







by:wenwenC9
上一篇文章
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
一、介绍
在实现检索增强生成(RAG)的过程中,其中一个关键模块是数据的获取。虽然这听起来很简单,但实际上可能非常复杂。在LangChain中,有多个构建模块可用于处理这个步骤。
要实现数据的获取,您可以使用LangChain提供的以下模块之一:
- 数据爬取模块:LangChain提供了用于从互联网上爬取数据的模块。您可以指定要爬取的网站和相关的搜索条件,然后将获取到的数据用于后续的生成步骤。
- 数据库连接模块:LangChain还提供了与各种数据库进行连接的模块。您可以使用这些模块来检索和获取存储在数据库中的特定数据。
- API调用模块:如果您的数据存储在外部API中,LangChain提供了与API进行交互的模块。您可以使用这些模块来调用API并获取所需的数据。
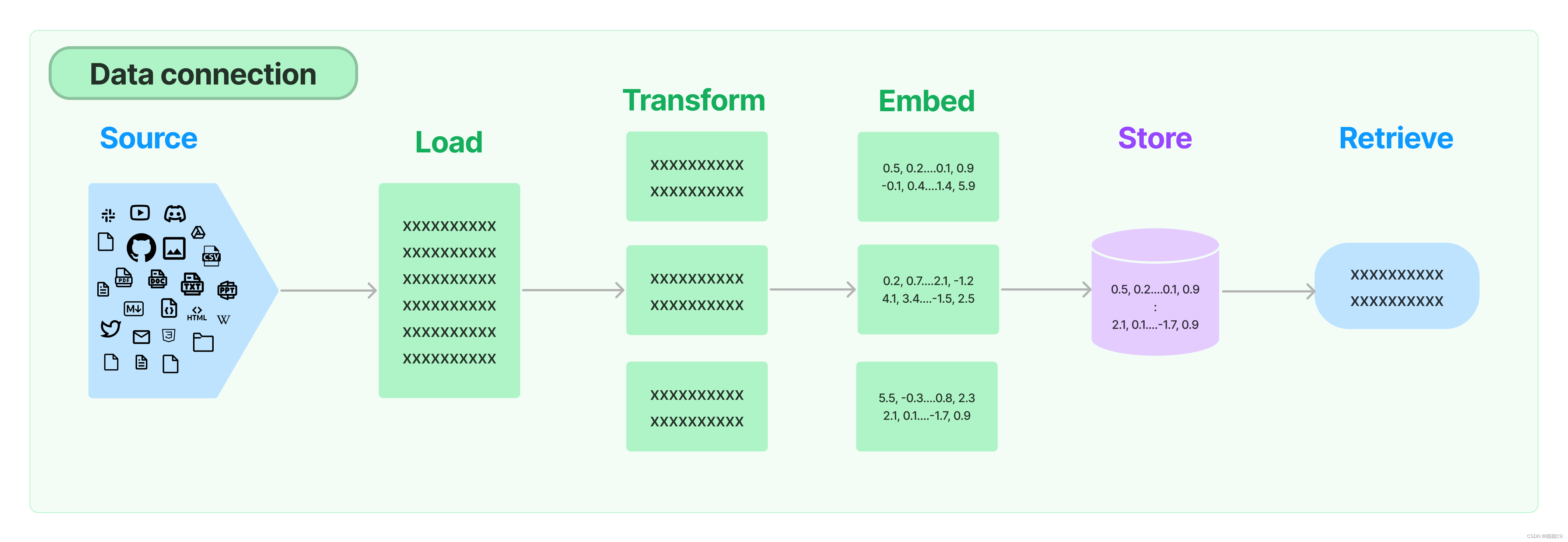
关于rag的组成
-
Document loaders
从许多不同的来源加载文档。LangChain提供了100多种不同的文档加载器,以及与其他主要提供商(如AirByte和Unstructured)的集成。我们提供了加载各种类型文档(HTML、PDF、代码)的集成,可以从各种位置(私有S3存储桶、公共网站)加载。
-
Document transformers
在检索过程中,只获取文档的相关部分是关键。这涉及到几个转换步骤,以便最好地准备文档进行检索。其中一个主要步骤是将大型文档拆分为较小的块。LangChain提供了几种不同的算法来完成这个任务,并针对特定的文档类型(代码、Markdown等)进行了优化。
-
Text embedding models
检索的另一个关键部分是为文档创建嵌入。嵌入捕捉文本的语义含义,使您能够快速高效地找到其他相似的文本。LangChain与25多个不同的嵌入提供商和方法进行了集成,从开源到专有API,让您可以选择最适合您需求的方法。LangChain提供了一个标准接口,方便您轻松切换模型。
-
Vector stores
随着嵌入的兴起,出现了对数据库支持这些嵌入的高效存储和搜索的需求。LangChain与50多个不同的向量存储进行了集成,从开源的本地存储到云托管的专有存储,让您可以选择最适合您需求的方法。LangChain提供了一个标准接口,方便您轻松切换向量存储。
-
Retrievers
一旦数据存储在数据库中,您仍然需要检索它。LangChain支持许多不同的检索算法,并且在这方面为您增加了最大的价值。我们支持易于入门的基本方法,即简单的语义搜索。但是,我们还在此基础上添加了一系列算法以提高性能。其中包括:
父文档检索器:允许您为每个父文档创建多个嵌入,以便您可以查找较小的块但返回更大的上下文。
自查询检索器:用户的问题通常包含对不仅仅是语义的内容的引用,而是表示一些逻辑的元数据过滤器。自查询允许您从查询中解析出语义部分,并排除其他存在于查询中的元数据过滤器。
集合检索器:有时您可能希望从多个不同的来源或使用多个不同的算法检索文档。集合检索器允许您轻松实现这一点。
二、文档加载器
文档加载器,加载各类文件,本节介绍常用的
更多参考:https://python.langchain.com/docs/integrations/document_loaders/
1、TextLoader
from langchain.document_loaders import TextLoader
loader = TextLoader("./test.md")
documents = loader.load()
它支持
- 纯文本文件(.txt)
- Markdown文件(.md)
- JSON文件(.json)
- XML文件(.xml)
- CSV文件(.csv)
- HTML文件(.html)
- PDF文件(.pdf)
- Word文档(.docx)
- PowerPoint演示文稿(.pptx)
- Excel电子表格(.xlsx)
- 日志文件(.log)
- 配置文件(.ini、.yaml、.properties等)
TextLoader还可以加载从Web页面、API响应或其他数据源中提取的文本内容。它提供了灵活的接口和配置选项,以适应各种文本加载需求。
文件名称为中文可能会加载错误默认情况下,TextLoader任何文档加载失败都会导致整个加载过程失败,并且不会加载任何文档。
2、csv
创建一个csv
import pandas as pd
df = pd.DataFrame(
data={
'name': ['wenwenc9', 'laowan'],
'age': [18, 20],
'love': ['python', 'java,go']
},
index=['0', ],
)
df.to_csv('test3.csv')
利用这个加载器加载csv
from langchain.document_loaders import CSVLoader
loader = CSVLoader(file_path='../docs/test3.csv')
documents = loader.load()
loader2 = CSVLoader(file_path='../docs/test3.csv', csv_args={
'delimiter': ',', # 指定CSV文件中的字段分隔符,默认为逗号(,)
'quotechar': '"', # 指定CSV文件中的引号字符,默认为双引号(")
'fieldnames': ['name', 'age', 'love'] # 指定CSV文件中的字段名称列表,用于解析CSV文件的每一行数据。
})
documents2 = loader2.load()
3、文件夹加载器
加载指定文件夹下的文档
glob参数用于指定该文件下的何种文件
