






 SketchEngine是一个强大的文本分析和语料库语言学研究工具,提供单词素描、一致性分析、分布词库等功能。它允许用户从网络创建自定义语料库,进行术语提取和历时分析。WebBootCat工具用于从网页抓取语料,而平行语料库用于翻译研究。此外,SketchEngine还包括网络作为语料库的研究,如Leeds互联网语料库和ACLSIGWAC。该工具广泛应用于多种语言,支持术语对比和多词术语分析。
SketchEngine是一个强大的文本分析和语料库语言学研究工具,提供单词素描、一致性分析、分布词库等功能。它允许用户从网络创建自定义语料库,进行术语提取和历时分析。WebBootCat工具用于从网页抓取语料,而平行语料库用于翻译研究。此外,SketchEngine还包括网络作为语料库的研究,如Leeds互联网语料库和ACLSIGWAC。该工具广泛应用于多种语言,支持术语对比和多词术语分析。
U1C3 Introduction to SketchEngine and Web as Corpus research
这节课将会为你介绍:
- 素描引擎网络工具(SketchEngine web tool),它用作文本分析(text analytics)和语料库语言学研究(corpus linguistics research)
- 使用SkE中的WebBootCat 工具去从网络上收集你自己的语料库
- 如何使用SkE去从网上收集和分析文本数据
- 利兹互联网语料库(Leeds Internet Corpora)与种子词(seed-words) 大型语料库
- ACL SIGWAC:Association for Computational Linguistics Special Interest Group on Web as Corpus.以网络为语料库的计算语言学特殊兴趣小组协会。
额外阅读材料:
books:
The Sketch Engine ten years on
websites:
Sketch Engine overview (wikipedia)
SketchEngine (sketchengine)
Leeds Internet Corpora (leeds)
ACL SIGWAC (sigwac)
一、Sketch Engine
什么是Sketch Engine?它是一个网络工具,你需要登录注册去使用它。它是商业服务(commercial service),但对于利兹大学的研究者有免费的使用通道。
它有很多功能:
- 词语素描(Word sketch) - 单词搭配行为(collocational behaviour)的总结,即一个单词的下一个单词是什么。
