







背景
由于项目要求99.9%可用性,而此次事故导致宕机了五个小时,以后每个季度只能有一个小时的不可用时间。正好问题的排查一直都属于程序员的宝贵经验,因此就在这记录下来。
发生的现象:
上午10点钟左右,开始出现页面访问异常情况,检查发现某个服务每间隔一段时间就会重启一会。后续观察是每固定20分钟就会被k8s重启一次。
出现了异常重启的情况,首先就要查明异常的原因,直接原因比如CPU、内存等原因,间接原因就是看是哪里引起的每20分钟重启。
排查过程
1、Grafana监控报表
在Grafana上看到,基本在重启前的边缘上的情况:
- CPU比较正常,一直都是处于较低的使用率水平。
- JVM内存在有几次重启前都接近满了,可能能够被回收,但还没有触发Major GC,是个值得排查的地方,同时得去看看日志中有没有out of memory的报错日志。
- Tomcat连接池的线程数都满了,达到最大的使用数量了,因为我们这里使用的默认的配置,200个就已经满了。这是最大的嫌疑。
在上面三点基本看来最应该排查的就是Tomcat连接池。
2、存活探针相关Yaml
可能有人会觉得,就算连接池满了,或者JVM发生out of memory了,都不应该会直接导致服务的重启,这里因为我们用的是k8s,配置了服务的就绪探针和存活探针,每隔10秒钟调用一次服务的接口来确保服务存活。当失败超过3次以后就会认为这个服务已经死亡,就会开始重新启动一个Pod,并remove掉原来的Pod。所以才出现了这样的情况。
livenessProbe:
failureThreshold: 3
httpGet:
path: /actuator/health
port: 9902
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
首先我们是先调大了重启的服务的Tomcat并发连接数到500,但是发现了一点,即使连接数从200上升到了500,服务依旧在不断重启当中。
那么就再来排查是什么占用了如此多的连接数,每间隔20分钟出现一次,基本上能够确定是某个定时任务引起的,再查看Grafana上相关http请求调度频率,最终定位到了问题,同时看到那边的代码写法也是有问题的。
3、tomcat线程池与数据库连接池
本来是一个要批量获取数据的功能,由于之前就存在了feignClient的查询单个数据的接口,于是这里为了图方便,便直接使用了这个接口,而不是新增一个批量查询数据的接口。正好又是因为多次的查询比较慢,所以该同事使用了多线程异步的方式去获取数据,每有一个id,都会开启一个线程去查询,当有几百上千条数据的时候,就会有大量的线程同时请求过去,从而造成了目标服务的Tomcat连接数不足的问题。
业务代码类似下面示例:
for (int i = 0; i < list.size(); i++) {
CompletableFuture<String> future=CompletableFuture.runAsync(()->
//调用重启服务的接口
);
}
但是有一个问题就是,Tomcat并发连接数提高到了500了,一个接口访问不到1秒钟的时间,最多也不过几百上千的请求次数,按理来说在几秒之内处理完这些请求,不应该会再出现这样的情况才对,然而k8s在连续的三次存活探测中依然都直接超时了。那么除了Tomcat并发连接数,还有什么会拖慢请求呢?