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader('../docs', glob='**/*.txt')
documents = loader.load()
默认情况下不会显示文件加载进度,要使用进度,先安装 tqdm
pip install tqdm
loader = DirectoryLoader('../docs', glob='**/*.txt',show_progress=True)
documents = loader.load()

当然这个加载器可以加载其它格式的文件
DirectoryLoader(....., loader_cls=PythonLoader)
有些时候想加载文件夹中,某些特定文件,可以选择指定加载器,比如只加载pdf文件
可以使用PDFLoader作为loader_cls
DirectoryLoader(....., loader_cls=PDFLoader)
默认情况下,如果文件下的文件无法识别,会导致加载错误,导致文件加载中断。
那么可以设置,遇到错误跳过,继续加载剩余文档
loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader, silent_errors=True)docs = loader.load()
可以在加载文件的时候,自动检测文件编码
text_loader_kwargs={'autodetect_encoding': True}loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader, loader_kwargs=text_loader_kwargs)docs = loader.load()
4、html
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader("example_data/fake-content.html")
data = loader.load()
还额可以用使用BeautifulSoup4使用BSHTMLLoader. 这将从 HTML 中提取文本到page_content,并将页面标题title提取到metadata
from langchain.document_loaders import BSHTMLLoader
loader = BSHTMLLoader("example_data/fake-content.html")
data = loader.load()
5、json
以下案例以这个json结构演示
{
'messages': [
{
'content': '你好!',
'sender_name': 'User 2',
'timestamp_ms': 1675597571851
},
{
'content': '这里有些问题',
'sender_name': 'User 1',
'timestamp_ms': 1675597435669
}
]
}
支持使用jq进行取数
pip install jq
JSON -> [{“text”: …}, {“text”: …}, {“text”: …}] jq_schema
-> “.[].text”JSON -> {“key”: [{“text”: …}, {“text”: …}, {“text”: …}]}
jq_schema -> “.key[].text”JSON -> [“…”, “…”, “…”] jq_schema -> “.[]”
from langchain.document_loaders import JSONLoader
loader = JSONLoader(
file_path='../docs/test.json',
jq_schema='.messages[].content') # 具体语法参考 https://jqlang.github.io/jq/manual/
data = loader.load()
读取指定键值对
loader = JSONLoader(file_path='../docs/test.json',
jq_schema='.content', # 读取key 为 content的数据
json_lines=True # 设置按行读取
)
data = loader.load()
也可以通过这样读取
loader = JSONLoader(file_path='../docs/test.json',
jq_schema='.',
content_key='sender_name',
json_lines=True)
data = loader.load()
内嵌函数提取数据
def metadata_func(record: dict, metadata: dict) -> dict:
metadata["sender_name"] = record.get("sender_name")
metadata["timestamp_ms"] = record.get("timestamp_ms")
return metadata
loader = JSONLoader(
file_path='../docs/test.json',
jq_schema='.messages[]',
content_key="content",
metadata_func=metadata_func
)
data = loader.load()
6、Markdown
from langchain.document_loaders import UnstructuredMarkdownLoader
markdown_path = 'xxxx'
loader = UnstructuredMarkdownLoader(markdown_path)
documents = loader.load()