- 一致性(Concordance) - 一致性是指特定单词、词根 或短语在语料库中反复出现,它会向你展示一些它在上下文中使用的例子。
- 分布词库(Distributional Thesaurus) - 显示将这个词的一致性与其他词的一致性进行比较-或其他词有相似的一致性。即一些词同时在相似的文章出现,它们则很可能具有相似的含义。
- 平行语料库(Parallel Corpus)——双语语料库,用于翻译举例。
- WebBootCat -从网页创建专门的语料库
- 术语(Terminology)-专业术语中的关键词和多词术语
- 等等
二、单词素描 - word sketch
word sketch - summary of a word’s collocational behaviour
下图是来自 Adam Kilgarriff 的论文中的实例
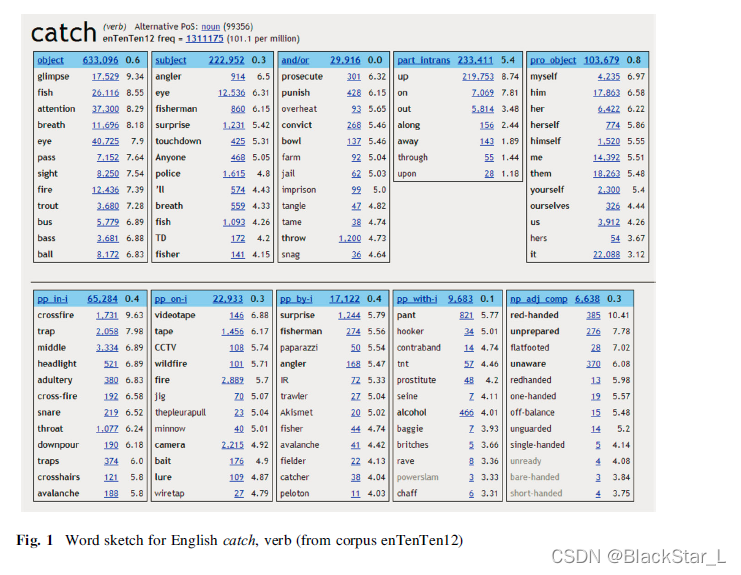
这是单词 catch 的单词素描(word sketch)。这里显示了单词catch前后可能出现的单词,所以显示了与catch有搭配行为的单词总和。
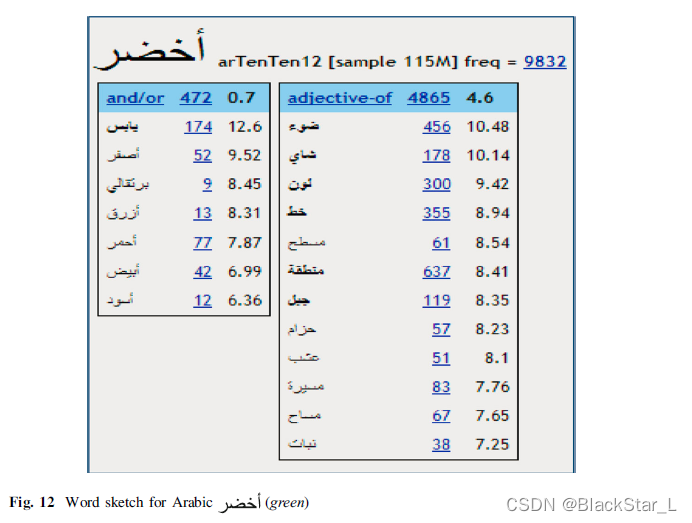
不仅仅应用于英语,其他语言也可以,比下面的如阿拉伯语:
同样也能找到该阿拉伯语前后可能出现的阿拉伯单词
