






机器学习入门
引言
机器学习
机器学习:
一个程序被认为能从经验 E 中学习,解决任务 T ,达到性能度量值 P ,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。
监督学习
定义:
数据集中的每个样本都有相应的“正确答案”,再根据这些样本作出预测。(教计算机如何学习)
分为两类:
1)回归:推出一个连续的输出。
2)分类:推出一组离散的结果。
无监督学习
定义:
从数据集中找到某种结构,没有给算法正确答案来回应数据集中的数据。(机器自主学习)
聚类算法只是无监督学习中的一种。
单变量线性回归
模型表示
线性回归:
选择一条线性函数来很好的拟合已知数据并预测未知数据。
注:线性指自变量和因变量之间存在线性关系。
单变量线性回归:
只含有一个特征/输入变量的线性回归问题,如:
hθ(x) = θ0 + θ0 x
代价函数
在回归问题中用平方误差表示代价函数(损失函数),即模型所预测的值与训练集中实际值之差的平方和。
梯度下降
梯度下降算法是用于求代价函数最小值的算法。
开始时随机选择一个参数组合,计算代价函数,然后寻找下一个能让代价函数值下降最多的参数组合,直到找到一个局部最小值,不一定是全局最小值。选择不同的初始参数组合,可能会找到不同的局部最小值。

随着梯度下降法的运行,移动的步长会越来越小,直到最终移动步长非常小,此时已经收敛到局部最小值。因为在梯度下降法中,当接近局部最低点时,导数值会越来越小,所以移动步长越来越小,所以没有必要另外减小 α (学习率)。
- 批量梯度下降(BGD):
在每一次迭代时使用所有样本来进行梯度的更新。(迭代次数较少)
注:学习率决定沿着让代价函数下降程度最大的方向向下迈出的“步长”,即参数移动到最优值的速度。学习率过小时,优化效率过低,算法长时间无法收敛;学习率过大时,可能越过最优值,导致无法收敛甚至发散。
优点:
由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
当样本数目很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。 - 随机梯度下降(SGD):
每次迭代使用一个样本来对参数进行更新。(迭代次数较多)
优点:
由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,每一轮参数的更新速度大大加快。
缺点:
由于单个样本并不能代表全体样本的趋势,可能会收敛到局部最优或一直在最小值附近震荡,无法收敛到最小值。 - 小批量梯度下降(MBGD):
对批量梯度下降和随机梯度下降的折中,每次迭代使用 batch_size 个样本更新参数。
优点:
每次在一个 batch 上优化神经网络参数并不会比单个数据慢太多,大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近批量梯度下降的效果。
缺点:
batch_size 的不当选择可能会带来问题。
多变量线性回归
多维特征
n:特征的数量
m:训练实例的数量
x:输入/特征
y:输出/目标变量
(x,y):训练样本
x(i):第 i 个训练实例,特征矩阵的第 i 行,是一个向量。
xj(i):第 i 个训练实例的第 j 个特征
J:代价函数
h:模型假设,表示为 hθ(x) = θ0 x0 + θ1 x1 + θ2 x2 + … + θn xn( x0 =1)
模型中的参数是一个 n+1 维的向量,任何一个训练实例都是一个 n+1 维的向量,特征矩阵 X 的维度是 m*(n+1) 。
假设 h 是一个以 x 为变量的线性函数,则
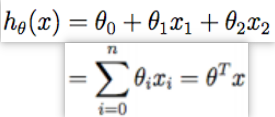
多变量梯度下降
多变量线性回归的代价函数:

多变量线性回归的批量梯度下降算法:

线性回归的代价函数 J(θ) 是凸函数,只有一个全局的而不是局部的最优解,用梯度下降法能收敛到全局最小值。
梯度下降法实践
-
特征缩放
面对多维特征问题时,尽量使所有输入特征具有相近的尺度,比如将所有特征的尺度都尽量缩放到 [-1,1] 之间。
如果输入的 n 维特征中,特征的区间范围相差很大,则代价函数收敛会很慢。为了提高收敛速度,可以将输入特征限制在相似的范围之内,有以下方法:
1)每一个特征量除以该特征量的最大值。如:x1: 500~2000,则 x/2000
2)均值归一化:(特征-均值)/(最大值-最小值)。(分母即特征值的范围) -
学习率
判断代价函数是否收敛的方法:
1)画出代价函数和迭代次数之间的关系。
2)将代价函数的变化值和设定的阈值进行比较。
如果代价函数随着迭代次数的增加而增加,说明此时的学习率设置过高,应该降低学习率。
如果代价函数先降低后增加、又降低又增加,此时仍是学习率过高。因为只要学习率足够低,那么代价函数是逐渐降低的。
学习率过低,则收敛缓慢;学习率过高,则甚至不会收敛。一般尝试学习率α=0.001,0.1。
特征和多项式回归
线性回归不适用于所有数据,有时需要曲线拟合数据,如:
二次方模型 hθ(x) = θ0 + θ1 x1 + θ2 x22
三次方模型 hθ(x) = θ0 + θ1 x1 + θ2 x22 + θ3 x33
注:采用多项式回归模型时,在运行梯度下降算法前应进行特征缩放。
正规方程
求解代价函数最小值的方法:
1)梯度下降法。
2)微积分中,令 J 对 θj 求导等于 0(j=0…n)得到 n+1 个式子,可以求解出 n 个参数 θ1~ θj ,计算量大。
3)正规方程。
正规方程求解涉及变量:
m:训练实例个数
n:特征个数
X:m 行 n 列的矩阵
θ:n 行 1 列的矩阵
y:m 行 1 列的矩阵
利用如下公式
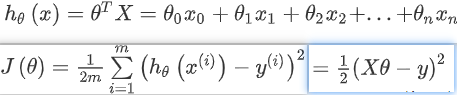
解出使 J 最小时的 θ 向量:
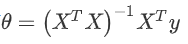
注:若矩阵不可逆,原因可能是特征之间不独立或特征数量大于训练集数量,此时不能使用正规方程求解。
梯度下降法和正规方程的比较:
- 梯度下降法需要设置学习率 α ,正规方程不需要。
- 梯度下降法需要进行多次迭代,正规方程只需一次运算得出最优参数。
- 当特征数量 n 较大时,梯度下降法仍适用,而正规方程法计算逆矩阵时的时间复杂度过高,运算代价大( n<10000 时适用)。
- 梯度下降法适用于各种类型的模型,正规方程只适用于线性模型。
局部加权线性回归
参数学习算法:
有固定的有限个数的参数以用来进行数据拟合。拟合完成后不需要保留训练数据样本,只需要保留参数。
非参数学习算法:
参数个数随着数据集规模增长而线性增长。拟合完成后仍需要一直保留整个训练集。
局部加权线性回归:
是一个非参数算法,通过引入权值,与测试样本 x 越近的样本点能得到更高的权值,而较远的样本点权值很小。
原始的线性回归算法中,衡量 h(x) 的步骤如下:
- 使用参数 θ 进行拟合,让数据集中的值与拟合算出的值的差值平方 ∑i(y(i)-θTx(i))2 最小(最小二乘法的思想)
- 输出 θTx
在 LWR 局部加权线性回归中,衡量 h(x) 的步骤如下: - 使用参数 θ 进行拟合,让数据集中的值与拟合算出的值的差值平方 ∑iw(i)(y(i)-θTx(i))2 最小
- 输出 θTx
w(i) 的选取利用以下公式:

如果 |x(i)-x| 非常小,则 w(i) 接近于 1 ;如果 |x(i)-x| 非常大,则 w(i) 接近于 0 。因此,对于 θ 的选择,查询点 x 附近的训练样本有更高的权值。
随着点 x(i) 到查询点 x 的距离变化,参数 τ (又称带宽参数)控制变化的速度。
分类与逻辑回归
加权最小二乘法
……待完善
逻辑回归
分类问题:
预测的变量 y 局限于若干个离散值。
逻辑回归算法:
是一种分类算法,输出值永远在 0 到 1 之间,适用于标签 y 取值离散的情况。
逻辑回归模型的假设:(X 代表特征向量,g 代表逻辑函数)
Sigmoid 函数/逻辑函数的公式为:
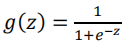
函数图像为:
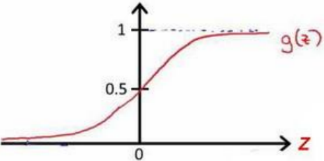
hθ(x) 的作用:
对于给定的输入变量,根据选择的参数计算输出变量 =1 的可能性,即 hθ(x) = P(y=1 | x;θ)
θ 的似然函数:
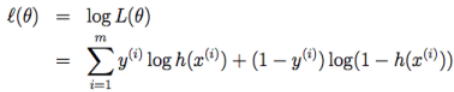
用梯度上升法求 θ 的公式:
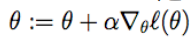
逻辑回归模型的代价函数:
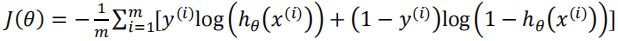
注:该代价函数一定是凸函数,没有局部最优值。
逻辑回归和线性回归的比较:
1)两者都是广义的线性回归
2)线性回归在整个实数域范围内,用于预测;逻辑回归将预测值限定在 [0,1] 之间,用于分类。
3)线性回归的目标函数是最小二乘,逻辑回归的目标函数是似然函数,使用了 Sigmoid 函数使其值落在 [0,1] 之间。
4)线性回归要求因变量是连续性变量,逻辑回归要求因变量是分类型变量。
5)线性回归是直接分析因变量和自变量的关系,逻辑回归是分析因变量取某个值的概率和自变量的关系。
牛顿法
牛顿法求方程零点:
用一个线性函数(f 的切线)对函数 f 进行逼近,通过逐次迭代得到方差的解。

