






U1C1 Background and practical applications of data mining and text analytics
一、机器学习 与 数据挖掘 (Machine learning / Data mining)
1、机器学习
Machine learning:focus on ML algorithms, optimal accuracy
机器学习:针对于算法(algorithms),一般会尝试使用多种机器学习算法,通过使用训练集(train dataset)与测试集(test dataset)测量准确率(accuracy) 来选择最优的算法。
2、数据挖掘
Data Mining:applied ML, with a focus on:
- ML as part of a toolkit to tackle practical problems
- Data collection, understanding, annotation, “wrangling”
- “Data analysts typically spend the majority of their time in the process of data wrangling compared to the actual analysis of the data” - wikipedia
- CRISP-DM。“modelling”(DL) is only one of 6 phases.
数据挖掘:更注重将机器学习应用于实际任务(practical tasks)去解决那些你预先不知道的现实任务。
你可能不知道该任务是用什么数据,你需要去收集,你需要去理解它的含义,如果你在做一个分类,甚至可能要对每个数据实例都用类来注释标记。
其次,在进行数据挖掘前,需要进行数据处理(data wrangling/ data manipulating),将数据转换成正确格式(right format) ,但这一直都是一个非常大的挑战:对大多数数据分析师来说,相比于使用数据进行分析,他们更会花费大量时间在数据处理上。
使用了CRISP-DM (Cross-industry standard process for data mining),数据挖掘的跨行业标准流程,是一个可以通过应用数据挖掘去解决实际问题的方法论(methodology)或者步骤(procedure),描述了数据挖掘专家使用的常用方法。它是使用最广泛的分析模型。具体见下一节。
二、数据挖掘的跨行业标准流程 CRISP-DM
Cross-industry standard process for data mining (Wikipedia)
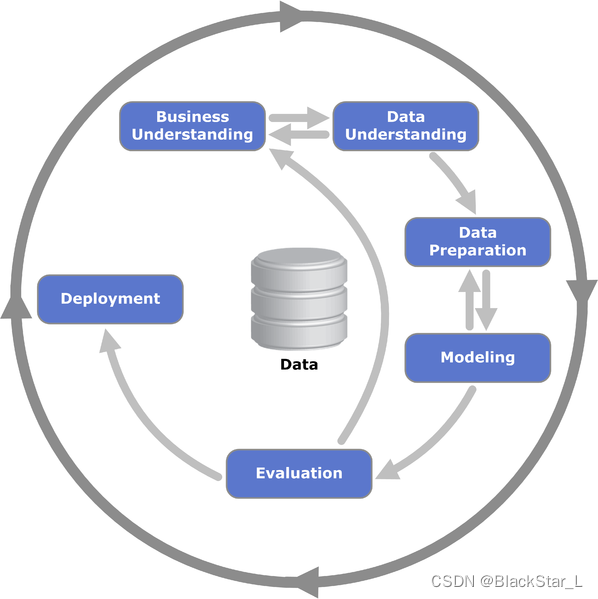
使用数据挖掘去解决实际问题的6个步骤:
1、商业理解 - Business Understanding
- Understanding project objectives and requirements
- Data mining problem definition
首先是商业理解,你需要询问你的委托人或者客户,我们的需求到底是什么,他们的目标是什么。他们可能会说,好吧,我想赚更多的钱,我想从这些数据中找到一种赚更多钱的方法。这是相当模糊的,你必须弄清楚什么是数据挖掘问题,你该如何定义。比如:一个实际的数据分类、机器学习分类器或机器学习聚类或其他类似的东西。
2、数据理解 - Data Understanding
- Initial data collection and familiarization
- Identify data quality issues
- Initial, obvious results
在确定了数据挖掘任务的具体内容之后,你就必须获得一些数据,并理解其中涉及的数据。
数据可能需要自己去收集,你可能会注意到数据中有重复,例如,如果你收集网页,那么有时候一个网页是另一个网页的直接副本,所以你可能不想两者都要,或者你的客户可能会给你一些数据,在这种情况下,你需要选择你想要的数据。