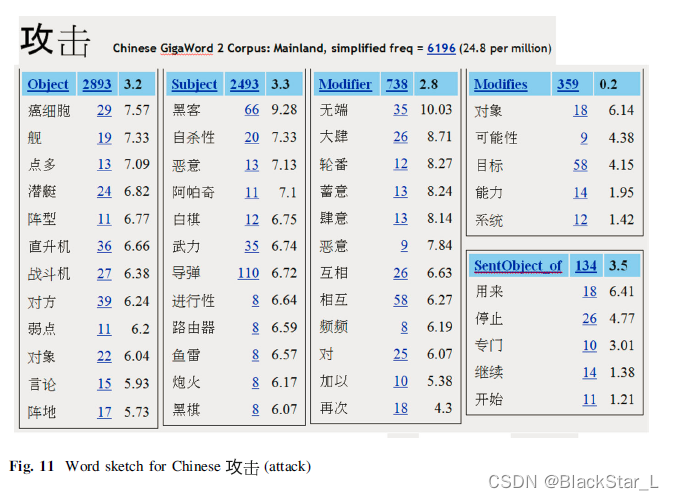
中文也一样,在Sketch Engine内部有一个Gigaword 语料库,通过WebBootCat从网络中收集大约10亿的中文词汇。这种收集方法也和其他语言一样,来创建语料库。
三、一致性 - Concordance
Concordance - examples of a word, lemma, phrase in context.
这是一个关于一致性的例子。所以对于一个特殊的单词或者短语,你能从语料库中得到很多例句,所以你能明白这些单词或者短语的意思。
caught with someone’s pants down 意思是被别人发现自己有损形象的事情。

四、分布词库 - Distributional Thesaurus
Distributional Thesaurus - words with similar meaning / context
在语料库中,查看单词 tea 的集合,还可以查看到 coffee 有着相似的模式分布,所以我们说 coffee 和 tea 可能有着相似的意思。

我们还可以得到一些其他的例子,像 drink,juice,chocolate,wine等等。当你顺着清单往下看,你会得到更少的相似度(score)。
五、平行语料库 - Parallel corpus
