







FileInputStream和BufferedInputStream
FileInputStream:文件字节输入流
BufferedInputStream:缓冲字节输入流
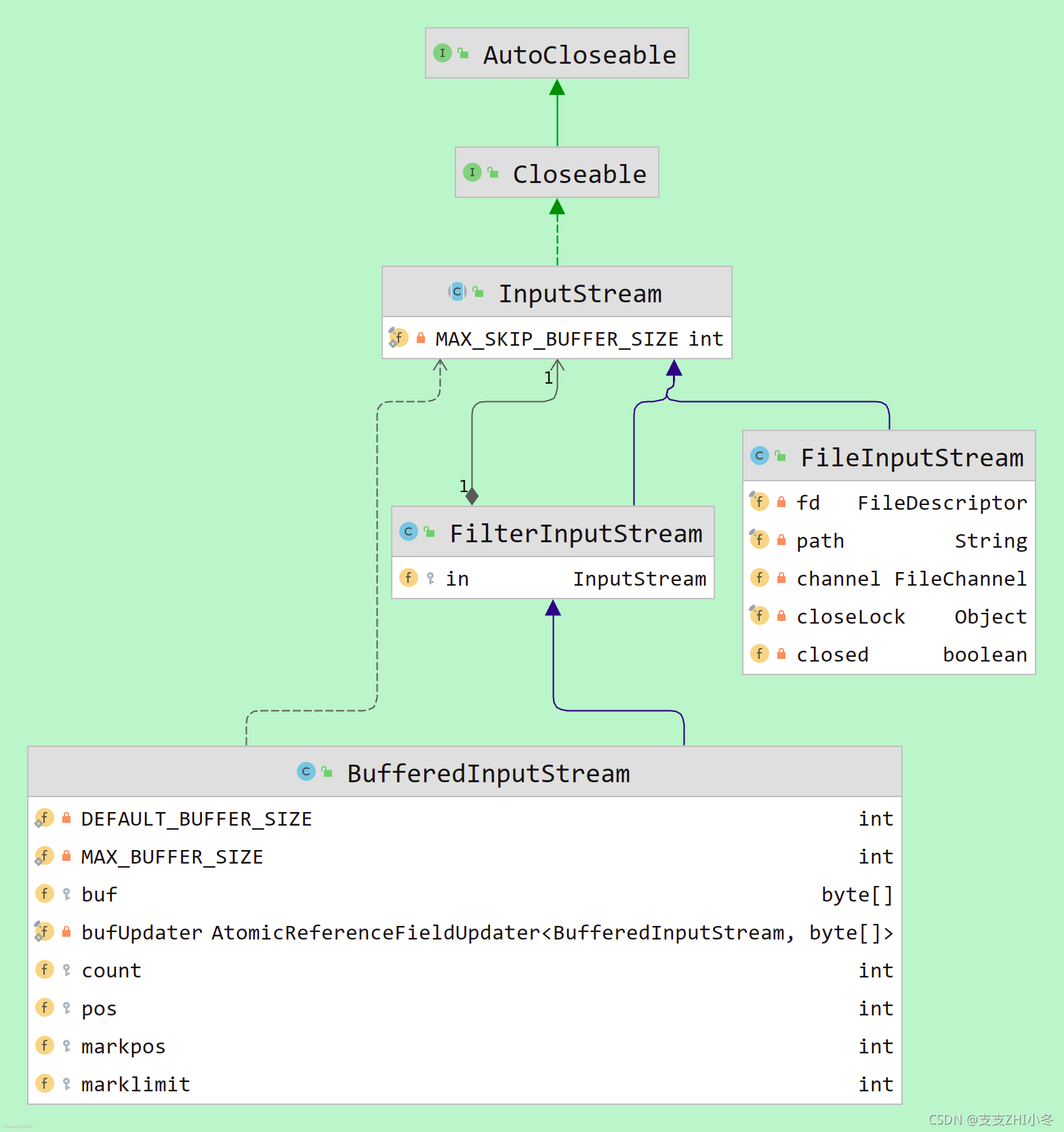
BufferedInputStream是FilterInputStream的子类,而FilterInputStream是InputStream的子类。
FilterInputStream持有一个InputStream in,而当从数据源是文件的时候,也就是InputStream是FileInputStream的时候,就是从文件读取字节的场景。
- BufferedInputStream有一个byte[]类型的buf属性,以及count,pos等操作字节数组的属性。这也就是BufferedInutStream这个Buffered的含义。有缓冲区。
- FileInputStream就是文件相关的属性,没有缓冲区的能力。
BufferedInputStream用法
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(inputFile));
while (bufferedInputStream.read() != -1) {
}
new BufferedInputStream的时候,参数是new FileInputStream(inputFile);
构造方法会将这个FileInputStream赋值给变量in。同时new一个默认值为8192的字节缓冲区的字节数组。源码如下:
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
执行bufferedInputStream.read()解析,源码如下:
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
总结一下:
count的含义,是从文件中进行一次io读取8192个字节并存储再缓冲区后,缓冲区的字节数量。
pos是本次要读取的字节数组的下标。
-
当缓冲区没有字节的时候,回调用file()方法,进行一次文件的IO读取,将读取的内容存储再字节缓冲区。之后从字节缓冲区读取pos位置的字节并返回。
-
当缓冲区有数据的时候,直接返回缓冲区pos位置的字节,并返回。
FileInputStream的用法
FileInputStream fileInputStream = new FileInputStream(inputFile);
while (fileInputStream.read() != -1) {
}
看下FileInputStream的构造方法:
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
fd = new FileDescriptor();
fd.attach(this);
path = name;
open(name);
}
主要干几件事情:
1、new 一个FileDescriptor并切attach一下自己。
2、文件的路径复制给path属性
3、调用native方法open,打开文件。
查看下read方法
public int read() throws IOException {
return read0();
}
private native int read0() throws IOException;
直接调用native方法进行文件io,读取一个字节。
对比总结
假如一个文件有8192个字节。
1、使用BufferedInputStream的时候,只会进行一次文件io。就能拿到所有字节。而使用FileInputStream则回进行8192次IO,才能逐个读取所有字节。
2、结论1中总结了逐个读取的场景,当一次读取8192个字节的时候,那FileInputStream甚至比BufferedInputStream性能还好一些,毕竟少了那么多数组操作。测试环境8M+的文件,耗时也就少10+毫秒,总体来说基本忽略。
3、当一次读取的字节数量超过BufferedInputStream的时候,那么就不会使用缓冲区了,直接走FileInputStream的批量读取方法了,性能上和FileInputStream是一致的啦。
4、当一次性读取的字节小于8192的时候,那么一次性读取的越少,BufferedInputStream性能优势越大,毕竟IO次数减少的越多。














 6525
6525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









