








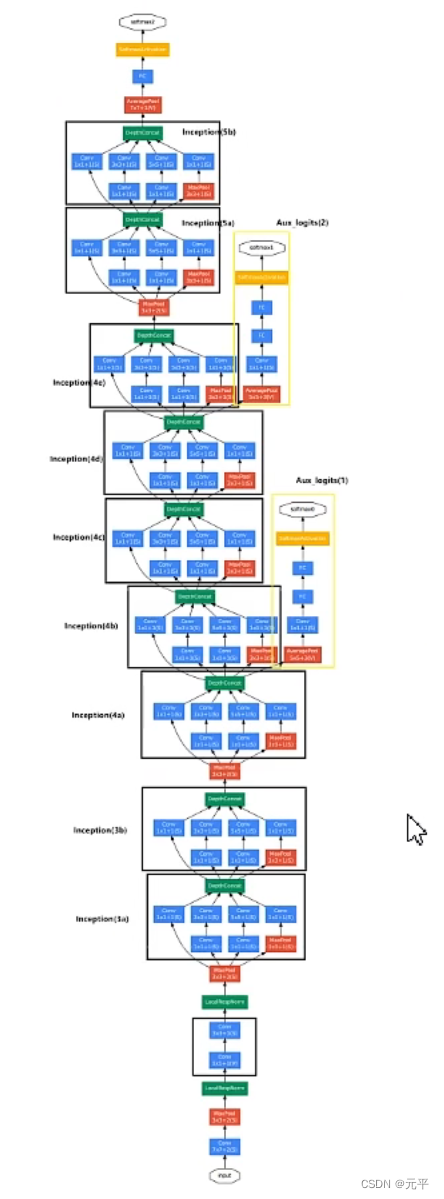

数据集介绍及下载可以参考我的上一篇文章:
https://blog.csdn.net/weixin_44230855/article/details/125251054?spm=1001.2014.3001.5502
模型搭建:
import torch
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module): #GooLeNet继承自nn.Module这个类
# 传入的参数中aux_logits=True表示训练过程用到辅助分类器,aux_logits=False表示验证过程不用辅助分类器
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
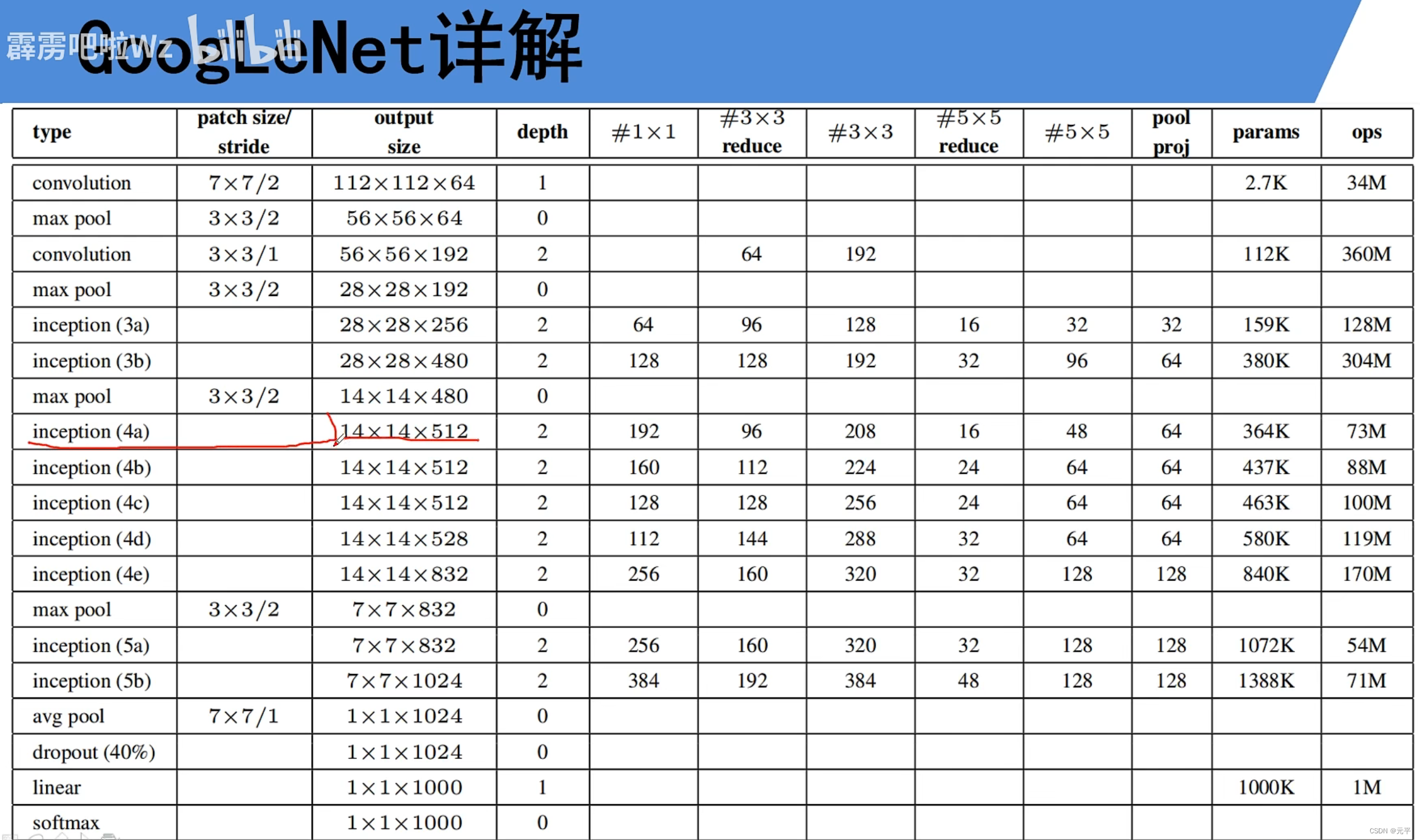
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
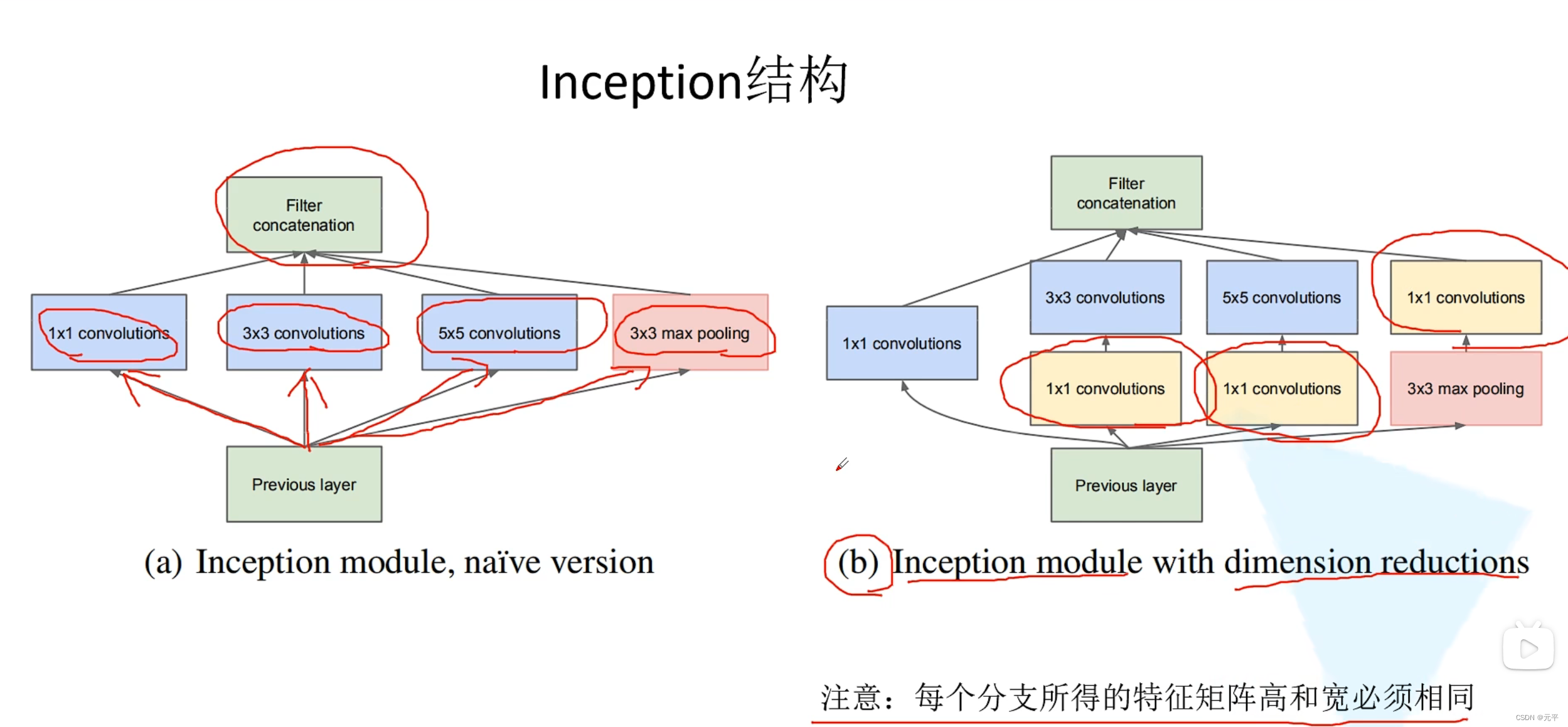
# Inception结构
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
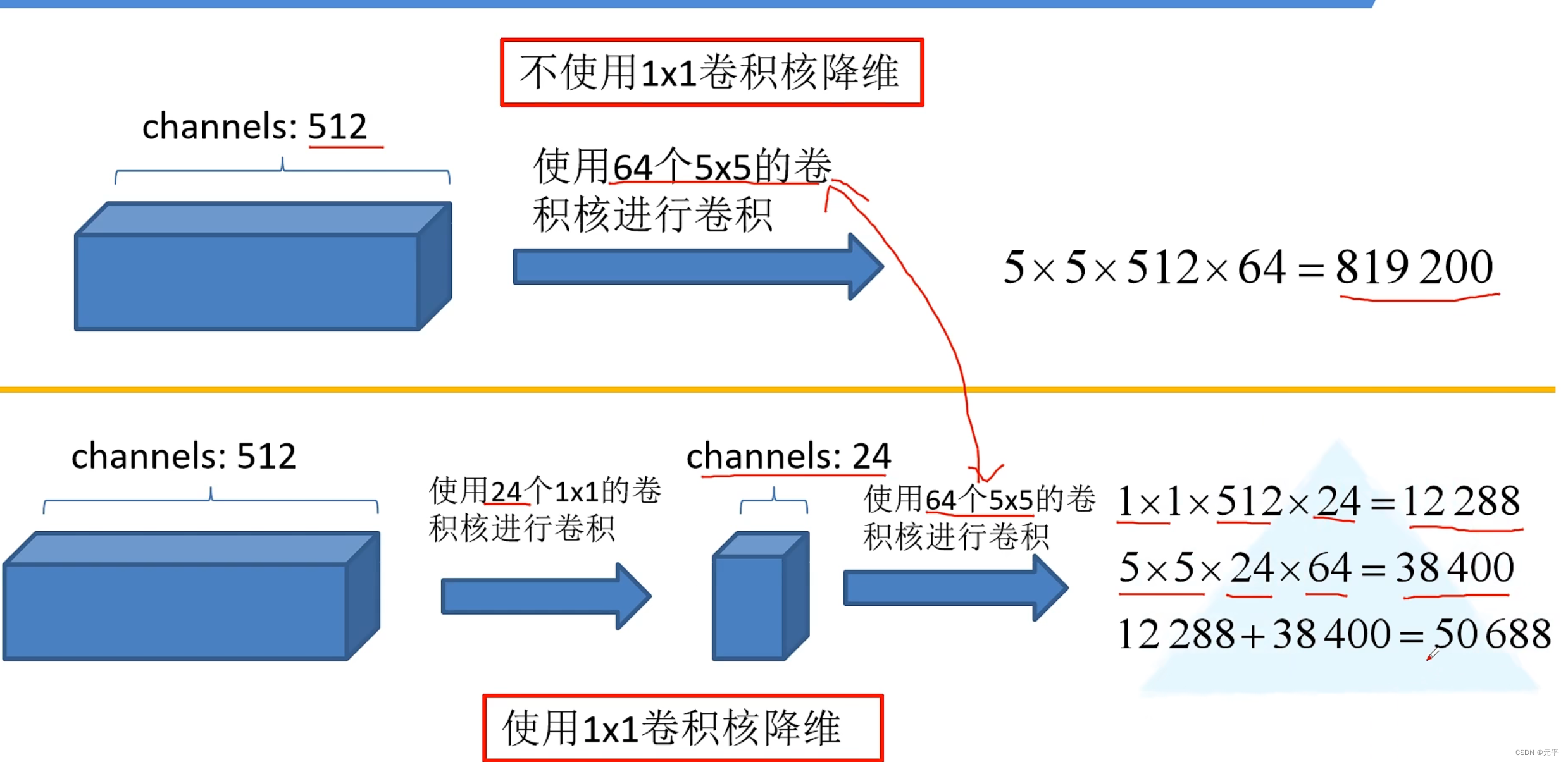
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) # 按 channel 对四个分支拼接
# 辅助分类器
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
# 基础卷积层(卷积+ReLU)
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
训练代码:
# 导入包
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import GoogLeNet
import os
import json
import time
