










系列文章目录
- 【Domain Generalization(1)】增量学习/在线学习/持续学习/迁移学习/多任务学习/元学习/领域适应/领域泛化概念理解
- 第一篇了解了 DG 的概念,那么接下来将介绍 DG 近年在文生图任务中、或运用了文生图模型的相关工作。
- 【Domain Generalization(2)】领域泛化在文生图领域的工作之——PromptStyler(ICCV23)
- 【Domain Generalization(3)】领域泛化与文生图之 – QUOTA 任意领域生成物体的数量可控
- 【Domain Generalization(4)】领域泛化与文生图之 – CDGA 跨域生成式数据增强 Cross Domain Generative Augmentation
文章目录
快速讲清楚
- 任务依然是 Image Classification 之类的识别任务,重点是用 LDM 来做数据增强。
- 解决的问题:现有的基于扩散模型(LDMs)的DG方法仅限于,使用LDM进行离线增强,性能下降以及高昂的计算成本。
- 为了应对这些挑战,作者提出 DomainFusion 同时实现在潜在空间中提取知识和在像素空间中的增强扩散模型,用于有效和充分地利用 LDM。
- 开发了一个潜在蒸馏模块,用于蒸馏梯度先验,从LDM到指导DG模型的优化。
- 此外,设计了一种在线轻量级增强方法(inversion / SD 的 img2img pipeline),将候选图像分解为样式和内容,以快速、在线地使用LDM。
- 实验结果表明,DomainFusion 的性能优于基于扩散的方法大幅提高了效率,并在现有的DG基准数据集上实现了SOTA性能。值得注意的是,DomainFusion 可以显著减少生成的图像数量(例如,在 DomainNet 上减少超过97%),而无需微调LDM。