牛顿法理论依据:求 L(θ) 的最大值即求其导数 L’(θ) 等于零的点。
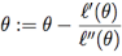
注:如果用牛顿法求一个函数的最小值而不是最大值,则求其法线的零点。?????……
扩展到多变量问题,牛顿-拉普森法:
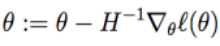
H 是一个 n*n 的 Hessian 矩阵,定义为:
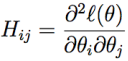
牛顿法和梯度下降法的分析:
1)牛顿法:通过求解目标函数的一阶导数为 0 的参数从而求出该函数最小值时的参数。
优点:
a. 二阶收敛,收敛速度快
b. Hessian 矩阵的逆在迭代过程中不断减小,起到逐步减小步长的作用
缺点:
是一种迭代算法,每一步都需要求解目标函数的 Hessian 矩阵的逆矩阵,计算量较大。
2)梯度下降法:通过梯度方向和步长直接求解目标函数最小值时的参数。
优点:
实现简单,当目标函数是凸函数时得到全局最优解。
缺点:
靠近极小值时收敛速度减慢,求解需要很多次迭代。
3)比较
a. 牛顿法是二阶收敛,梯度下降是一阶收敛,故牛顿法收敛得更快
b. 两者都是迭代求解,梯度下降法是梯度求解,牛顿法是利用 Hessian 矩阵的逆矩阵求解
c. 牛顿法比梯度下降法求解需要的迭代次数更少,但单次迭代的时间更长,因为要查找和转换一个 n*n 的 Hessian 矩阵
d. 当 n 特别大时应使用梯度下降法,n 较小时一般使用牛顿法
感知器算法
……待完善
广义线性模型
指数族
如果一个分布能用下面的方式写出来,则这类分布属于指数族:

当给定 T、a、b 时,就定义了一个用 ŋ 进行参数化的分布族,通过改变 ŋ 可以得到这个分布族中的不同分布。
构建广义线性模型
构建广义线性模型时需要对模型做以下三个假设:
假设 1:给定的 x、θ、y 的分布属于指数分布族,P(y;θ) = b(y) exp(ηTT(y) - a(η)) 。
假设 2:h 输出的预测值 h(x) 满足 h(x)=E[y|x] (E[y|x] 即对给定 x 时的 y 值的期望)
假设 3:自然参数 η 和输入值 x 是线性相关的,η=θTx,若 η 是有值的向量则 ηi=θiTx 。
生成学习算法
判别学习算法:
直接学习 p(y|x) ,通过输入特征空间 x 去确定其所在的区域,如线性回归、逻辑回归、感知器算法等都属于判别学习算法。
生成学习算法:
不直接对 p(y|x) 建模,而是通过对 p(x|y) 和 p(y) 建模,将输入 x 和每个分类的模型进行比对,比较哪个模型更接近。
使用贝叶斯规则将学习到的 p(x|y) 和 p(y) 转换为 p(y|x) 进行预测。

高斯判别分析
假设有一个分类问题,输入特征 x 是一系列的连续随机变量,则可以用高斯判别分析(GDA),其中对 p(x|y) 用多元正态分布进行建模,模型为:
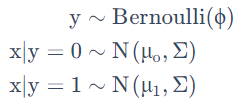
分布写出来的具体形式为:

取对数的似然函数,使其最大,找到对应的参数组合,如下:

图形化表达如下:

图中的两个高斯分布就是针对两类数据各自进行的拟合,有同样的形状和拉伸方向。(同样的协方差矩阵 Σ ,不同的均值 μ0 和 μ1)
高斯判别分析和逻辑回归的关系:
1)如果 p(x|y) 是一个多变量的高斯分布(具有一个共享的协方差矩阵 Σ),则 p(y|x) 必然符合逻辑回归函数。反之,则不成立。
2)高斯判别模型能比逻辑回归对数据进行更强的建模和假设,在两种模型假设都可用时,高斯判别分析法拟合数据更好,尤其当确定 p(x|y) 是一个高斯分布则高斯判别分析是渐进有效的。
3)逻辑回归建立的假设更弱,对于偏离的模型假设来说更加鲁棒。如果训练数据为非高斯分布且是有限的大规模数据,则逻辑回归相比高斯判别分析更好。
4)实际中逻辑回归的使用频率比高斯判别分析高得多。
朴素贝叶斯法
朴素贝叶斯法:
利用贝叶斯公式根据某对象的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该对象所属的类。
朴素贝叶斯假设:
假设特征变量 xi 对于给定的 y 是独立的,是条件独立,不是特征独立。
注:高斯判别分析中特征向量是连续的,朴素贝叶斯法中特征向量是离散的。当原生的连续值的属性不太容易用一个多元正态分布进行建模时,可以将其特征转换成一个离散值的集合,再使用朴素贝叶斯法替代高斯判别分析法,通常能形成一个更好的分类器。
拉普拉斯平滑:
为了解决朴素贝叶斯法中的零概率问题,引入拉普拉斯平滑,对每个类别所有划分的计数加 1 ,即最大似然估计公式改为:
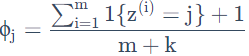















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