Parallel corpus - bilingual corpus for translation examples
如果你有一个中文语料库,并且翻译成了英文等等语言的语料库,那么这些语料称为平行语料库。
比如:OPUS 2 是Sketch Engine 内的一个语料库,然后我们有很多的文档,他们可以有英文的,中文的,以及其他语言的。
然后你从中文语料库中选择一个词“微笑”,相应的从英文语料库中选择这个词的翻译smile,然后你可以在英文句子中观察,出现在英文smile前后的单词,相应的可以对等到中文句子中。

六、 WebBootCat
WebBootCat - create corpus from web-pages
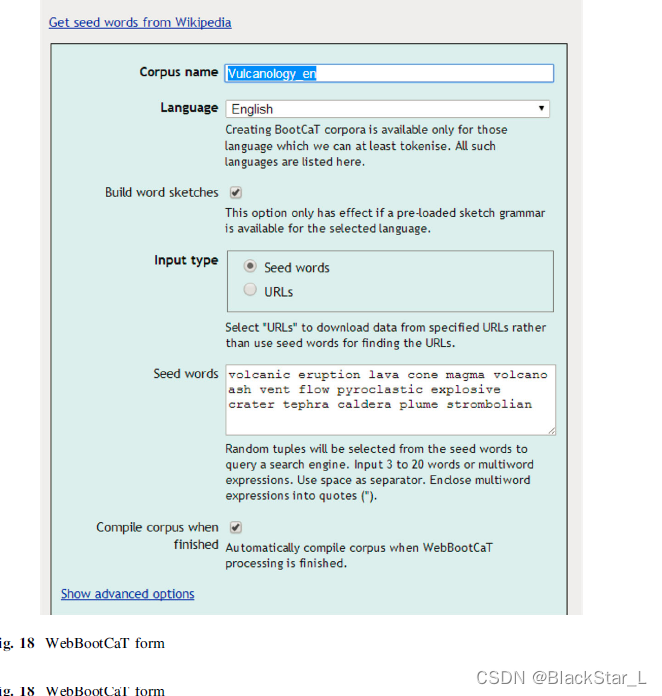
WebBootCat允许你从网页上创建一个语料库。下图节选于论文,在论文中,我们可以感觉到接口有轻微的不同,因为论文距今已经有很多年了,但是函数的功能还是一样的。正如我们下面看到的。
所以,你要创建一个语料库通过选择一个名字,选择一种语言,选择各种不同的参数。然后你还要给出 URLs,但是我们事先不知道选择什么URLs,但是我们可以选择一个种子单词(seed words)清单。种子单词是你认为你将要使用的主题,包括单词、短语或者一切其他的各种参数。
七、术语 - Terminology