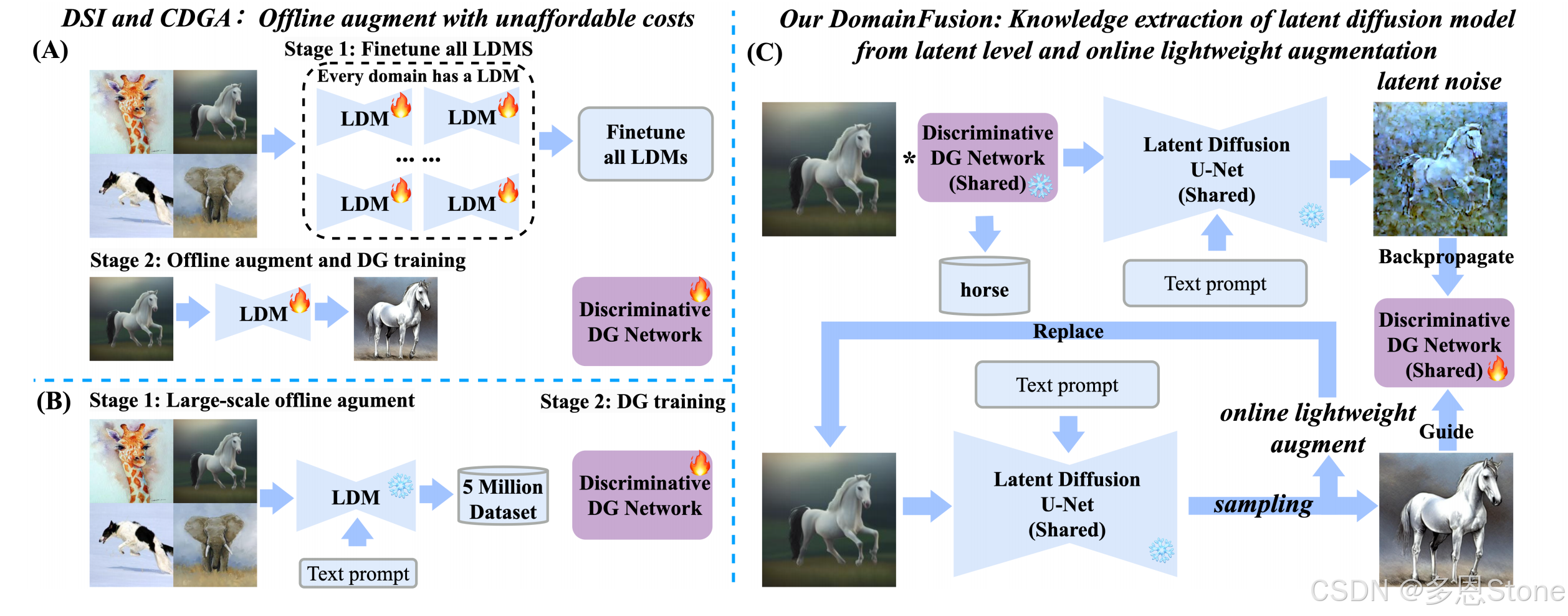
背景
上图中很好地解释了现有方法的具体问题:
-
(A) DSI [68] 为每个源域使用了一个单独的LDM,并且需要在增强之前对所有的LDM进行微调。
-
(B) CDGA [17] 离线生成超过500万张合成图像用于增强 ,导致计算成本显著,导致生成时间延长,并显著增加了DG模型的训练时间。
-
(C ) 提出的 DomainFusion。
- 作者认为 LDM 的潜在空间中包含了有利于 DG 的视觉知识,因此,引入潜在蒸馏法从潜在空间中提取知识来指导DG模型。
- 为了降低计算成本,提出了一种在线轻量级增强方法通过一种采样策略(如图4所示),该策略显著减少了使用的生成的样本数量(例如,在DomainNet上生成的总体图像数量减少了97%以上) 只有一个共享的LDM,没有任何微调。
在AI模型训练中,“offline”(离线)和“online”(在线)有明显的区别:
离线训练(offline training)-> 传统的模型训练流程
- 数据处理:在训练开始前,会将所有用于训练的数据一次性准备好,这些数据存储在固定的存储位置,比如硬盘等。模型训练过程中使用的就是这些预先准备好的数据,不会在训练过程中实时获取新数据。
- 计算资源使用:通常需要较大的计算资源和存储资源,因为要一次性处理大量数据。例如图中提到的大规模离线增强(Large - scale offline augment),需要利用大量数据构建500万数据集等操作。
- 训练过程:训练过程相对独立,不受实时数据变化的影响,训练完成后模型参数固定,后续使用时直接加载模型进行推理等操作。比如图中DSI和CDGA方法的离线增强阶段,先对所有潜在扩散模型(LDM)进行微调,再进行离线增强和域生成(DG)训练 。
