







前言
原论文题目是《Focal Loss for Dense Object Detection》。这篇文章主要是介绍了一种特殊的损失函数focal loss,RetinaNet则是作者为了证明focal loss有效而专门搭建的一个单阶段目标检测器。值得一提的是,本文来自何恺明团队,这个团队还曾提出过大名鼎鼎的、目前被引次数最多的ResNet。看完focal loss这篇文章,我个人感觉这个改进方法非常之简洁,简单到好像单独拿出来发论文都有点说不过去,但是它的效果确实是十分的有效。
问题与思路
通过前面的学习我们知道,目标检测方法可以分为两大类:两阶段和单阶段。其中单阶段的方法虽然较为简单且速度更快,但一般其精度要比两阶段的方法低。造成这一现象的主要原因是单阶段的方法往往在训练密集检测器时前景与背景类的数量极度不平衡。
那么为什么会造成类不平衡的问题呢?双阶段又是如何在一定程度上避免了这个问题呢?
类不平衡问题的形成原因是图片中的物体框数量一般来说都小于背景框的数量,也就是说不是所有的框都能检测出物体。
对于单阶段方法来说,只有一次分类,因此是细分类,这就导致背景类和如猫、狗等具体类是平行进行分类的,因此显然背景类的数量比每个细分的具体类多太多。
而两阶段的方法首先进行一个粗分类,也就是先对是前景还是是背景进行一个二分类,虽然这样还是背景类比前景类要多,但是和每个细分的具体类相比,背景类和前景类的数量更接近,也就是更平衡。
那么我们怎么解决这个类不平衡的问题呢?
总体思路是让各类的贡献尽可能平衡。
一个很自然的想法是对多的类进行抽样来均衡这种不平衡,比如固定前景类和背景类比例为3:1(faster R-CNN),但是这样显然没有充分利用所有的信息。那么我们不如换一种思路,也就是所有的类都要,但是对每种情况采用不同的权重进行处理,从这种思路出发最直接的做法就是去修改损失函数。之前有一种常用的方法称难例挖掘(我们在SSD中学习过),对于指向同一个目标的ROI,取满足条件且loss最大的几个ROI用作训练,其他都删除,以此来提高难样本的比例。这其实就是对每种情况的权值粗暴的赋予了0或1。但focal loss不同,它使得样本稀少的和难分类的权重相对增加,让模型更关注这一部分的训练。
focal loss
这部分主要来看看focal loss是怎么构造的。
首先来看最原始的二分类交叉熵损失函数:
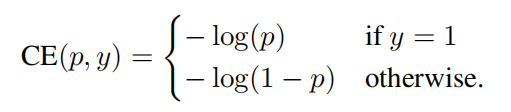
然后我们把这个式子的分段情况用一个新变量pt给抹去:

得到:
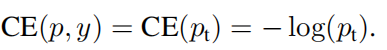
我们可以先分析一下这个损失函数的特点,我们可以发现,这个损失函数对于pt>>0.5的易分类样本也会产生一定的loss,而且这些loss累计加起来之后
会淹没难分类样本的对loss的贡献。
一个自然而然地想法是加上权重,首先定义一个权重
α
\alpha
α(取值[0,1]),将其设置为类频率的倒数或者一个又交叉验证设置来的超参数。仿照
p
t
p_t
pt的定义来定义权重
α
t
\alpha_t
αt,得到改进后的CE:
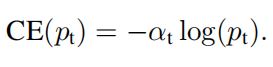
个人认为,
α
\alpha
α可以用来让样本稀少的类别权重高一些,起到控制类内样本数量不平衡的作用,但是还是没有解决对易分类和难分类样本的平衡。
因此修改损失函数:
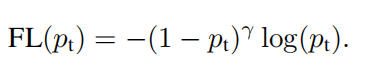
由上式,可得:
(1)当一个样本难分类时,
p
t
p_t
pt是接近0的,那么对应的调制因子就接近于1,进而这个loss是不受影响的;而当一个样本易分类时,
p
t
p_t
pt接近1,
(
1
−
p
t
)
γ
(1-p_t)^{\gamma}
(1−pt)γ接近0,因此loss相当于被降权重了。
(2)
γ
\gamma
γ这个参数可以调整易分类样本被降低权重的比率,实验验证
γ
\gamma
γ时效果最好。
这个函数就可以很好的控制易分类和难分类样本的平衡了,这我们也可以成为是一种难例挖掘方法。我们把
α
\alpha
α参数再加进来:
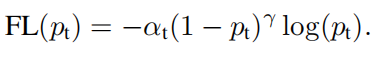
这就是完全体的focal loss了。通过这种处理,样本稀少的权重变高,样本多的权重变小,样本易分类的权重变低,样本难分类的权重不变(相比易分类相当于权重变多)。因此模型就会更加关注样本数少的(如前景),更加关注难分类的,这就解决了样本不平衡的问题。
网上有人总结了一个表格,正好和我上面说的一致:

RetinaNet
这一部分讲RetinaNet。我们说过,RetinaNet是何恺明团队专门写来用来验证focal loss强大之处的一个简单的目标检测器。
RetinaNet其实就是一个ResNet提取特征、FPN做backbone、两个自网络作检测、focal loss做损失函数的单阶段目标检测器,其具体结构如下:

其中FPN是在P3到P7级上构建的,在每个金字塔级上,都使用三种纵横比的anchors(和FPN原论文设置一样,{1:2,1:1,2:1}),在每一级的原来的3种纵横比上还增加了3种尺度大小({20,21/3,22/3}),采用FPN的主要原因是只用ResNet的效果不好。
两个子网一个用于分类,一个用于框的回归。
分类子网络会对每个位置的每个anchor(A个)的每个类别(K个)进行概率预测。这个子网络是在每个FPN级上联接一个小的FCN;这个子网络的参数在所有金字塔级上是共享的,最后联接sigmoid激活函数对于每个位置输出KA个二分类预测值。相比于RPN,这个分类子网络更深,且只采用3×3卷积核。
与目标分类子网络并行,本文对于金字塔的每一级联接了另一个小的FCN来对每个anchor对其临近的ground truth框(如果存在)进行回归。注意,分类子网络不与框回归子网络共享参数。
结果

由上表可以看出,RetinaNet的性能还是十分强悍的。
总结
这篇论文感觉最创新的点就在于focal loss这个损失函数的提出,RetinaNet倒是没有什么很让人眼前一亮的感觉。通过解读focal loss,我们可以很明显的体会到一点,那就是他真的非常简洁且有效,颇有种大道至简的意味。只对损失函数做了很小的改动,就可以使得效果有如此多的提升,这让人感到十分的震撼。














 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









