






1.数据爬取
import requests
import re
#from copyheaders import headers_raw_to_dict
from bs4 import BeautifulSoup
import pandas as pd
# 根据url和参数获取网页的HTML:
def get_html(url, params):
cookie = ''' urlfrom=121122523; urlfrom2=121122523; adfbid=0; adfbid2=0; x-zp-client-id=d8bf3203-74e4-4167-a350-64a935075e8f; sajssdk_2015_cross_new_user=1; zp_passport_deepknow_sessionId=90e6d4ffsf8e224afd92889cdb1d40d0c4e1; at=0bd784a38b4240698fdfed8c40fa2179; rt=e767a86b6891458d9ea90f22dfe2ee02; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221123230151%22%2C%22first_id%22%3A%2218146d179992e0-0e8756e0e2fe628-26021b51-1638720-18146d1799a147d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E4%BB%98%E8%B4%B9%E5%B9%BF%E5%91%8A%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Fbaidu.php%22%2C%22%24latest_utm_source%22%3A%22baiduPC%22%2C%22%24latest_utm_medium%22%3A%22CPC%22%2C%22%24latest_utm_campaign%22%3A%22jp%22%2C%22%24latest_utm_content%22%3A%22tj%22%2C%22%24latest_utm_term%22%3A%2232091649%22%7D%2C%22%24device_id%22%3A%2218146d179992e0-0e8756e0e2fe628-26021b51-1638720-18146d1799a147d%22%7D; acw_tc=ac11000116547505662275430e010fa8256a11ca24f916bae6e488493c2577'''
cookie = cookie.encode("utf-8")
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063',
'cookie': '''urlfrom=121122523; urlfrom2=121122523; adfbid=0; adfbid2=0; x-zp-client-id=d8bf3203-74e4-4167-a350-64a935075e8f; sajssdk_2015_cross_new_user=1; zp_passport_deepknow_sessionId=90e6d4ffsf8e224afd92889cdb1d40d0c4e1; at=0bd784a38b4240698fdfed8c40fa2179; rt=e767a86b6891458d9ea90f22dfe2ee02; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221123230151%22%2C%22first_id%22%3A%2218146d179992e0-0e8756e0e2fe628-26021b51-1638720-18146d1799a147d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E4%BB%98%E8%B4%B9%E5%B9%BF%E5%91%8A%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Fbaidu.php%22%2C%22%24latest_utm_source%22%3A%22baiduPC%22%2C%22%24latest_utm_medium%22%3A%22CPC%22%2C%22%24latest_utm_campaign%22%3A%22jp%22%2C%22%24latest_utm_content%22%3A%22tj%22%2C%22%24latest_utm_term%22%3A%2232091649%22%7D%2C%22%24device_id%22%3A%2218146d179992e0-0e8756e0e2fe628-26021b51-1638720-18146d1799a147d%22%7D; acw_tc=ac11000116547505662275430e010fa8256a11ca24f916bae6e488493c2577'''
}
req = requests.get(url, headers=headers, params=params)
req.encoding = req.apparent_encoding
html = req.text
return html
# 输入url和城市编号,获取由所有职位信息的html标签的字符串组成的列表:
def get_html_list(url, city_num):
html_list = list()
for i in range(1,20):
params = {'jl': str(city_num), 'kw': 'c语言', 'p': str(i)}
html = get_html(url, params)
soup = BeautifulSoup(html, 'html.parser')
html_list += soup.find_all(name='a', attrs={'class': 'joblist-box__iteminfo iteminfo'})
for i in range(len(html_list)):
html_list[i] = str(html_list[i])
return html_list
