







在当今的现实生活中存在着很多种微信息量的数据,如何采集这些数据中的信息并进行利用,成了数据分析领域里一个新的研究热点。随机森林以它自身固有的特点和优良的分类效果在众多的机器学习算法中脱颖而出。
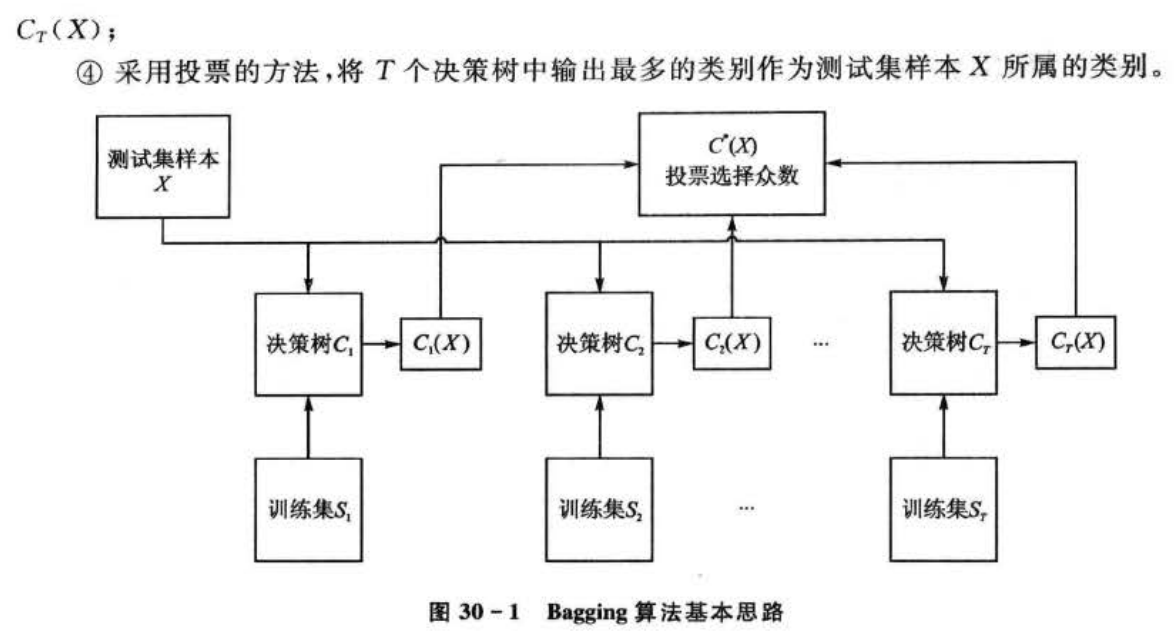
随机森林算法由Leo Breiman和 Adele Cutler提出,该算法结合了Breimans的“Boot-strap aggregating”思想和Ho的“"random subspace”方法。其实质是一个包含多个决策树的分类器,这些决策树的形成采用了随机的方法,因此也叫做随机决策树,随机森林中的树之间是没有关联的。当测试数据进人随机森林时,其实就是让每一棵决策树进行分类,最后取所有决策树中分类结果最多的那类为最终的结果。因此随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
本博客将详细介绍随机森林的思想与算法原理,并结合实例讲解随机森林算法的MATLAB实现。
1 案例背景
1.1随机森林概述