弄清楚数据的意思,如果你有一个包含行和列的电子表格,列上可能有一个名字,但这并不意味着你理解它是什么,比如:我收到了医疗病历数据集,但我不是医生或临床医生,所以我不太明白bpm或其他类似的意思。
要注释攻击性推文,或者如果你第一次收集推文,你可能会很快注意到大多数推文都不是攻击性的。所以你有一个扭曲的(skewed) 数据集,可能只有1%是令人不快的,99%不是令人不快的,这会给以后的分类带来问题。如果你有一个分类器,它只是简单地说它不是每次攻击性的,那么这将给你99%的准确率,但它实际上是无用的,因为它适用于任何攻击性推文。
3、数据准备 - Data Preparation
- Formating, record and attribute selection
- Data cleansing
弄明白了数据的含义之后,你就必须开始准备数据,使其成为worker、sketch引擎或Python程序的正确格式,因为它必须是程序可以接受的某种格式,这可能意味着决定哪些记录要包含哪些属性字段,等等。
这同时也涉及清理数据的问题,可能数据中有噪音,可能数据中缺少项目等等。
4、建模 - Modeling
- Run the data analysis and data mining tools
最后,你可以把它应用到机器学习中,你可以使用机器学习工具来运行数据分析和数据挖掘,在类似worker的应用程序中,您只需尝试几种不同的学习算法。
你不必了解它们是如何工作的,只需看看结果,看看哪一个是最准确的,或者在某种程度上是最好的,然后甚至可以将它们组合成一个整体,或者在某个地方运行所有分类,并平均或投票选出最好的。
5、评估 - Evalution
-
Determine if results meet business objectives
-
Identify business issues that should have been addressed earlier
评估并不是简单地决定哪一个获得了最高的准确度分数。
更重要的是,回到你的客户那里,询问我是否已经解决了你的问题?是否为你找到了一种方法让你赚更多的钱?如果他们说没有,那么也许,你就必须回到开始,从头开始做一遍,也许有些问题你应该早点解决,但你没有想到。
6、部署 - Deployment
-
Put the resulting models into practice
-
Set up for repeated/continuous mining of the data
然而,如果你的客户满意,那么你可以去部署,也就是把结果付诸实践,也许,给他们软件,分类器。
通常还要写一份报告,去说明你做了什么,对于一个真正的商业客户 (commercial customer),如果你不给他们一些可交付的东西(some deliverable),他们就不会给你钱,所以你必须这样做。
你也可以说我做得非常好,你的公司将从中受益,你应该每年做一次,每年邀请你回来,再给我5万美元,我会再为你做一次。
是的,所以这是数据挖掘的另一个重要方面,它不仅仅是你做一次的事情,而且如果这对业务有好处,你想一次又一次地做,也许一年一次。
三、文本分析 Text Analytics
Computational Linguistics / Natural Language Processing / Speech and Language Processing / Corpus Linguistics
- CL/NLP:focus on theory, algorithms
- TA:CL/NLP as part of a toolkit to tackle practical problems, and text data collection, understanding, annotation, wrangling
Text data(CORPUS) is mapped to number vectors for ML.