在线训练(online training)-> 在线部署的模型,根据场景进一步优化
- 数据处理:数据不是一次性准备好,而是在训练过程中逐步获取和处理新数据。模型可以根据新输入的数据实时更新自身的参数。
- 计算资源使用:通常对计算资源的要求相对灵活,不需要一次性存储和处理大量数据,适合数据不断产生的场景。如图中提到的在线轻量级增强(online lightweight augment),在训练过程中根据需要进行数据增强操作。
- 训练过程:模型处于动态更新状态,能够快速适应数据分布的变化。例如在 DomainFusion方法里,在潜在扩散模型的潜在层面进行知识提取,结合在线轻量级增强,在采样等过程中利用判别性域生成网络(Discriminative DG Network)实时引导和更新模型。
动机
- 大量的计算成本:
- CDGA [17]生成了大量超过500万张合成图像用于数据增强。5M 数据需要过多的计算费用和生成时间,在 5M 数据上训也增加了训练成本。
- DSI [68]在计算成本上非常高,因为它为每个源域使用一个LDM,因此需要分别对每个LDM进行微调。
- 没有充分利用LDM的能力:
- LDM的潜在空间包含有价值的预训练视觉知识,可以用于下游感知任务,如图像分割[57] 和 目标检测[8]。
- 考虑到 LDM 能够在不影响底层语义的情况下进行跨不同领域的图像变换,作者合理地认为 LDM 的潜在空间学习了丰富的关于域不变(domain-invariant)的特征表示知识,显示了DG任务的显著潜力。
具体做法
- 针对 LDM 的利用效率低,利用率不足:
- 通过在线轻量级生成来增强像素空间,
- 潜蒸馏 (Latent Distillation) 从 LDM 潜在空间中的知识提取。
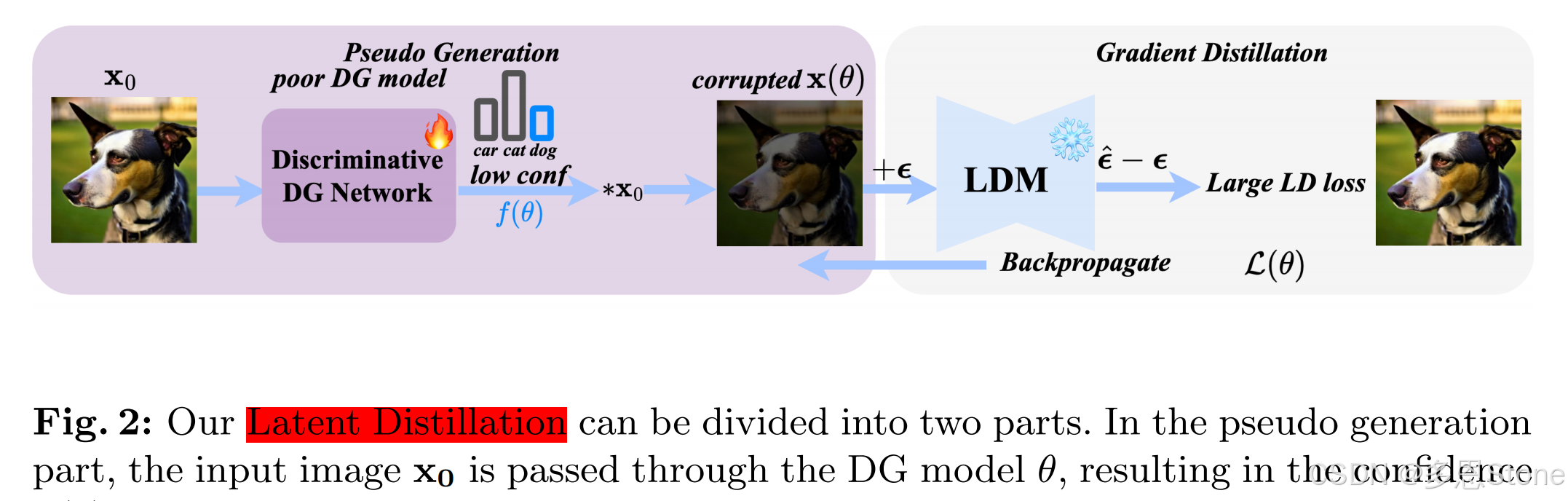
- Latent Distillation:
- 在伪标签生成 (pseudo generation) 部分,输入图像 x 0 x_0 x0 通过DG模型 θ θ θ,得到对应类的置信度 f ( θ ) f(θ) f(θ)。然后将输入图像 x 0 x_0 x0 乘以这个机密信息 以获取一个损坏的图像 x ( θ ) x(θ) x(θ)。
- 在梯度蒸馏(gradient distillation) 部分,将噪声 ϵ ϵ ϵ 添加到损坏(降低对比度)的图像 f ( θ ) f(θ) f(θ) 中,然后送入LDM。LDM预测噪声为 ϵ ^ \hat{ϵ} ϵ^。
- 然后,基于 ϵ ^ − ϵ \hat{ϵ}-ϵ ϵ^−ϵ 计算潜在蒸馏 (LD)损失。由于 LD 损失依赖于 θ θ θ,因此可以执行反向传播来更新DG模型 θ θ θ。
- 从直观的角度来看,当DG模型表现不佳时,它往往会产生低置信度,导致损坏的图像变得明显更暗。
- 因此,LDM需要重新开始构建大量的细节,导致巨大的LD损失,从而指导DG模型的更新。
- 通过不断重复循环,DG模型逐渐发展了对各个域的鲁棒理解。
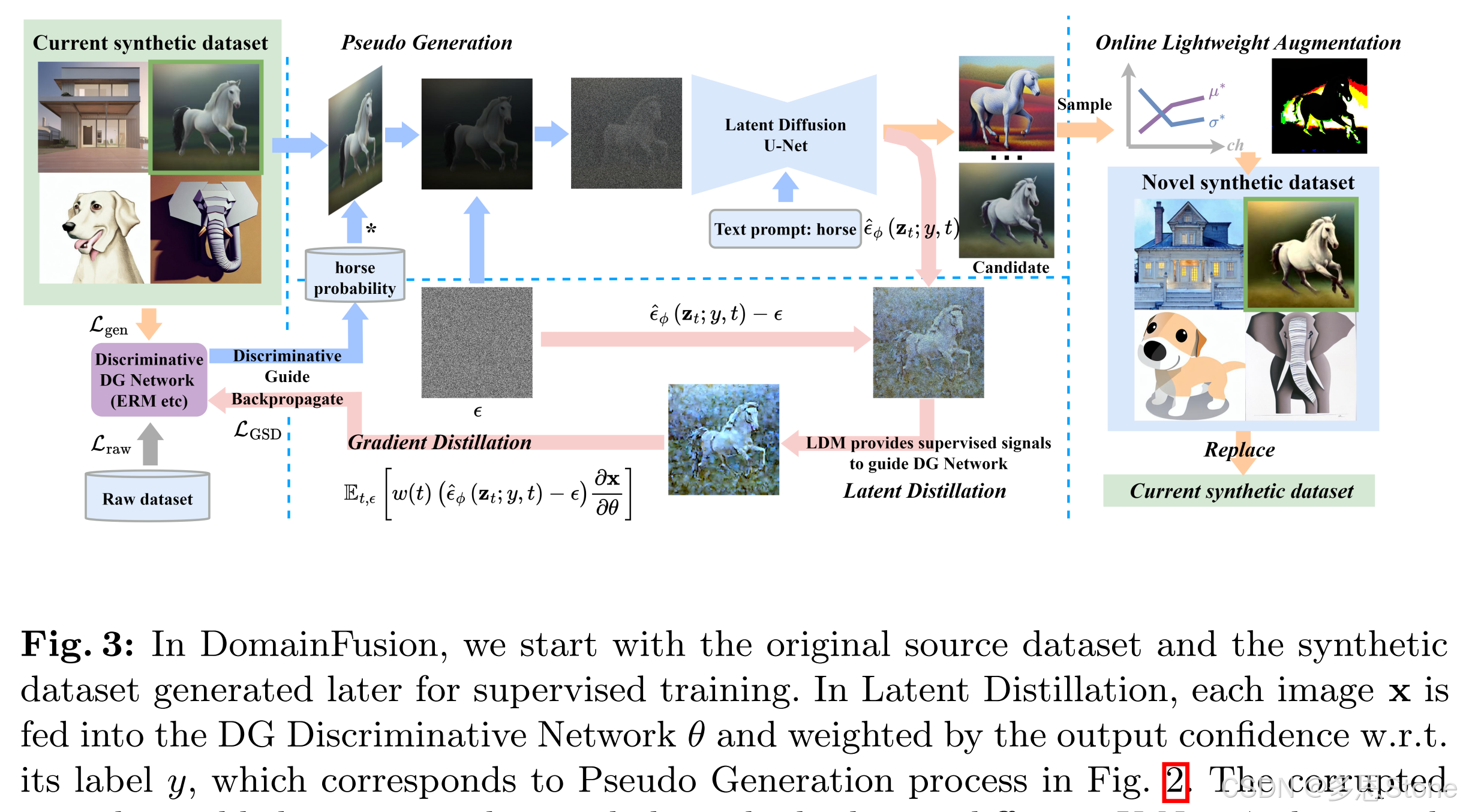
- 在域融合 (DomainFusion) 中,从用于监督训练的原始源数据集 (Raw dataset) 和稍后生成的合成数据集 (Current synthetic dataset) 开始。
- 在潜在蒸馏中,
- 伪生成:每个图像 x x x 都被输入 DG 鉴别网络 θ θ θ,并通过输出关于其标签 y y y 的置信度进行加权,对应于图 2 中的伪生成过程。