Terminology - key words and multi-word terms in a specialism
在获得了你的语料库之后,我们就开始术语提取。
这一步要做的是,将你的语料库与标准英语语料库进行对比,例如:英国国家语料库 (The British National Corpus)。在你的语料库中寻找比标准语料库更频繁的单词。例如,我们有一个火山学语料库 (volcanology corpus)中的一些描绘火山的单词,这些单词和标准语料库相比更频繁。

八、SketchEngine 的其他功能
单词表(Word lists) - 使用用户标准(user criteria)过滤的频率列表(frequency lists),即你的语料库与标准语料库相比的频率
n-grams - 多单词(multi-word) 表达的频率列表
搭配(Collocations) - 词同现分析(word co-occurrence analysis)
单词素描差异(Word sketch difference) - 根据搭配比较两个单词
历时分析(趋势)(Diachronic analysis(Trends) )- 词语的用法随着时间的推移而改变,比如某个词mouse在以前和现在的含义不同。
许多语言中的 词性标注(Part-of-Speech tagging,名词动词等) 和 词根化(lemmatization dogs = dog + s)
九、网络作为语料库的研究 - Web as Corpus research
- 使用 SkE 从网上去收集和分析文本数据
- Leeds Internet Corpora with seed-words for a large corpus
- ACL SIGWAC:Association for Computational Linguistics Special Interest Group on Web as Corpus.以网络为语料库的计算语言学特殊兴趣小组协会。
十、测试
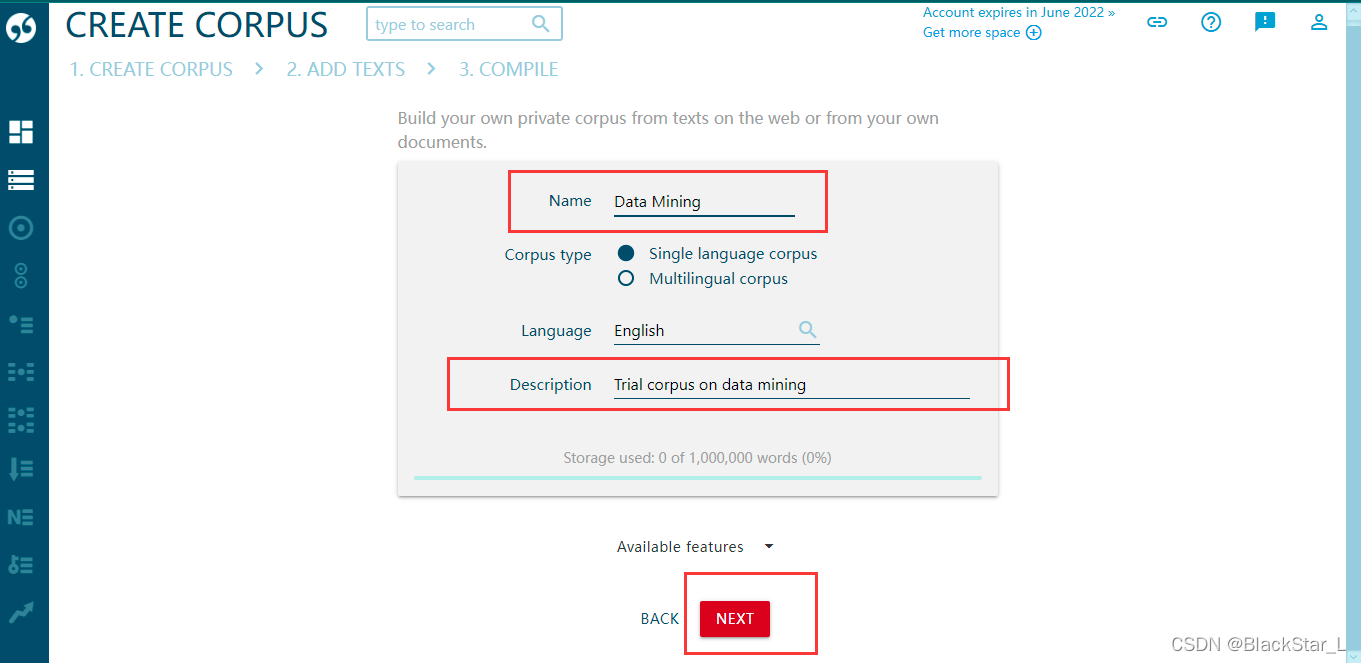
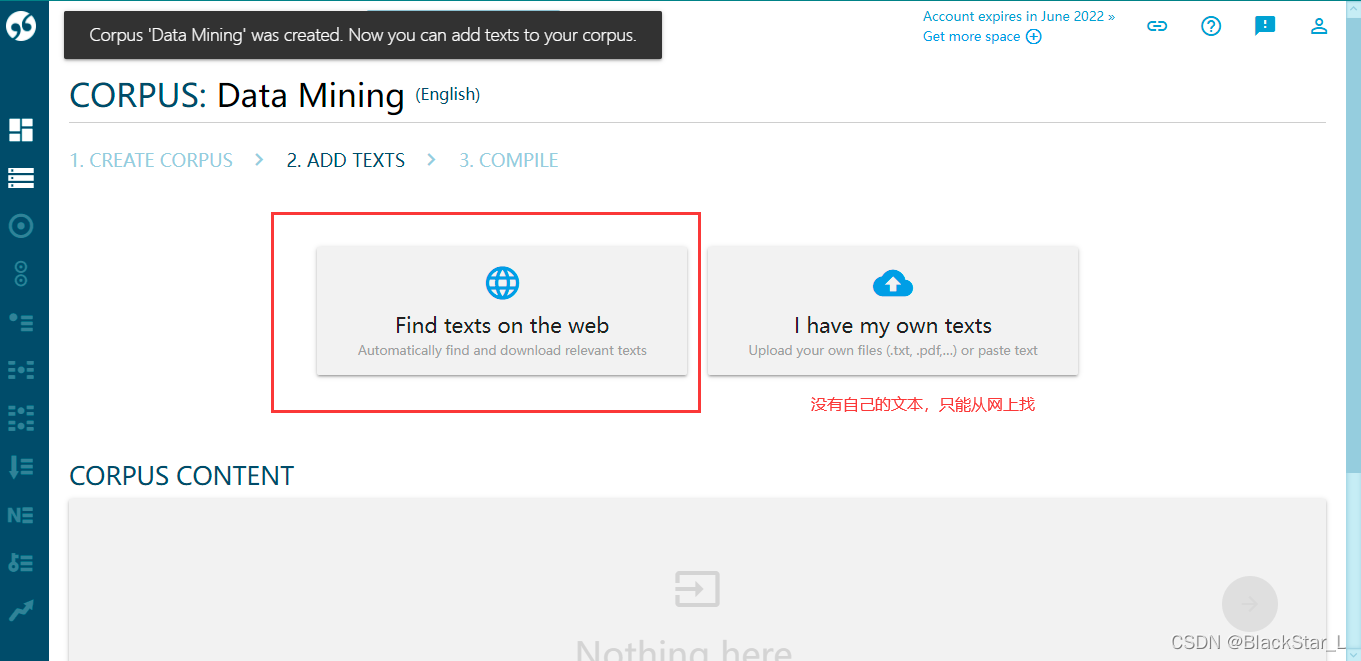
Web search 意思是使用一些术语通过搜索引擎去获取该术语的网页,然后下载该网页的文章
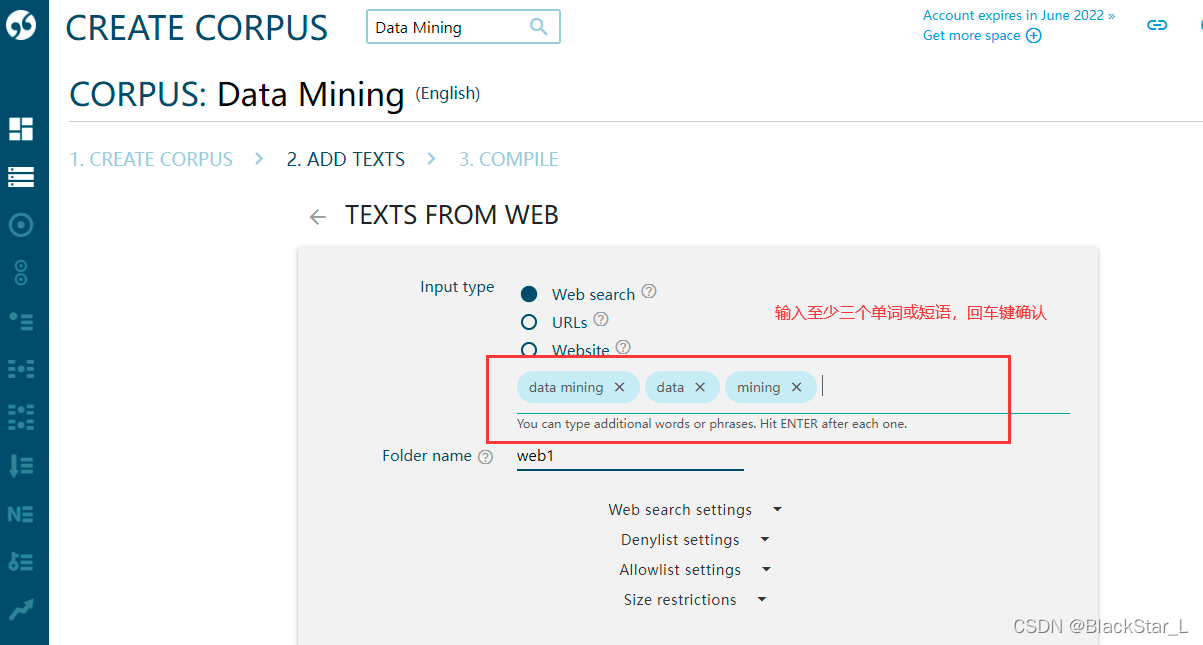
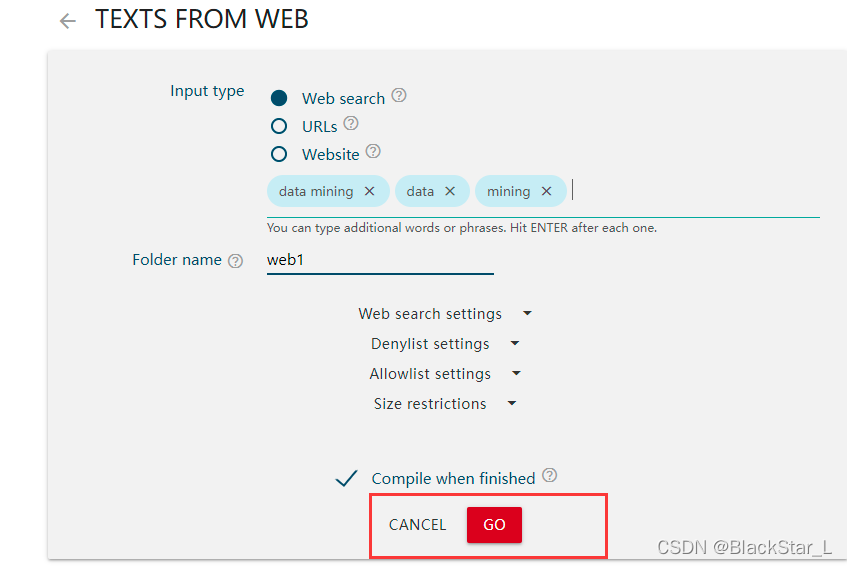
这里显示了搜索引擎匹配到我输入的术语
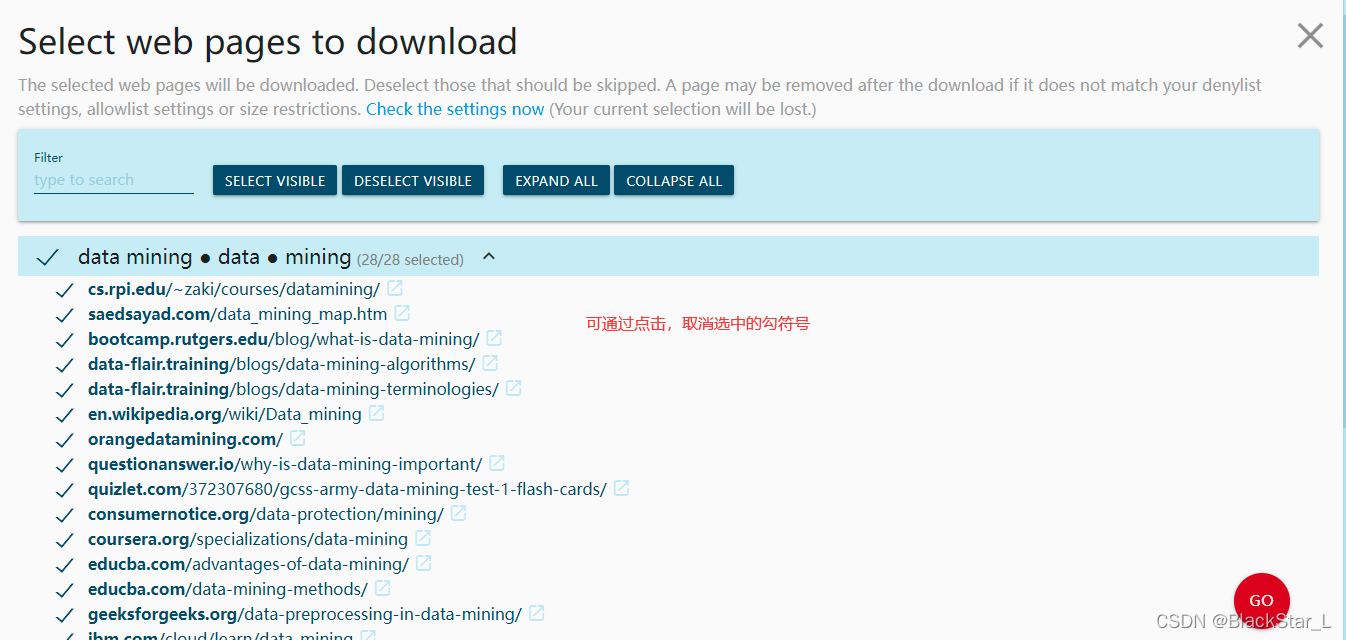
开始下载网页文本,会去掉图片,图表等等与文本不相关的内容:
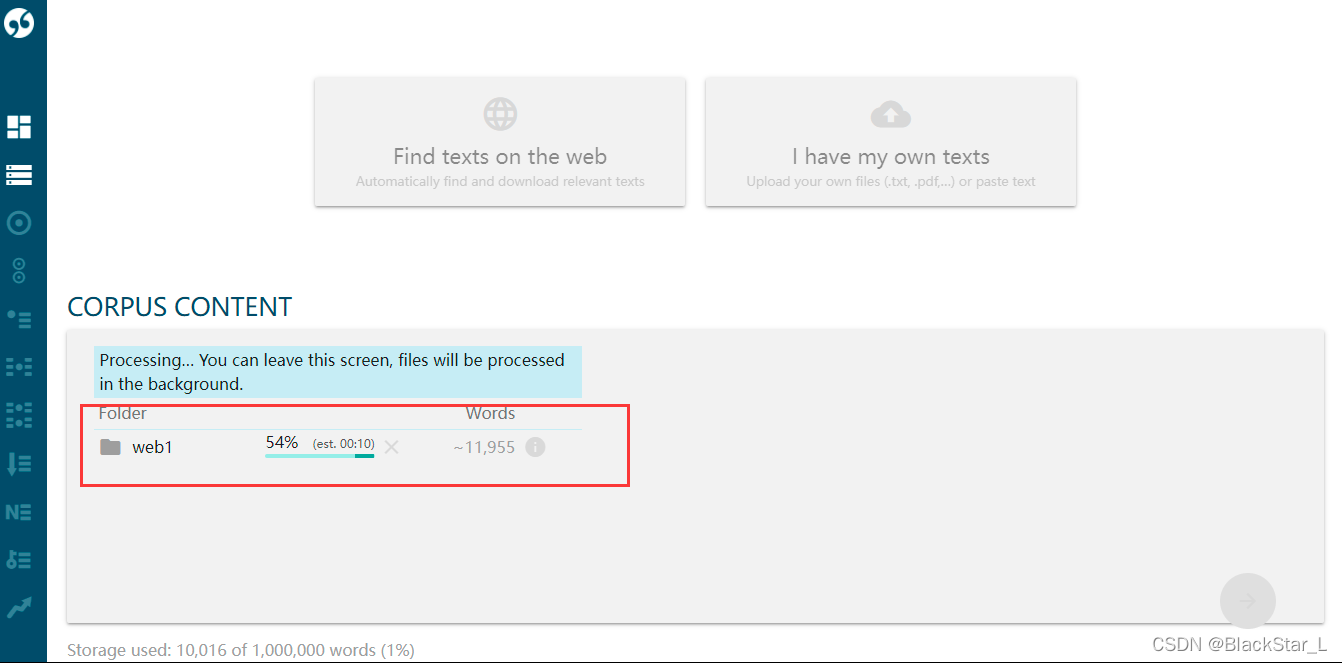
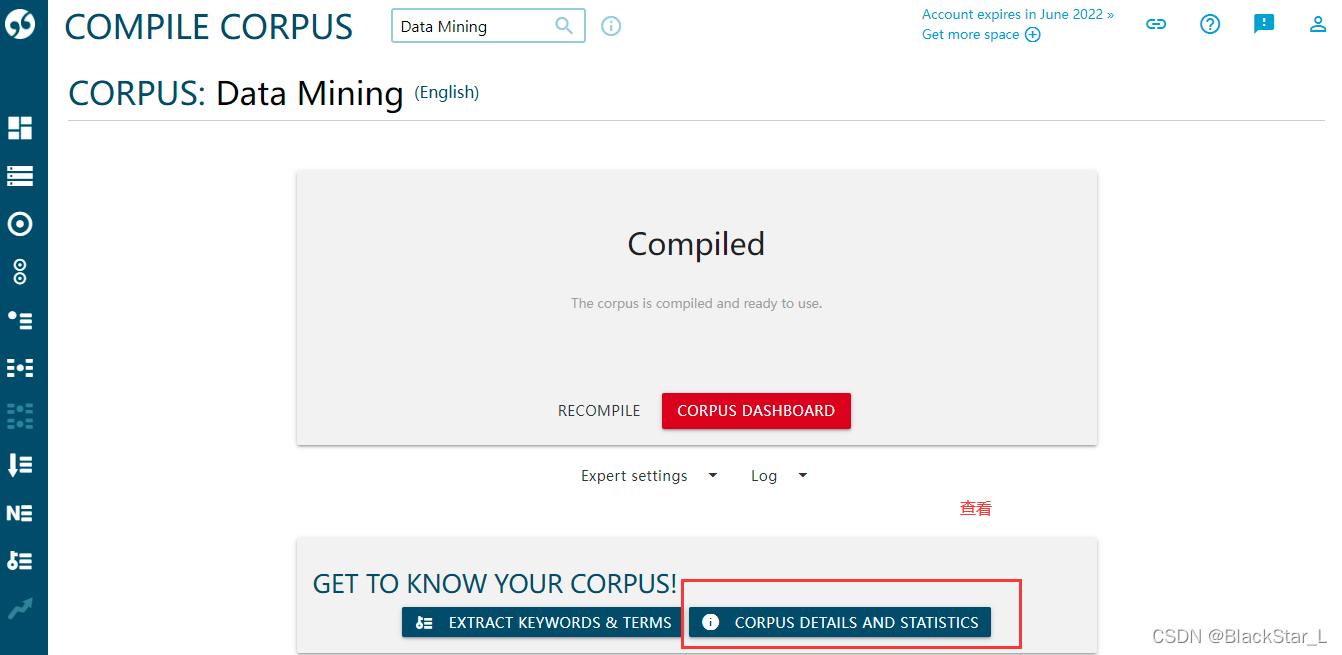
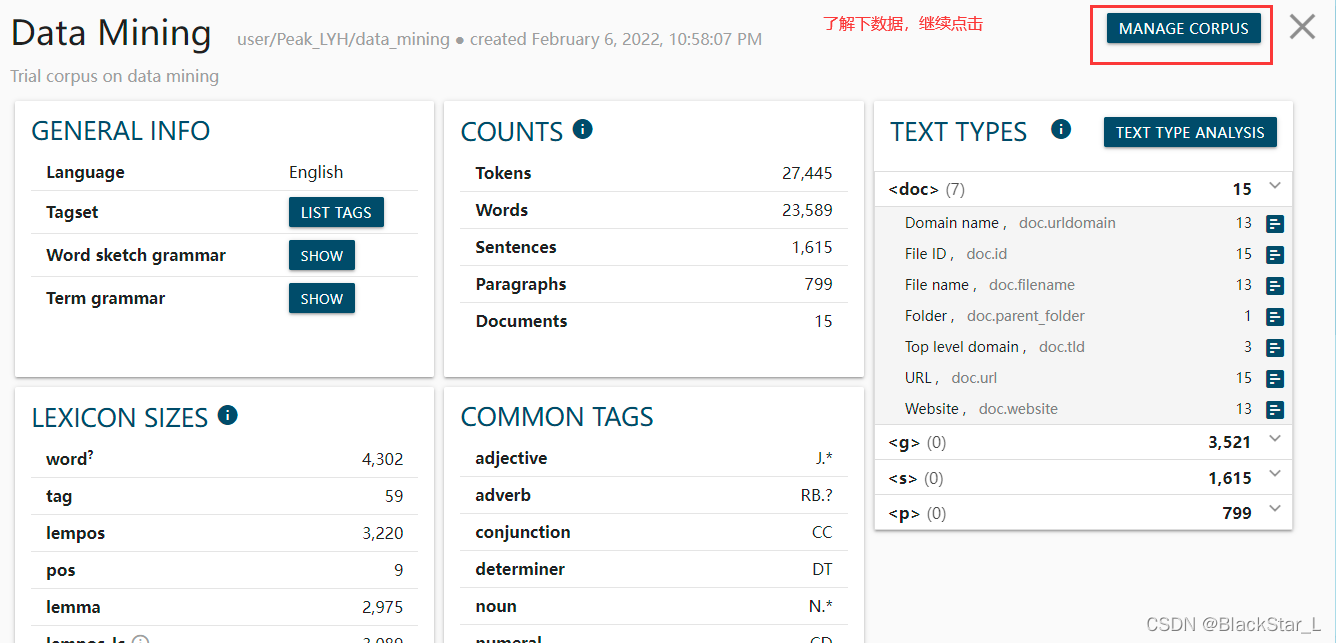
点击左侧栏 Dashboard
从语料库中提取一些关键词或者术语:
Advance有一些其他功能高级,可以选择标准词库。
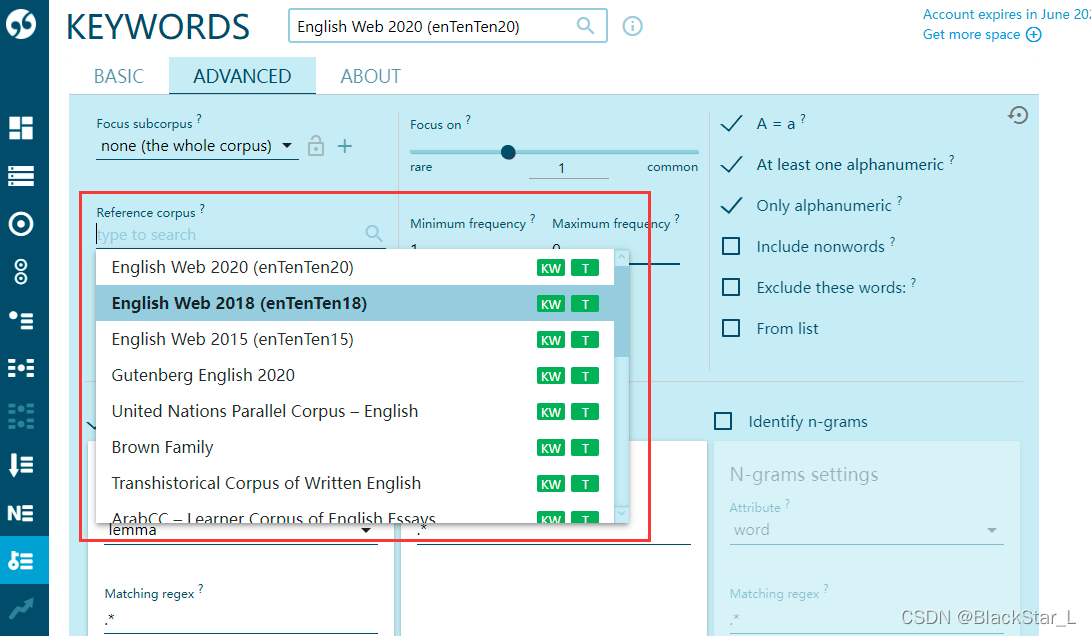
这里的结果是指,自己创建的词库的频率高于标准词库的单词或短语
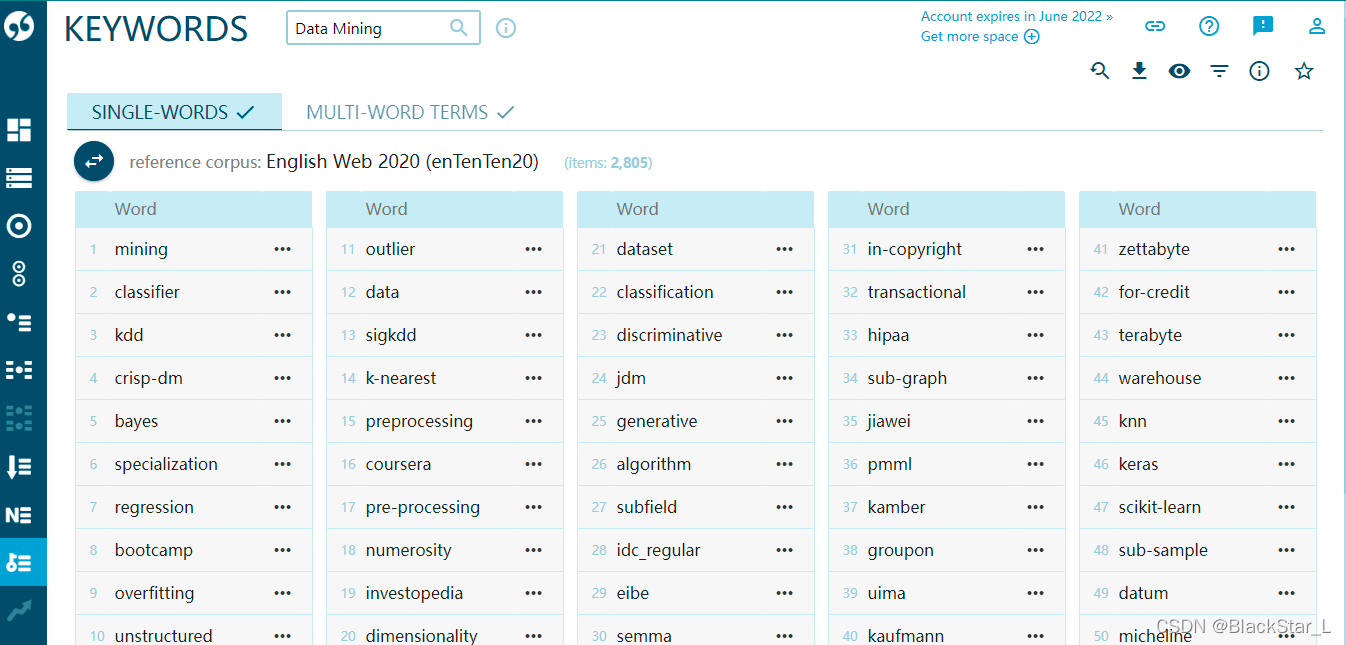
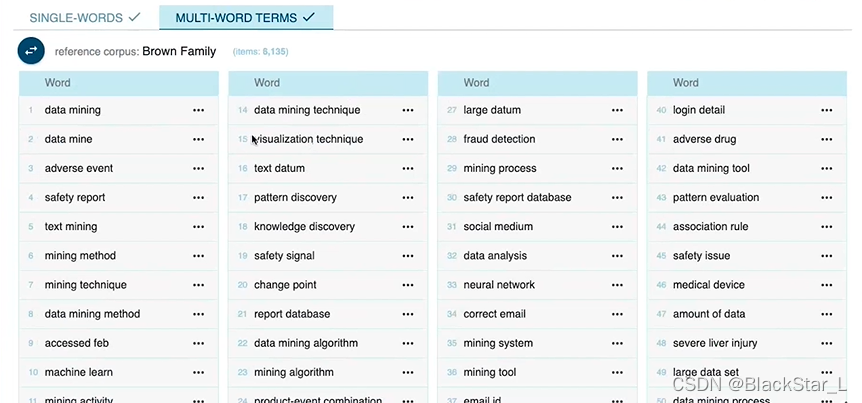
一般好的文本,多词术语数量高,而单词术语数量少
Leeds Internet Corpora (leeds)
参考
Eric Atwell - Data Mining and Text Analytics
Adam Kilgarriff - The Sketch Engine ten years on
修改时间
2022/2/5

















 5234
5234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