我的研究主要不是一般的数据挖掘,而是具体的文本分析数据挖掘包括数据库挖掘(database mining)和数值数据挖掘(numeric data mining)。文本就像文档和网页一样,当然要做的是,文本数据挖掘我们需要做的第一件事之一是将文本转换成数字向量(vectors of numbers),然后你的通用机器学习数据挖掘算法将在这方面发挥作用。
对于数据而言,文本分析是应用于文本的基本数据挖掘,然而,在行业术语中,通常首选文本分析,因为它听起来很花哨(sounds fancy)。
如果你在语言或语言学系(language or linguistics department),你可以称之为计算语言学(computational linguistics),这是一种使用计算的语言研究。
在计算部门通常被称为自然语言处理(natural language processing),因此它与计算机语言处理(computer language processing)(像Python或Java这样的编程语言)形成对比。
马丁的课本被称为语音和语言处理(speech and language processing),这是因为他们也要考虑口语( spoken language ),音频信号(audio signals) 与文本信号(text signals) 有很大的不同,我们不会去涉及那里。
在语言学领域,我说过计算语言学就是它的名字,但所有这些研究都涉及使用数据集(data set)。在语言学中,数据集被称为语料库(corpus),语料库是一个拉丁词集合体(a Latin word meeting body),语料库是一个文本体(a body of text.)。
所以计算语言学或自然语言处理或语料库语言学是一项涵盖理论和算法的学术研究,而文本分析是更商业化的实际问题解决方案,通过使用工具包,并应用它来看看它是如何工作的,这也往往包括收集数据、理解数据和注释数据等等问题。
关键的一点是,如果你想把机器学习和数据挖掘应用到文本中,文本数据语料库必须以某种方式被转换成数字向量,因为机器学习不能真正理解英语句子,但它可以处理数字向量,所以我们将在后面介绍如何做到这一点。
好的,最后我请你们看一看这本书《语言机器》,就像我说的,它实际上是一种杂志。
四、语言学:语言科学 - Linguistics:science of language
20多年前技术的历史,其中一些已经过时了,但实际上有很多通用的理论存储在那里,它着眼于技术、用户和预测的发展,所以你可以看到,实际上有一点仍然是一样的,那就是基础理论,所以 语言学(linguistics) 是对语言的研究,对语言的科学研究,我们也有一个语言学系。语言学被划分为子领域(sub fields),就像计算机被划分为子领域一样。
语音学(Phonetics): 从声学(acoustic)和生理学(physiological)角度研究语音产生(speech production)、感知(perception)和分析(analysis)的学科。
词典学(Lexicography): 研究一种语言中的单词(words)或词汇项目(vocabulary item),具有各自的(individual)意义(meaning)和语法功能(grammatical function)。研究不同类型的 标记(tokens) 、语言单位(units) 以及每个单词的 意义和功能( meaning and function) 。
句法(Syntax/Grammar): 研究一种或多种语言句子中单词(words)和语素(morphemes)的语法排列(grammatical arrangement)。即这些单词是如何组合成句子的。
语义学(Semantics): 研究语言中的意义(meaning)、词(words)和句子(sentences)之间的关系(relationship)及其意义(meanings)的学科。
当你写下单词或句子时,它们是字符串,但实际上它们也是意义,所以语义学是关于语言中的意义的研究,语义学是关于语言中的意义的。可能听说过编程语言语义,也就是编程语言的含义。
语用学(Pragmatics): 在实践中对语言的分析,考虑到语言使用的语境(the context of language use)。
它是关于语言如何被实际使用的功能,比如如果我妻子对我说我在这里很冷,这可能意味着点火,但这并不意味着我想让你知道我很冷。
话语建模(Discourse modelling): 对 话语(discourse)或对话(dialogue)中多个话语(utterance)的语言现象(linguistic phenomena)的分析。
比如人类经常相互交流,不仅仅是我说什么,你说什么,我说什么,你说什么,以至于有一个整体的结构,以减少虚假对话,其次在试图建模聊天机器人时,也有一个话语标记。
五、为什么开发文本分析?Why develop text analytics?
