







集成学习 Bagging与Boosting
一、一个小故事
在现代生活中,很多地方都涉及一个概念:冗余 (Redundancy),它原本是一种贬义词,指的是某些东西(信息、语言、代码、结构、服务、软件、硬件等等)重复且多余。
然而在通信存储等领域,它则成了中性词,是指对某些东西进行人为增加重复的部分,比如对某样东西进行备份,从而增强其安全性。对于这个概念,其中一个应用比较广泛的地方是航天系统。

SpaceX是一家著名的太空探索技术公司,其中比较知名的有其生产的Dragon系列载人龙飞船。因为太空的环境安全标准比地球严格非常多,所以制造飞船的材料也很特殊和昂贵,除此之外,还需要功能强大的超级计算机安置在飞船内部供宇航员进行监测和操控,以便维持飞船的正常轨迹运行。

然而在太空环境中,某些影响因素会导致计算机出现一些错误,比较典型的有:太空粒子翻转 (SEU,Single-Event Upsets),它是指在空间环境下存在着大量高能带电粒子,计算机中的电子元器件受到地球磁场、宇宙射线等照射,引起电位状态的跳变,“0"变成"1”,或者"1"变成"0"(太空探索早期人们已经注意到了这个问题)。
在地球表面,有磁场和大气层的保护,能够到达地面的高能粒子很少,一般来说对计算机的影响不大(当然除了人为制造或自然界的放射性物质,还有极低概率的宇宙粒子穿透地地球表面的大气层和磁场来到我们的生活区),所以在计算机设计中,并不需要过多考虑这种特殊场景,常规的硬件纠错机制配合操作系统,足以应付这种偶然的误差。计算机对于错误若实在改不过来,蓝屏重启,可能也就复原了。
然而在太空环境下,单粒子翻转的概率会大得多,那么校验算法会极其困难,因为单粒子翻转的可能不止一位,那么如何解决该问题,提高可靠性呢?