# 默认情况下读取的内容是整合在一起的,可以选择保留元素 mode="elements"
7、PDF
7.1 PyPDF
这个包可以加载的pdf有分页功能
pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("../docs/2120383130.pdf")
# pages = loader.load()
pages = loader.load_and_split()
# 可以从文件夹加载内容
from langchain.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader("example_data/")
使用OpenAi中embedding进行检索
pip install faiss-gpu
pip install faiss-cpu # 如果不支持GPU 那么使用CPU
# https://zhuanlan.zhihu.com/p/357414033
在一堆文件中,寻找问题最相似的文件所在位置,我在docs下有很多txt文件,其中一个有带有问题相关

from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader('../docs', glob='**/*.txt')
pages = loader.load()
# print(pages)
# 配合 OpenAi的 embedding 检索文件
from langchain.vectorstores import FAISS # Facebook AI Similarity Search
from langchain.embeddings.openai import OpenAIEmbeddings
faiss_index = FAISS.from_documents(pages, OpenAIEmbeddings())
docs = faiss_index.similarity_search("稳稳", k=1) # k值代表从检索中返回多少个相关的文件
print(docs)

7.2 Mathipix
https://docs.mathpix.com/#introduction # 要钱的这个
from langchain.document_loaders import MathpixPDFLoader
loader = MathpixPDFLoader("../docs/2120383130.pdf")
7.3 UnstructuredPDFLoader
from langchain.document_loaders import UnstructuredPDFLoader
loader = UnstructuredPDFLoader("example_data/layout-parser-paper.pdf")
# 可以在加载器中 mode="elements" 选择保留文档原结构
7.4 OnlinePDFLoader
from langchain.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://arxiv.org/pdf/2302.03803.pdf")
data = loader.load()
7.5 其它第三方集成
from langchain.document_loaders import (
PyPDFium2Loader # https://github.com/pypdfium2-team
PDFMinerLoader # https://github.com/euske/pdfminer
)
其中PDFMinerLoader 对于生成HTML结构的PDF很有帮助
from langchain.document_loaders import PDFMinerPDFasHTMLLoader
import re
from bs4 import BeautifulSoup
loader = PDFMinerPDFasHTMLLoader("../docs/2120383130.pdf")
data = loader.load()[0] # 整个PDF作为单个文档加载
# 提取内容
soup = BeautifulSoup(data.page_content, 'html.parser')
content = soup.find_all('div')
#
cur_fs = None
cur_text = ''
snippets = [] # first collect all snippets that have the same font size
for c in content:
sp = c.find('span')
if not sp:
continue
st = sp.get('style')
if not st:
continue
fs = re.findall('font-size:(\d+)px', st)
if not fs:
continue
fs = int(fs[0])
if not cur_fs:
cur_fs = fs
if fs == cur_fs:
cur_text += c.text
else:
snippets.append((cur_text, cur_fs))
cur_fs = fs
cur_text = c.text
snippets.append((cur_text, cur_fs))
上面的代码用于从PDF文件中提取内容,并按照字体大小将内容分割成片段。具体来说,代码使用PDFMinerPDFasHTMLLoader库加载PDF文件,并将整个PDF作为单个文档加载。然后,使用BeautifulSoup库解析HTML内容,并找到所有的
总结起来,上面的代码用于将PDF文件中的内容按照字体大小分割成片段,以便进一步处理和分析。
上面代码是简单的处理,实际还可以写更多的处理方式