# 根据上面的HTML标签列表,把每个职位信息的有效数据提取出来,保存csv文件:
def get_csv(html_list):
# city = position = company_name = company_size = company_type = salary = education = ability = experience = evaluation = list() #
# 上面赋值方法在这里是错误的,它会让每个变量指向同一内存地址,如果改变其中一个变量,其他变量会同时发生改变
# table = pd.DataFrame(columns = ['城市','职位名称','公司名称','公司规模','公司类型','薪资','学历要求','技能要求','工作经验要求'])
city, position, company_name, company_size, company_type, salary, education, ability, experience = ([] for i in range(9)) # 多变量一次赋值
for i in html_list:
if re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i):
s = re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i).group(1)
city.append(s)
s = re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i).group(2)
experience.append(s)
s = re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i).group(3)
education.append(s)
else:
city.append(' ')
experience.append(' ')
education.append(' ')
if re.search('<span class="iteminfo__line1__jobname__name" title="(.*?)">', i):
s = re.search('<span class="iteminfo__line1__jobname__name" title="(.*?)">', i).group(1)
position.append(s)
else:
position.append(' ')
if re.search('<span class="iteminfo__line1__compname__name" title="(.*?)">', i):
s = re.search('<span class="iteminfo__line1__compname__name" title="(.*?)">', i).group(1)
company_name.append(s)
else:
company_name.append(' ')
if re.search(
'<span class="iteminfo__line2__compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>',
i):
s = re.search(
'<span class="iteminfo__line2__compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>',
i).group(1)
company_type.append(s)
s = re.search(
'<span class="iteminfo__line2__compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>',
i).group(2)
company_size.append(s)
else:
company_type.append(' ')
company_size.append(' ')
if re.search('<p class="iteminfo__line2__jobdesc__salary">([\s\S]*?)<', i):
s = re.search('<p class="iteminfo__line2__jobdesc__salary">([\s\S]*?)<', i).group(1)
s = s.strip()
salary.append(s)
else:
salary.append(' ')
s = str()
l = re.findall('<div class="iteminfo__line3__welfare__item">.*?</div>', i)
for i in l:
s = s + re.search('<div class="iteminfo__line3__welfare__item">(.*?)</div>', i).group(1) + ' '
ability.append(s)
table = list(zip(city, position, company_name, company_size, company_type, salary, education, ability, experience))
return table
if __name__ == '__main__':
url = 'https://sou.zhaopin.com/'
citys = {'上海':538,'北京':530, '广州':763, '深圳':765, '天津':531, '武汉':736, '西安':854, '成都':801, '南京':635, '杭州':653, '重庆':551, '厦门':682}
#citys = {'上海':'538'}
#df = pd.DataFrame(columns=['city', 'position', 'company_name', 'company_size', 'company_type', 'salary', 'education', 'ability', 'experience'])
for i in citys.keys():
print('正在爬取'+i)
html_list = get_html_list(url, citys[i])
table = get_csv(html_list)