- Computer models of language
- Computerised language resources:corpus,dictionary,…
- Natural communication between people and computers
- Assisting communication between people: MT, social media
- Wealth creation:Goveronment and Industry interest
那么,你为什么要对文本分析感兴趣呢?如果你是一名学者,如果你是一名语言学研究人员,那么建立语言的计算机模型很有用,因为你有正式的语言学模型。
但如果你不是一名学者,那么为机器学习研究和其他类似的事情准备计算机化的词典文本数据集(computerized dictionaries text data)仍然很有用。
如果你是一个普通人,只是想使用电脑,那么它可能有助于人们在电脑中进行交流。我必须使用数十种不同的计算机接口来连接数十种不同的IT系统,我更希望能够与计算机对话或用普通英语打字。
即使你把社交媒体作为文本分析和it 的一大兴趣。例如,拥有庞大的文本分析研究实验室,因为他们希望能够分析社交媒体中的所有内容,这样他们就可以把广告告诉合适的人,如果你能个性化广告,人们会购买更多广告,广告商会为广告支付更多费用,因为文本分析在广告业中非常重要。对于像Facebook和谷歌这样的广告公司来说,你不认为谷歌是一家广告公司,但它的大部分收入来源于广告。
另一个原因是政府和行业对此感兴趣,这是财富创造,如果你有文本分析方面的专业知识,你将很容易获得高薪工作。但也许你毕业后,你可能想得到一份高薪的工作,如果你在几年后在文本分析行业找到一份工作,给我发一封电子邮件,让我知道你在做什么,我很感兴趣。
六、文本分析的挑战 - Challenges for text analytics
- expensive to compete:Google,Apple,Amazon, Microsoft
- different to elicit user requirements:users don’t know
- high customer expectations:“natural English language”
- not appropriate for some tasks, eg spreadsheets?
- we need tp rethink how we approach i/o, eg keyboards?
- we need training and time to learn to use new methods
- many applications involve all of the above
好吧,那么为什么文本分析很困难呢,一件事是,它需要大量的资源才能做好,所以我们稍后将讨论,例如,谷歌研究实验室开发的BERT。它需要非常大的计算机,有非常大的数据存储,能够存储、处理和机器学习数十亿个单词的文本,因此只有苹果、亚马逊、微软、谷歌、Facebook等公司有资源大规模地这样做。
我们在大学里可以做的是,这些投资者把注意力集中在小例子上,这就是我参与宗教文本研究的部分原因,因为像《圣经》和《古兰经》这样的宗教文本在谷歌上的规模相当小,但他们并不觉得有趣,因为他们不会赚那么多钱。
当然,当你使用素描引擎(sketch engine) 时,请注意,你有100万字的限制,你不能要求更多资源,所以我建议你开始建立一个50000单词的小语料库,不要一次或一次用完整个百万单词的引用,因为一旦你弄错了,我们将不得不重复几次,然后你会很快耗尽资源。
好的,文本分析的另一个问题是非常简单,很容易说我想说英语,但实际上很难具体说明系统必须做什么,用户不习惯,所以我们真的不知道如何指定自然语言界面的用户需求。另一方面,他们的期望值非常高,他们希望它能说一口流利的英语,或者输入流利的英语,所以当我们问聊天机器人一个问题时,它会以一个愚蠢或热情的回答来回复,所以我会感到恼火,因为我原以为机器人会很聪明会理解我的话,然后会回复一个恰当的回答。
而且,对于某些事情来说,这是不合适的,如果我有一个带有数字的电子表格,那么我必须保存这些数字,或者仅仅使用excel之类的电子表格听到这些数字,这对我来说有意义吗。
在任务中,如果我们目前正在使用其他下拉界面或键盘界面或其他东西,用英语交流是合适的,那么就需要重新设计界面,还需要培训和时间让人们学习如何使用这个新界面,尽管我会说英语,但对我来说,听写讲座直接输入转录系统是不自然的,我更习惯于打字。许多应用程序都涉及所有这些问题,甚至还有其他问题。
七、技术日历 - The Technology Calendar

- 2000年:屏幕上的视觉计算机人物
- 2003年:信息技术素养对任何就业都至关重要
- 2005年:与机器的全语音交互
- 2007年:家用机器人;小巧迷人
- 2012年,机器人几乎可以在家里或医院从事任何工作
- 2018年:人工智能模拟大脑的思维过程
- 2025年:思维识别i/o,人类学习被取代
- 2030年:通过连接人工智能提高人脑智能
参考
E Atwell. 1999. The language machine. British Council. (在本文中,你将了解更多关于数据挖掘、文本分析和语料库语言学的背景和实际应用)
Eric Atwell - Data Mining and Text Analytics
Jurafsky, D. and Martin, J. 2022 Speech and Language Processing 3rd ed.,Pearson
修改时间
2022/2/4

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