# 使用GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪,再缩放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向随机翻转,概率为 0.5, 即一半的概率翻转, 一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 获取图像数据集的路径
# data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path 返回上上层目录
# 'D:\Downloads-chrome\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\data_set'
# image_path = data_root + "/data_set/flower_data/" # flower data_set path
image_path = r'C:\Users\18312\PycharmProjects\AlexNet_pytorch\data_set\flower_data' #数据文件夹
#print(image_path)
# # 导入训练集并进行预处理
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
#
# # 按batch_size分批次加载训练集
train_loader = torch.utils.data.DataLoader(train_dataset, # 导入的训练集
batch_size=32, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
# 导入验证集并进行预处理
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
print(val_num)
# 加载验证集
validate_loader = torch.utils.data.DataLoader(validate_dataset, # 导入的验证集
batch_size=32,
shuffle=True,
num_workers=0)
# 字典,类别:索引 {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 将 flower_list 中的 key 和 val 调换位置
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将 cla_dict 写入 json 文件中
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)# 实例化网络(输出类型为5,初始化权重)
net.to(device) # 分配网络到指定的设备(GPU/CPU)训练 这里有问题
loss_function = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器(训练参数,学习率)
save_path = './AlexNet.pth'
best_acc = 0.0
test_accuracys = []
epochs = 10
for epoch in range(epochs):
net.train() # 训练过程中开启 Dropout
running_loss = 0.0 # 每个 epoch 都会对 running_loss 清零
time_start = time.perf_counter() # 对训练一个 epoch 计时
for step, data in enumerate(train_loader, start=0): # 遍历训练集,step从0开始计算
images, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
outputs = net(images.to(device)) # 正向传播
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
running_loss += loss.item()
# 打印训练进度(使训练过程可视化)
rate = (step + 1) / len(train_loader) # 当前进度 = 当前step / 训练一轮epoch所需总step
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print('%f s' % (time.perf_counter() - time_start))