df1 = pd.DataFrame(table, columns=['city', 'position', 'company_name', 'company_size', 'company_type', 'salary',
'education', 'ability', 'experience'])
file_name = r'D:\Data\智联数据\c语言数据\\'+ i + '.csv'
df1.to_csv(file_name,encoding='utf_8_sig')
2.读取csv职位数据 存进mysql
#读取csv职位数据 存进mysql
import pymysql
import pandas as pd
from sqlalchemy import create_engine
citys = {'上海':'538','北京':530, '广州':763, '深圳':765, '天津':531, '武汉':736, '西安':854, '成都':801, '南京':635, '杭州':653, '重庆':551, '厦门':682}
df = pd.DataFrame()
for i in citys.keys():
path = 'D:\Data\智联数据\c语言数据\\'+ i + '.csv'
tmp = pd.read_csv(path,header=0)
df = df.append(tmp[['city', 'position', 'company_name', 'company_size', 'company_type', 'salary',
'education', 'ability', 'experience']],ignore_index=True)
engine = create_engine('mysql+pymysql://root:root@localhost:3306/pachong?charset=utf8')
df.to_sql('info_position_1',con=engine,if_exists='append')
3.数据清洗
#数据预处理
#从mysql中读取数据并进行分析
#第一步 数据读入
import pymysql
import pandas as pd
import pandas as pd
import numpy as np
import re
'''
pandas直接读取mysql
'''
# 打开数据库连接
conn = pymysql.connect(host="localhost", user="root", password="root", db="pachong", port=3306)
sql = "select * from info_position_1"
df = pd.read_sql_query(sql, conn)
# 关闭连接
conn.close()
df = df[['city', 'position', 'company_name', 'company_size', 'company_type', 'salary',
'education', 'ability', 'experience']]
#薪资预处理
df1 = df
citys = [s[0:2] for s in df1.city.values]
df1['city'] = citys
#删除薪资为空的行
for i in range(len(df1)):
if df1['salary'][i]==' ' or df1['salary'][i]=='面议'or '天'in df1['salary'][i]:
df1 = df1.drop(i)
def salary_transform(s):
if re.search('(.*)-(.*)',s):
a = re.search('(.*)-(.*)', s).group(1)
if a[-1] == '千':
a = eval(a[0:-1]) * 1000
elif a[-1] == '万':
a = eval(a[0:-1]) * 10000
b = re.search('(.*)-(.*)', s).group(2)
if b[-1] == '千':
b = eval(b[0:-1]) * 1000
elif b[-1] == '万':
b = eval(b[0:-1]) * 10000
s = (int(a) + int(b)) / 2
else:
s = ''
return s
df1['salary'] = df1['salary'].apply(salary_transform)
df1=df1.dropna(axis=0, how='any', inplace=False)
df1 = df1.reset_index(drop=True)
4.聚合分析
#聚合分析
#1.聚合计算上海学历c语言职位不同学历薪资平均值
df1[df1['city']=='上海'].groupby('education')['salary'].mean()
#2.聚合计算上海不同公司性质薪资均值
df1[df1['city']=='上海'].groupby('company_type')['salary'].mean()
#3.聚合计算上海不同公司规模薪资均值
df1[df1['city']=='上海'].groupby('company_size')['salary'].mean()
#1.聚合计算南京学历c语言职位不同学历薪资平均值
df1[df1['city']=='南京'].groupby('education')['salary'].mean()
#2.聚合计算南京不同公司性质薪资均值
df1[df1['city']=='南京'].groupby('company_type')['salary'].mean()
#3.聚合计算南京不同公司规模薪资均值
df1[df1['city']=='南京'].groupby('company_size')['salary'].mean()
5.可视化展示
import matplotlib.pyplot as plt
#绘制上海c语言薪资前五占比饼状图
result=pd.value_counts(df1.loc[df1['city'] == '上海']['salary'].values.tolist())
plt.rcParams['font.sans-serif']=['FangSong'] # 设置显示中文 字体为宋体