所以就排查到了数据库最大连接数,目前数据库的最大连接数被设置成了20,不论你Tomcat连接数设置的多大,系统的性能值取决于最短板的地方,而这个就是数据库最大连接数,由于我们的系统是TOB服务,这个服务是查询和业务对接的,页面对接的信息,并不是处理数据的服务,因此大家之前也没有对这个服务的配置有过太多关注,才导致了这种情况。那么首先要做的就是提高数据库连接池最大连接数到100,同时将那个异步多次调用接口的定时任务进行优化,就解决这个问题了。
4、堆栈信息与Jprofile的使用
除了对连接池等做了一些排查之外,同时我们还对JVM堆内存进行了分析,排除JVM的问题。
其实一般情况下当发生内存无法正常回收的情况,是能够直接在服务日志中看到 java.lang.OutOfMemoryError: Java heap space的对内存溢出的日志的,因此只需要打开JVM heap dump on out of memory的参数即可,那么在发生堆内存溢出时,就会将当时的快照保存下来。
不过我们那暂时没有出现内存溢出的错误日志。一个就是考虑到发生内存溢出,我记得是在多少次GC之内回收率小于某个固定阈值之后才会抛出异常,它并不是一瞬间就会发生的,所以那么会不会在这之前k8s就将Pod重启了呢也说不准。
我们选取了POD重启前夕的情况作为快照手动导了出来进行分析。使用JProfiler工具进行分析。
基本上只需要看两个东西就行了。
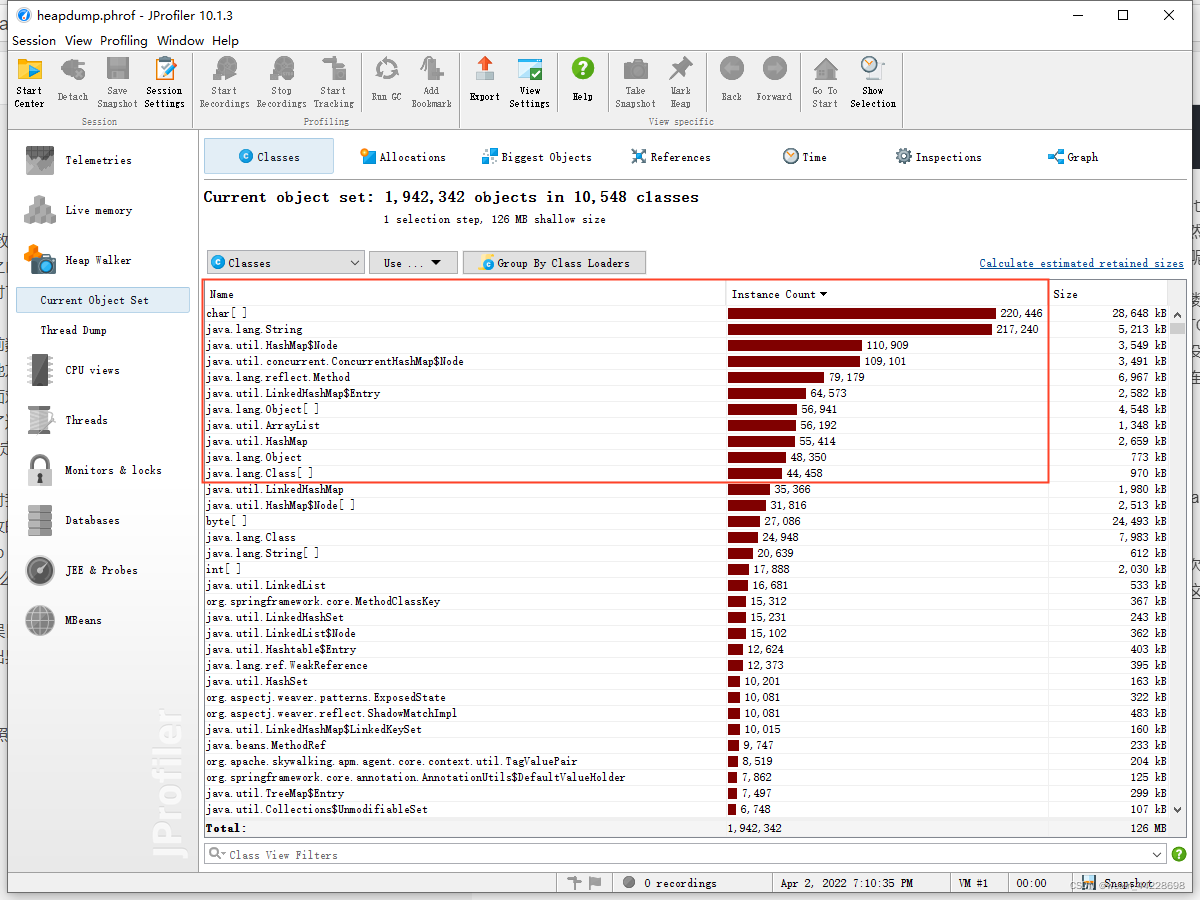
一个是占用内存和数量最多的是哪些类,尤其是关注其中和我们业务相关的类:
还有一个就是关注大对象,这也是最值得关注的:
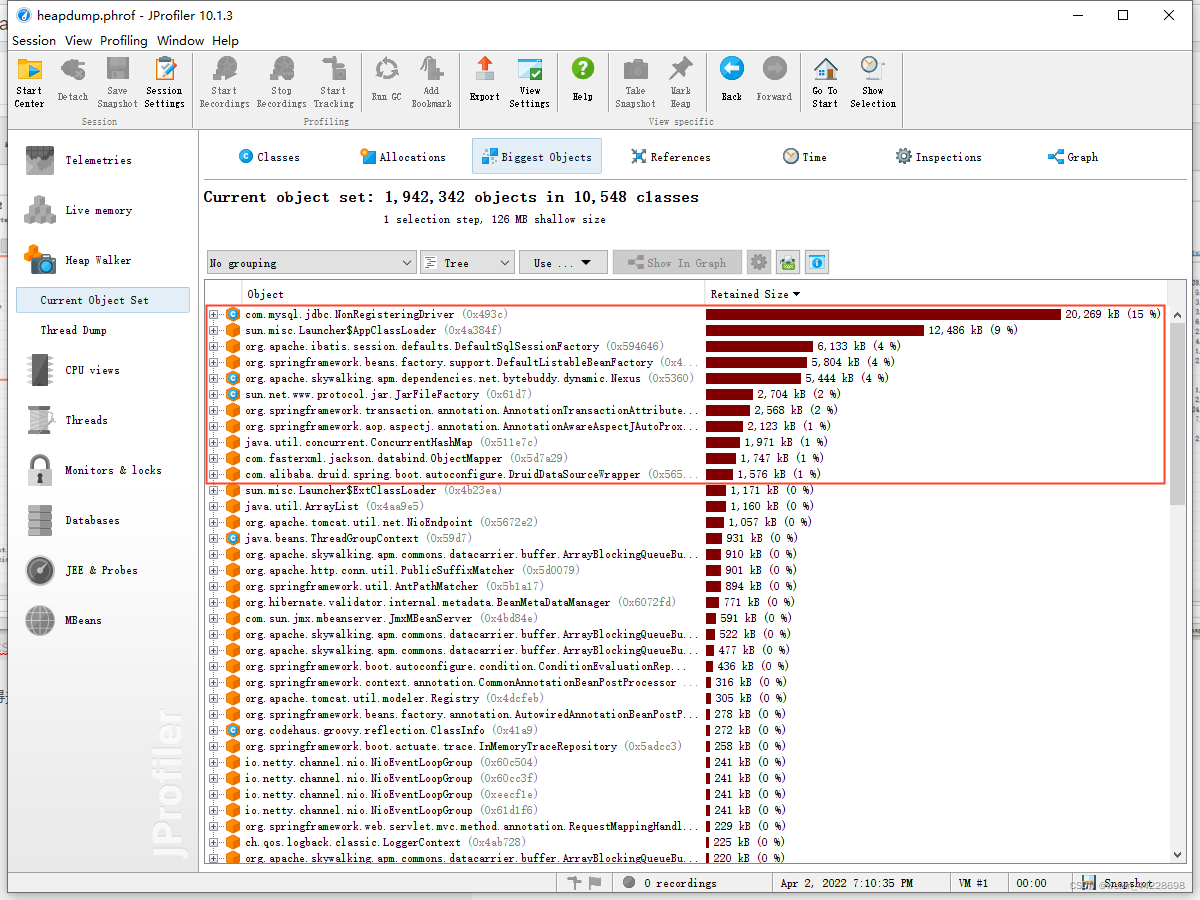
可以看到,上述图片基本显示了这些对象基本没有和我们业务相关的类,如果这是heap dump on out of memory拿出来的快照,而某些业务相关类占了很大内存和数量,那这就是我们极为需要关注的。
再就是Biggest Objects这张图,产生内存溢出的原因,基本就直接在这里面了,因为导致内存溢出的直接原因就是因为有大的对象不能够即使回收,现在基本对象回收都是可达性分析法,上面的最大类基本也就是大量对象的根引用所在,下面挂了一大群因此而不能回收的对象,我们可以直接点击一直往下,排查到与业务代码中相关的原因。
因为我这里并没有发生内存溢出,就拿spring下的DefaultListableBeanFactory简单举个例子