########################################### validate ###########################################
net.eval() # 验证过程中关闭 Dropout
acc = 0.0
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
# 保存准确率最高的那次网络参数
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' %
(epoch + 1, running_loss / step, val_accurate))
test_accuracys.append(val_accurate)
x = [i for i in range(1,epochs+1)]
plt.plot(x, test_accuracys, marker='o', markersize=3) # 绘制折线图,添加数据点,设置点的大小
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示汉字
plt.title('GooLeNet测试集准确度变化') # 折线图标题
plt.show()
print('Finished Training')
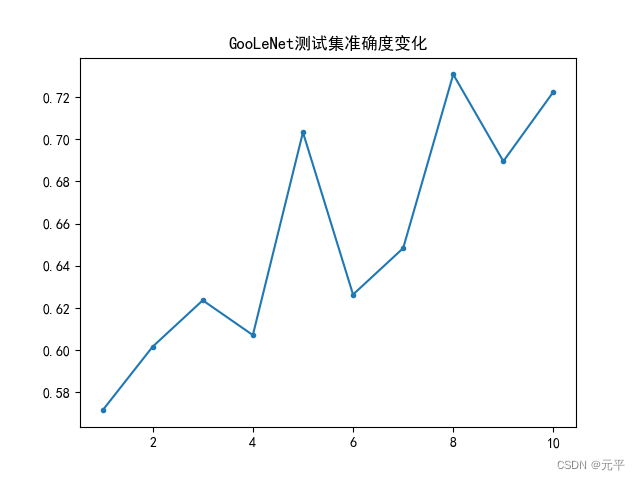
训练一个epoch耗时大约20s,训练了10个epoch,准确度变化如下图:
仅供学习交流 如有侵权 联系删除 QQ:1831255835
致谢:
B站up主:霹雳吧啦Wz
https://www.bilibili.com/video/BV1W7411T7qc/?spm_id_from=333.788&vd_source=e93113e88e71956b3d18f1eb599bf012
https://blog.csdn.net/m0_37867091/article/details/107150142















 7325
7325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