plt.rcParams['font.size']=15 # 设置字体大小
labels = list(result.index[0:5].values)
values = list(result.values[0:5])
plt.pie(values,labels=labels,autopct='%1.1f%%')
plt.legend(loc=(1,0.8))
plt.title('上海c语言薪资前五占比')
plt.show()
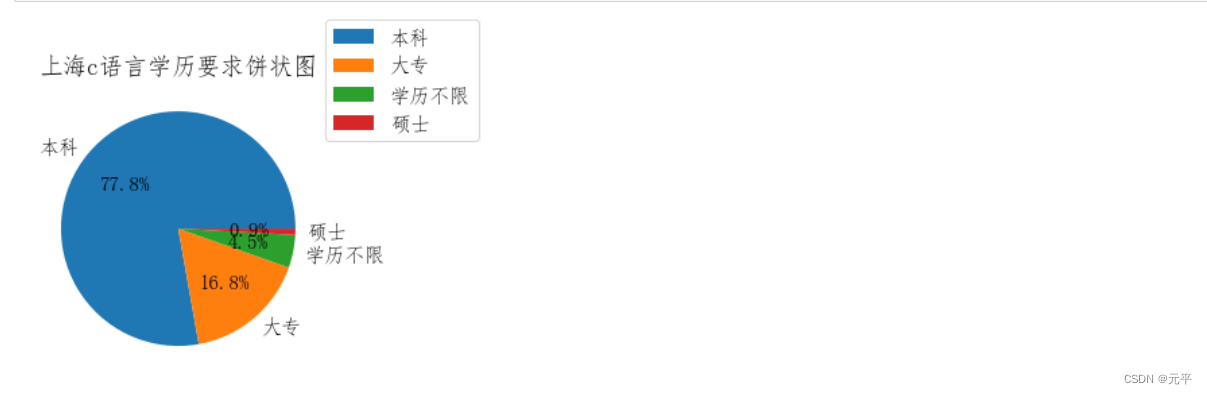
#绘制上海c语言职位学历要求饼状图
result=pd.value_counts(df1.loc[df1['city'] == '上海']['education'].values.tolist())
index=result.index.tolist()
values=result.values.tolist()
plt.rcParams['font.sans-serif']=['FangSong'] # 设置显示中文 字体为宋体
plt.rcParams['font.size']=15 # 设置字体大小
labels = list(result.index[0:5].values)
values = list(result.values[0:5])
plt.pie(values,labels=labels,autopct='%1.1f%%')
plt.legend(loc=(1,0.8))
plt.title('上海c语言学历要求饼状图')
plt.show()
#绘制上海学历c语言职位不同学历薪资平均值条形图
result = df1[df1['city']=='上海'].groupby('education')['salary'].mean()
labels = result.index.values.tolist()
data = result.values.tolist()
plt.bar(range(len(data)), data)
plt.xticks(range(len(data)),labels)
for i in range(len(data)):
plt.text(x= i- 0.05 , y=data[i] + 0.2, s = '%d' % data[i])
plt.xlabel("学历")
plt.ylabel("薪资")
plt.title("上海学历c语言职位不同学历薪资平均值条形图")
plt.show()
#绘制上海学历c语言职位不同公司规模薪资均值条形图
result = df1[df1['city']=='上海'].groupby('company_size')['salary'].mean()
labels = result.index.values.tolist()[1::]
data = result.values.tolist()[1::]
plt.figure(1, figsize=(16, 8))
plt.bar(range(len(data)), data)
plt.xticks(range(len(data)),labels)
for i in range(len(data)):
plt.text(x= i- 0.05 , y=data[i] + 0.2, s = '%d' % data[i])
plt.xlabel("学历")
plt.ylabel("薪资")
plt.title("上海学历c语言职位不同公司规模薪资均值条形图")
plt.show()
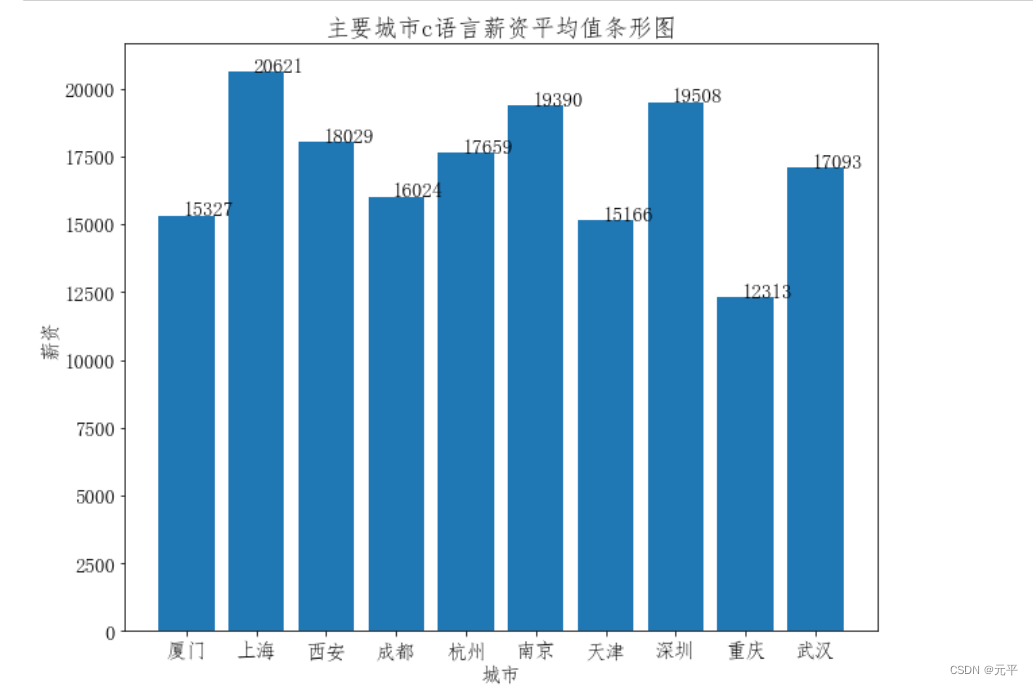
citys = list(set(df1['city'].values.tolist()))
values = []
values.append(df1[df1['city']==citys[0]]['salary'].mean())
values.append(df1[df1['city']==citys[1]]['salary'].mean())
values.append(df1[df1['city']==citys[2]]['salary'].mean())
values.append(df1[df1['city']==citys[3]]['salary'].mean())
#values.append(df1[df1['city']==citys[4]]['salary'].mean())
values.append(df1[df1['city']==citys[5]]['salary'].mean())
values.append(df1[df1['city']==citys[6]]['salary'].mean())
values.append(df1[df1['city']==citys[7]]['salary'].mean())
values.append(df1[df1['city']==citys[8]]['salary'].mean())
values.append(df1[df1['city']==citys[9]]['salary'].mean())
#values.append(df1[df1['city']==citys[10]]['salary'].mean())
values.append(df1[df1['city']==citys[11]]['salary'].mean())
data = values
labels = ['厦门', '上海', '西安', '成都', '杭州', '南京', '天津', '深圳', '重庆', '武汉']
plt.figure(2, figsize=(10, 8))
plt.bar(range(len(data)), data)
plt.xticks(range(len(data)),labels)
for i in range(len(data)):
plt.text(x= i- 0.05 , y=data[i] + 0.2, s = '%d' % data[i])
plt.xlabel("城市")
plt.ylabel("薪资")
plt.title("主要城市c语言薪资平均值条形图")
plt.show()


















 5725
5725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