飞船的计算机和我们使用的计算机可靠性要求是不一样的,我们使用的计算机可以死机蓝屏,大不了重启一下就可以了,但飞船本身的控制计算机是必须持续可靠运行的,一旦出了问题,肯定是致命的。
SpaceX设计了一套整体容错三重冗余计算机架构(an overall Fault tolerance triple redundant computer architecture),即由多台计算机运行同一个软件,结果由多数表决系统处理产生一个单一的输出,正确的大多数计算结果会纠正和掩盖其他少数错误的故障。(某些领域使用N重冗余,结果计算方法类似,即多数表决)。虽然每台处理器都可能发生位翻转,但我们知道飞机上同时有两枚炸弹的概率是极低的。
某航天器在执行为期5天的航空任务中,单粒子翻转出现了161次之多,可见在外太空环境下,计算机计算结果的可靠性非常重要。
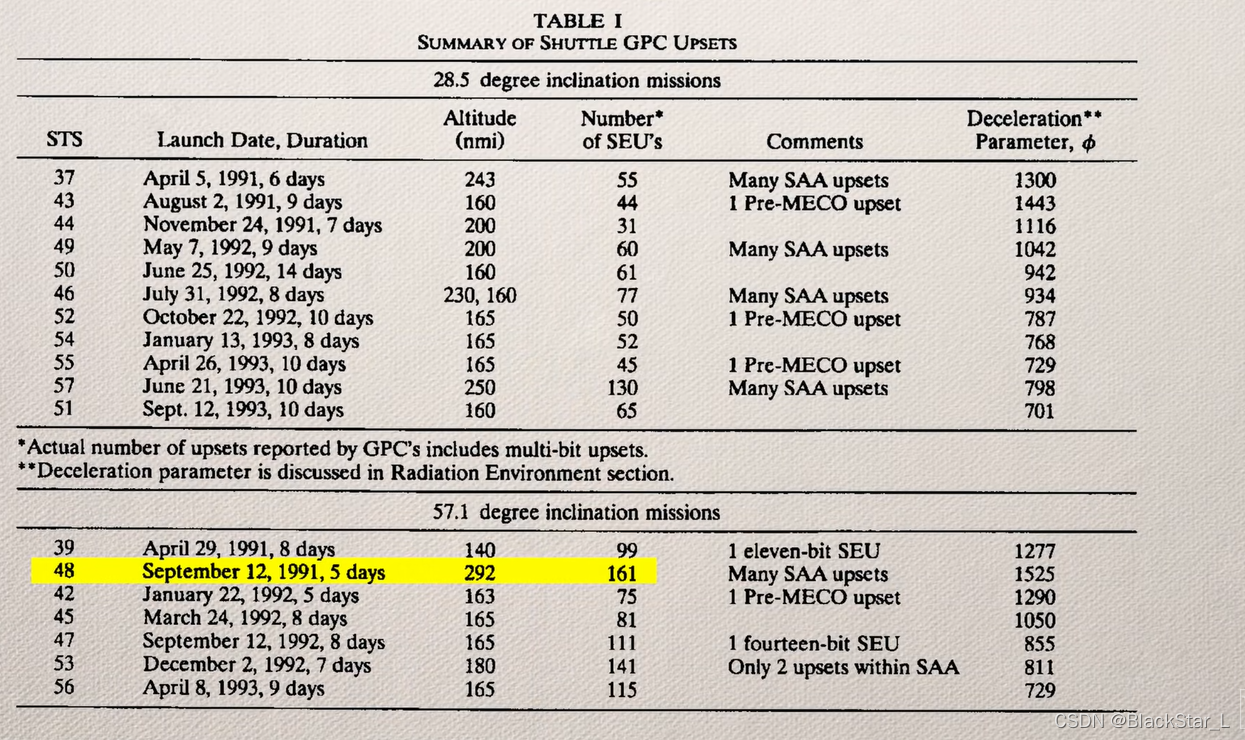
所以,与其花费巨大的人力物力制造一台几乎不受任何辐射粒子影响的先进超级计算机,不如带几台相对普通的超级计算机一起工作,无论是可靠性还是成本等其他方面,都比先进计算机要更好。
于是,借助这个思想,后面便引申出了机器学习算法中,集成学习(ensemble)的概念。
太空计算机为什么性能都这么低?(zhihu)
SINGLE EVENT UPSETS: HIGH ENERGY PARTICLES FROM OUTER SPACE FLIPPING BITS (hackaday)
Single-event_upset (wikipedia)
SpaceX_Dragon (wikipedia)
Triple_modular_redundancy (wikipedia)
二、集成学习 - Ensemble Learning
在数据挖掘等应用中,直接建立一个高性能的分学习器是很困难的,但是,如果能找到一系列性能较差的学习器(弱学习器),并把它们集合起来,组合之后的效果可能高于性能较强的学习器(强学习器)。
“三个臭皮匠,胜过诸葛亮”便是对这种思想最好的解释。
1、弱学习器与强学习器
弱学习器 (Weak Learner)
强学习器 (Strong Learner)
弱学习器是指,分类正确率仅比随机猜测略高的学习算法,
2、集成学习的具体步骤
集成学习的具体步骤为:
- 随机采样构造一系列新的训练集来生成一组个体学习器(Individual learner)
- 用某种策略将它们结合起来
3、集成方法 - Ensemble methods
(每个模型也被称为个体学习器(Individual learner)或者基学习器)
3.1、Bagging及相关模型
Bagging的核心思想为并行地训练一系列各自独立的同类型,然后再将各个模型的输出结果按照某种策略进行聚合。
3.1.1、Bagging
Bagging字面意思为装袋法,按照其组合的策略,同时也称为引导聚合算法(Bootstrap Aggregating),所以主要分为两个阶段:
- Bootstrap引导阶段:假设有一个大小为 n n n 的训练样本集 S S S,装袋法从样本 S S S 中多次
有放回的随机采样取出大小为 n ′ ( n ′ = n ) n^{'}(n^{'} = n) n′(n′=n) 的 m m m 个子训练集。
注意:
| 重点 | 说明 |
|---|---|
| 1 | 既然 n ′ = n n^{'}=n n′=n, 那么每个子训练集的大小和整体训练集样本大小一样大 |
| 2 | 既然每个子训练集的采样是有放回的,那么,每个样例的权重相等,但是同一样本可能在一个子训练集中多次出现,进而平均每个弱学习器只使用了原数据集中的63.2%的样本,同理训练集中大约有36.8%的数据没有被采集到。这样就存在一部分“袋外数据”(OOB)始终不被取到,它们可以直接用于测试误差,而无需单独的测试集或验证集。 |
推导:
每次被采集到的概率是 1 n \frac{1}{n} n1,那么不被采集到的概率为 1 − 1 n 1−\frac{1}{n} 1−n1,所以n次采样都没有 被采集中的概率是 ( 1 − 1 n ) n (1−\frac{1}{n})^{n} (1−n1)n,当 n → ∞ n \rightarrow \infty n→∞时,求极限:
根据等价无穷小, n ln ( 1 − 1 n ) = n × − 1 n = − 1 n\ln(1-\frac{1}{n})=n\times-\frac{1}{n}=-1 nln(1−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









