回给操作系统)。 - 在函数
SLInit(&s1)中,实参&s1即使在该函数调用结束后,依然存在。
- 函数
- 作用域
- 因为形参和实参处于不同的作用域,当函数
SLInit需要使用实参s1的值时,只能将s1的值拷贝一份给形参,不能直接在函数内部访问实参s1。
- 因为形参和实参处于不同的作用域,当函数
- 取值方式
- 函数
SLInit(&s1)中的&s1是地址,只要C语言中的数据类型都可以作为实参传递。
- 函数
- 对应关系
- 实参
&s1是结构体变量的地址,因此形参必须是一个结构体类型的指针变量。
- 实参
- 值的修改
- 当函数
SLInit需要改变实参s1的值时,需要将s1的地址&s1传递给形参,使得在函数SLInit内部可以访问s1的内存空间,从而修改函数外部(非函数作用域中)s1的值。
- 当函数
函数的返回值
函数执行后的处理结果称为返回值。
返回值被返回给函数调用语句,可以使用变量保存或者直接用于条件判断等。
返回值是一个数据,是数据就有数据类型,这个类型由函数实现的功能决定。例如,如果函数用来处理字符串,返回值应该是字符串的首地址;如果函数是来处理链表,返回值应该是指向头结点的指针。
关于返回值,有下面几点说明:
- 返回值由return语句返回,使用方式如下:
return 返回值;
-
返回值可以是具体的值、也可以是变量或表达式等。
-
当返回值类型是void类型时,不需要使用return语句。
对函数中的return语句,还有以下几点说明:
- return语句可以存在多个,但函数只会执行一个。
例如下面的比较大小函数:
int getMax(int a, int b)
{
if(a > b)
{
return a;
}
else
{
return b;
}
}
函数getMax中存在两个return语句。如果 a > b,只执行return a这个返回语句。如果a<=b,只执行return b这个返回语句。
-
return 语句还有结束函数的作用。
例如:
int getMax(int a, int b) { if(a > b) { return a; printf("%d\n", a); } else { return b; printf("%d\n", b); } }函数
getMax中的两条跟在return语句后面的printf打印语句都不会被执行。因为当执行到return时,直接结束函数的执行,其后剩余的代码没有机会执行。
函数的调用
函数调用顾名思义就是使用函数。在函数定义后,如果不调用是不会执行的。
函数调用有一个特点,当执行到函数调用语句时,程序会临时停止执行后面的代码,转而去执行调用的函数体。
调用的格式如下:
funName(param);
其中,funName函数名和param是传递给函数的实参值。
调用的类型
函数调用分为传值调用和传址调用两种类型。
-
传值调用:将实参的值拷贝一份给形参,在函数内部使用形参进行计算,形参的修改不会影响到实参。
-
传址调用:将实参的地址拷贝一份给形参,在函数内部可以访问实参的内存空间,从而修改实参保存的值。因此形参和实参的值改变是双向的。
函数调用的形式:
-
直接调用:
getMax(1, 2); -
作为表达式的一部分:
int sum = 3 + getMax(1, 2); -
作为函数的实参:
swap(3, getMax(1, 2));
嵌套调用和递归调用
在C语言中,所有的函数(包括主函数main)都是平行的,函数内部不能创建新的函数,即不能嵌套定义。
但是函数内部可以调用其他函数,例如main函数可以调用库函数和自定义函数,这种调用方式称为嵌套调用。
嵌套调用
例如,在交换函数sawp中调用比较函数getMax:
#include <stdio.h>
void swap(int* num1, int* num2)
{
int tmp = *num1;
*num1 = *num2;
*num2 = tmp;
int ret = getMax(*num1, *num2);
}
int main()
{
int num1 = 10;
int num2 = 20;
swap(&num1, &num2);
printf("%d %d\n", num1, num2);
return 0;
}
上面的函数调用关系可以表示为:main–>sawp–>getMax。
递归调用
一个函数可以调用另一个函数,这被称为嵌套调用;一个函数也可以调用自己,这种调用方式称为递归调用。
例如,使用函数递归计算字符串的长度:
#include <stdio.h>
int my_strlen(char* str)
{
if (*str == 0)
{
return 0;
}
else
{
return 1 + my_strlen(str + 1);
}
}
int main()
{
char str[] = "jiang";
int len = my_strlen(str);
printf("%d\n", len);
return 0;
}
- 在上面的函数
my_strlen中,只要没遇到字符串结束符,就一直会执return 1 + my_strlen(str + 1)语句。 - 也就是函数
my_strlen内部会不断调用函数自身。
函数的声明
函数声明是为了让编译器知道函数的存在。
在C语言中,代码是按照从上到下,从左到右的顺序执行的。因此,在函数调用之前,应该提前声明函数,以便编译器能够识别。
函数声明的格式如下:
dataType funName(dataType1 param1...);
需要说明函数的返回值类型、函数名以及形参列表,最后作为一条语句以;结束。
例如,对交换函数的函数声明如下:
#include <stdio.h>
void swap(int* num1, int* num2); //函数声明
int main()
{
int num1 = 10;
int num2 = 20;
swap(&num1, &num2); //函数调用
printf("%d %d\n", num1, num2);
return 0;
}
//函数定义
void swap(int* num1, int* num2)
{
int tmp = *num1;
*num1 = *num2;
*num2 = tmp;
int ret = getMax(*num1, *num2);
}
在上述代码中,将函数声明放在函数调用之前,函数定义放在函数调用之后。
在实际的大型代码开发中,为了提高程序的可读性,避免主程序体积过大和内容混乱。通常将函数定义放在一个单独的源文件(.c文件)中,将函数声明放在头文件(.h文件中),而主程序放在另一个源文件中。只需要包含函数声明的头文件即可使用函数。
除自定义函数之外,库函数的使用也是只需引入了包含库函数声明的头文件,并未将函数定义部分引入。
此外,变量声明和自定义类型声明(如结构体类型声明)也应该放入一个共同的头文件中,以便于多个源文件的使用。
例如:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//创建一个结构体类型
typedef int SLDataType;
typedef struct Seqlist
{
SLDataType* a; //存储空间
int size; //实际数据量
int capacity; //容量
}SL;
//顺序表初始化
void SLInit(SL* s);
这是一个包含库函数头文件、类型声明和函数声明的头文件。其他源文件中只需要包含这个头文件就能使用这些函数和类型,而无需逐个包含各种头文件和声明。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