 1.2问题描述
1.2问题描述
威斯康辛大学医学院经过多年的收集和整理,建立了一个乳腺肿瘤病灶组织的细胞核显微图像数据库。数据库中包含了细胞核图像的10个量化特征(细胞核半径,质地,周长、面积、光滑性、紧密度、凹陷度、凹陷点数、对称度、断裂度),这些特征与肿瘤的性质有密切的关系。因此,需要建立一个确定的模型来描述数据库中各个量化特征与肿瘤性质的关系,从而可以根据细胞核显微图像的量化特征诊断乳腺肿瘤是良性还是恶性的。
2 模型建立
2.1 设计思路
将乳腺肿瘤病灶组织的细胞核显微图像的10个量化特征作为模型的输人﹐良性乳腺肿瘤和恶性乳腺肿瘤作为模型的输出。用训练集数据进行随机森林分类器的创建,然后对测试集数据进行仿真测试,最后对测试结果进行分析。
2.2设计步骤
根据上述设计思路,设计步骤主要包括以下几个部分,如图30-2所示。
 1.数据采集
1.数据采集
数据来源于威斯康辛大学医学院的乳腺癌数据集,共包括569个病例,其中,良性357例,恶性212例。本书随机选取500组数据作为训练集,剩余69组作为测试集。
每个病例的一组数据包括采样组织中各细胞核的这10个特征量的平均值、标准差和最坏值(各特征的3个最大数据的平均值)共30个数据。数据文件中每组数据共分32个字段:第1个字段为病例编号;第2个字段为确诊结果,B为良性,M为恶性;第3~12个字段是该病例肿瘤病灶组织的各细胞核显微图像的10个量化特征的平均值;第13~22个字段是相应的标准差;第23~32个字段是相应的最坏值。
2.随机森林分类器创建
数据采集完成后,利用随机森林工具箱函数classRF_train(),即可基于训练集数据创建个随机森林分类器,该函数的具体用法将在下一节中详细介绍。
3、仿真测试
随机森林分类器创建好后,利用随机森林工具箱函数classRF_predict(),即可对测试集数据进行仿真预测,该函数的具体用法将在下一节中详细介绍。
4.结果分析
通过对随机森林分类器的仿真结果进行分析,可以得到误诊率(包括良性被误诊为恶性、恶性被误诊为良性),从而可以对该方法的可行性进行评价。同时,也可以与其他方法进行比较,探讨该方法的有效性。
3 随机森林工具箱
MATLAB自带的工具箱中没有随机森林工具箱,此处采用Abhishek Jaiantilal开发的randomforest-matlab开源工具箱(下载地址: https://code.google.com/p/randomforest-matlab/)。下面将详细介绍该工具箱中的一些重要函数的调用格式及使用注意事项。
3.1 随机森林分类
函数classRF_train()用于创建一个随机森林分类器,其调用格式为:
model = classRF_train(X,Y,ntree,mtry, extra options)
其中,X为训练集的输人样本矩阵,其每一列表示一个变量(属性),其每一行表示一个样本;Y为训练集的输出样本向量,其每一行表示X中对应的样本所属的类别;ntree为随机森林中决策树的个数(默认值为500);mtry为分裂属性集中的属性个数(默认值m=LVMj,M为总的属性个数,符号L·表示向下取整);extra_options为可选的参数; model为创建好的随机森林分类器。
3.2随机森林分类器仿真预测函数
函数classRF_predict()用于利用创建好的随机森林分类器进行仿真预测,其调用格式为:
[Y_hat votes] =classRF_predict(x, model,extra_options)
其中,X为待预测样本的输入矩阵,其每一列表示一个变量(属性),其每一行表示一个样本;model为创建好的随机森林分类器;extra_options为可选的参数;Y_hat为待预测样本对应的所属类别;votes为未格式化的待预测样本输出类别权重,即将待预测样本预测为各个类别的决策树个数。
4 完整matlab代码
主函数如下:
%% 基于随机森林思想的组合分类器设计
%% 清空环境变量
clear all
clc
warning off
%% 导入数据
load data.mat
% 随机产生训练集/测试集
a = randperm(569);
Train = data(a(1:500),:);
Test = data(a(501:end),:);
% 训练数据
P_train = Train(:,3:end);
T_train = Train(:,2);
% 测试数据
P_test = Test(:,3:end);
T_test = Test(:,2);
%% 创建随机森林分类器
model = classRF_train(P_train,T_train);
%% 仿真测试
[T_sim,votes] = classRF_predict(P_test,model);
%% 结果分析
count_B = length(find(T_train == 1));
count_M = length(find(T_train == 2));
total_B = length(find(data(:,2) == 1));
total_M = length(find(data(:,2) == 2));
number_B = length(find(T_test == 1));
number_M = length(find(T_test == 2));
number_B_sim = length(find(T_sim == 1 & T_test == 1));
number_M_sim = length(find(T_sim == 2 & T_test == 2));
disp(['病例总数:' num2str(569)...
' 良性:' num2str(total_B)...
' 恶性:' num2str(total_M)]);
disp(['训练集病例总数:' num2str(500)...
' 良性:' num2str(count_B)...
' 恶性:' num2str(count_M)]);
disp(['测试集病例总数:' num2str(69)...
' 良性:' num2str(number_B)...
' 恶性:' num2str(number_M)]);
disp(['良性乳腺肿瘤确诊:' num2str(number_B_sim)...
' 误诊:' num2str(number_B - number_B_sim)...
' 确诊率p1=' num2str(number_B_sim/number_B*100) '%']);
disp(['恶性乳腺肿瘤确诊:' num2str(number_M_sim)...
' 误诊:' num2str(number_M - number_M_sim)...
' 确诊率p2=' num2str(number_M_sim/number_M*100) '%']);
%% 绘图
figure
index = find(T_sim ~= T_test);
plot(votes(index,1),votes(index,2),'r*')
hold on
index = find(T_sim == T_test);
plot(votes(index,1),votes(index,2),'bo')
hold on
legend('错误分类样本','正确分类样本')
plot(0:500,500:-1:0,'r-.')
hold on
plot(0:500,0:500,'r-.')
hold on
line([100 400 400 100 100],[100 100 400 400 100])
xlabel('输出为类别1的决策树棵数')
ylabel('输出为类别2的决策树棵数')
title('随机森林分类器性能分析')
%% 随机森林中决策树棵数对性能的影响
Accuracy = zeros(1,20);
for i = 50:50:1000
i
%每种情况,运行100次,取平均值
accuracy = zeros(1,100);
for k = 1:100
% 创建随机森林
model = classRF_train(P_train,T_train,i);
% 仿真测试
T_sim = classRF_predict(P_test,model);
accuracy(k) = length(find(T_sim == T_test)) / length(T_test);
end
Accuracy(i/50) = mean(accuracy);
end
% 绘图
figure
plot(50:50:1000,Accuracy)
xlabel('随机森林中决策树棵数')
ylabel('分类正确率')
title('随机森林中决策树棵数对性能的影响')运行结果:
病例总数:569良性:357恶性:212
训练集病例总数:500良性:312恶性:188测试集病例总数:69良性:45恶性:24
良性乳腺肿瘤确诊:45误诊:0确诊率p1 =100 %
恶性乳腺肿瘤确诊:23 误诊:1确诊率p2 = 95.8333%从结果中可以看出,在测试集的69个样本中,共有1个样本被预测错误,1个恶性乳腺肿瘤样本被错分为良性乳腺肿瘤),平均确诊率为98.55%(68/69)。这表明随机森林用于分类及模式识别问题中具有较好的性能。


















 3281
3281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