- 梯度蒸馏:已损坏的 x x x 然后添加了噪声 ϵ ϵ ϵ 并与 y y y 作为 prompt,一起进入潜在扩散 U-Net ϕ \phi ϕ,产生预测噪声 ϵ ϕ ^ ( z ^ t ; y , t ) \hat{ϵ_\phi}(\hat{z}_t; y,t) ϵϕ^(z^t;y,t) 。使用预测噪声和实际噪声之间的 [ ϵ ϕ ^ ( z ^ t ; y ; t ) − ϵ ] [\hat{ϵ_\phi}(\hat{z}_t; y ; t) -ϵ] [ϵϕ^(z^t;y;t)−ϵ] 来获取 L L D L_{LD} LLD,它通过反向传播更新 θ \theta θ 的参数空间,对应于图2中的梯度蒸馏。
- 在线轻量级增强中,每个图像
x
x
x 在当前的合成数据集中,通过 LDM 生成
N
N
N 个候选数据。通过抽样策略,将候选对象分解为风格和内容,然后选择最不同的风格和最相似的内容对一个新的图像进行采样,然后替换当前合成数据集中的
x
x
x,形成一个新的合成数据集。
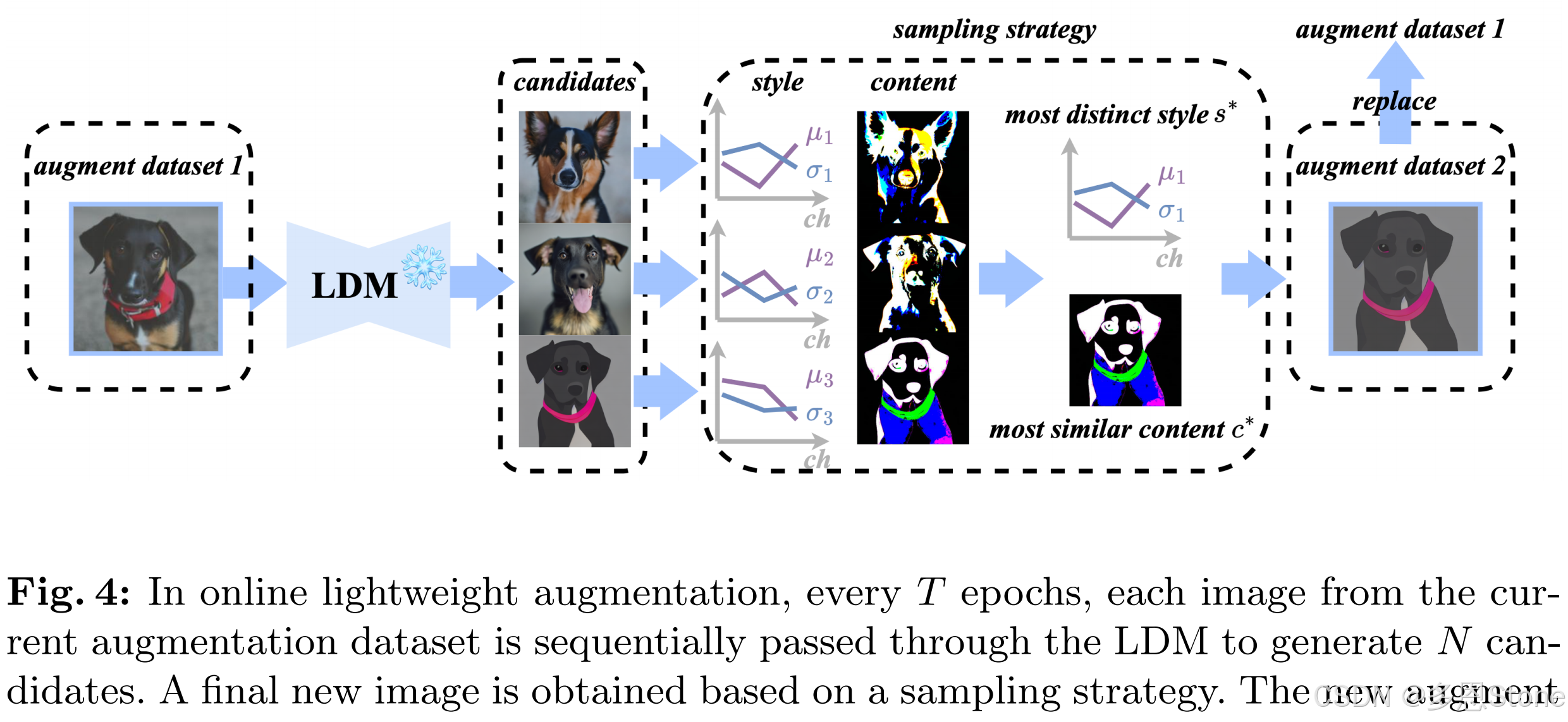
- online lightweight augmentation
- 每一个 T 个 epochs,当前增强数据集中的每幅图像依次通过 LDM 生成 N 个候选图像。
- 基于采样策略,得到了一张最终的新图像。
- 由这些新的被挑选的图像组成的增强数据集,替换当前的增强数据集。
- 具体来说,抽样策略是计算每个候选对象的风格和内容。
- 然后选择与输入图像风格最不同的风格 s ∗ s^∗ s∗ 和与输入图像内容最相似的内容 c ∗ c^∗ c∗。
- 这些风格和内容组件然后是组合到一起形成最终的新图片。
- 每一个 T 个 epochs,当前增强数据集中的每幅图像依次通过 LDM 生成 N 个候选图像。
图 4 中的 style 和 content 进行分解的方法来自于 MODE (ICML2023)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