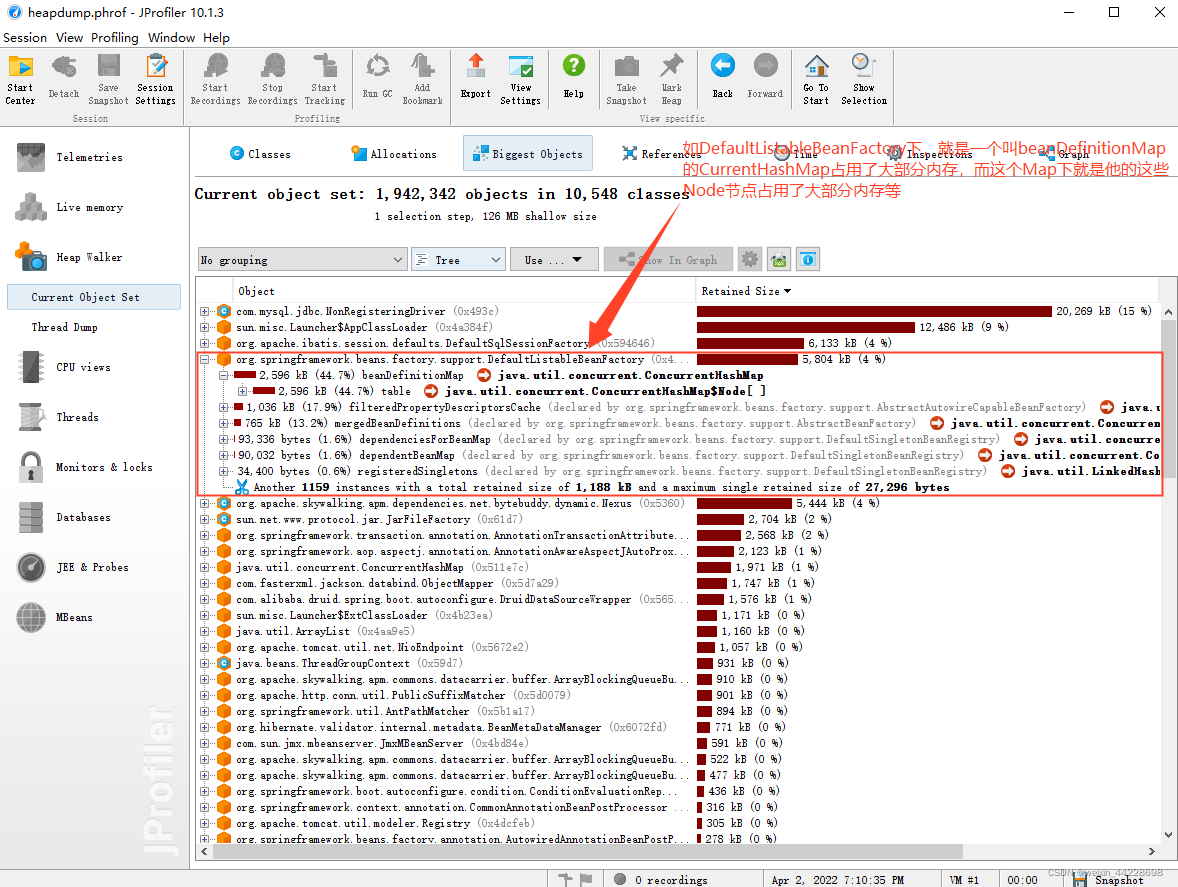
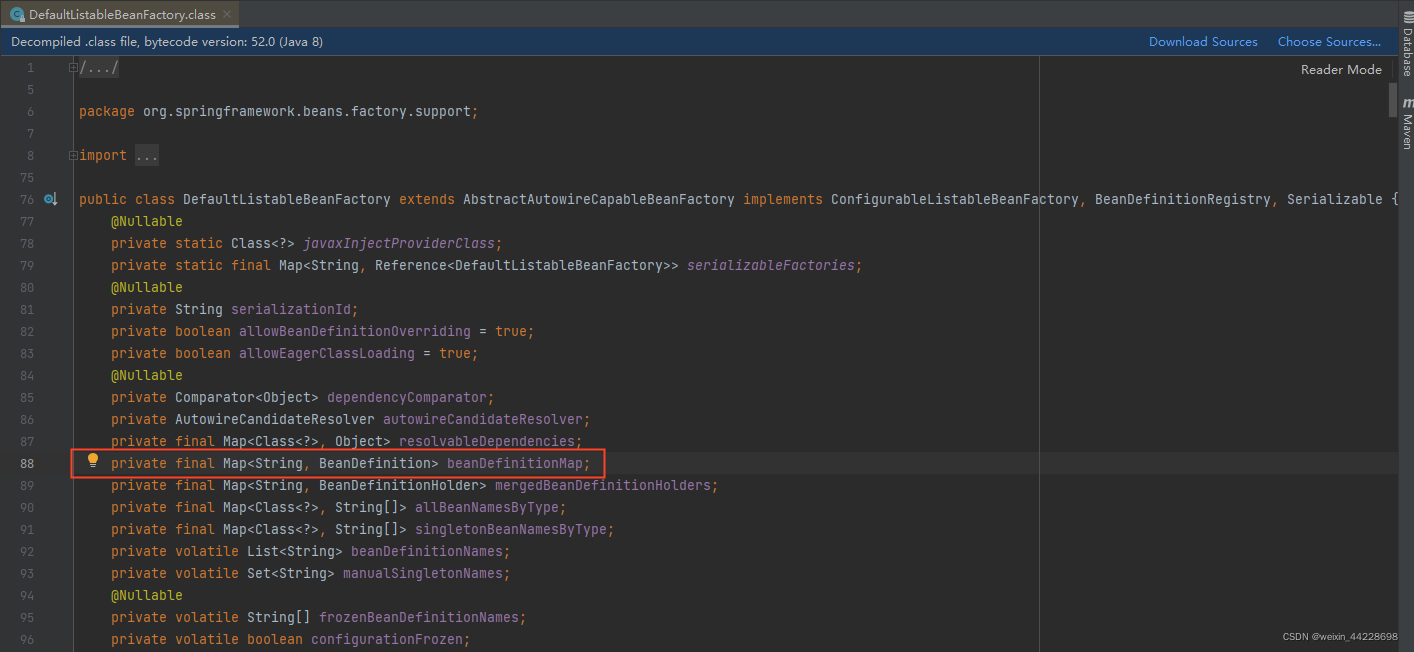
如DefaultListableBeanFactory下大部分的内存占用就是这个beanDefinitionMap的HashMap所占用的内存,这个Map下又是由他的Node节点占用了大部分内存。
我们可以直接在Jprofiler中点击+号一直往下找,就很容易从根节点一直循着引用链找到与我们业务代码相关的问题点在哪了。















 1890
1890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