from langchain.docstore.document import Document
cur_idx = -1
semantic_snippets = []
for s in snippets:
if not semantic_snippets or s[1] > semantic_snippets[cur_idx].metadata['heading_font']:
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
continue
if not semantic_snippets[cur_idx].metadata['content_font'] or s[1] <= semantic_snippets[cur_idx].metadata['content_font']:
semantic_snippets[cur_idx].page_content += s[0]
semantic_snippets[cur_idx].metadata['content_font'] = max(s[1], semantic_snippets[cur_idx].metadata['content_font'])
continue
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
这段代码的作用是将之前提取的内容片段(snippets)根据字体大小进行语义分组。具体来说,代码通过遍历每个片段(snippets),根据字体大小判断是否属于同一节(section)或新的标题(heading)。代码的逻辑如下:
- 如果当前片段的字体大小大于前一个节的标题字体大小(或者是第一个片段),则将当前片段视为新的标题,创建一个新的Document对象,并将其添加到semantic_snippets列表中。同时更新当前节的索引(cur_idx)。
- 如果当前片段的字体大小小于等于前一个节的内容字体大小(或者是第一个片段),则将当前片段的内容添加到当前节的page_content中,并更新当前节的内容字体大小为当前片段字体大小。
- 如果当前片段的字体大小大于前一个节的内容字体大小但小于前一个节的标题字体大小,则将当前片段视为新的标题,创建一个新的Document对象,并将其添加到semantic_snippets列表中。同时更新当前节的索引(cur_idx)。
总结起来,这段代码的目的是根据字体大小将提取的内容片段进行语义分组,将具有相同或类似字体大小的内容归为同一节或标题,并将其存储在semantic_snippets列表中的Document对象中。
7.6 PyMuPDFLoader
这是最快的PDF解析器,包含有关PDF及其页面的详细元数据,并且每页返回一个文档,能初步返回部分key的键值
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("../docs/2120383130.pdf")
data = loader.load()
7.8 PDFPlumberLoader
跟PyMuPDFLoader 差不多,也能返回一些键值内容
7.9 AmazonTextractPDFLoader
AmazonTextractPDFLoader 调用Amazon Textract Service将 PDF 转换为文档结构。该加载程序目前执行纯 OCR,并根据需求计划提供更多功能,例如布局支持。支持最多 3000 页和 512 MB 大小的单页和多页文档。
为了使调用成功,需要一个 AWS 账户,类似于AWS CLI要求。
除了 AWS 配置之外,它与其他 PDF 加载器非常相似,同时还支持 JPEG、PNG 和 TIFF 以及非原生 PDF 格式。
from langchain.document_loaders import AmazonTextractPDFLoader
loader = AmazonTextractPDFLoader("example_data/XXX.pdf")
documents = loader.load()
二、文档转换器
Document transformers 文档转换器,正常来说,加载了文件想对其进行各种各样的处理,然后才能正常使用
参考:
https://python.langchain.com/docs/integrations/document_transformers/
当需要处理GPT的有限制token字节数的情况时,几M的文件需要进行文本切割然后提交处理。推荐使用RecursiveCharacterTextSplitter这款文本拆分器,它采用字符列表,根据第一个字符来进行分割,创建块,如果任何块太大,它就会移动到下一个字符,依次类推。尝试分割的字符是[“\n\n”, “\n”, " ", “”],除了可以控制可以分割的字符之外,还可以控制其它一些参数。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
length_function=len, # 表示使用len函数计算长度
\n
)
with open('../docs/知识2.txt', encoding='utf-8') as f:
datas = f.read()
texts = text_splitter.create_documents([datas])
1、文本分割
1.1 字符分割
这是最简单的方法。这是基于字符(默认’\n\n’)进行分割,并按字符数测量块长度。
1、文本可以通过单个字符来进行分割;
2、可以通过计算字符数来测量块的大小。
# 加载长文本
with open('../docs/我有一剑10章.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n", # 指定TextSplitterTextSplitter分隔符
chunk_size=200, # 指定每个块的大小(以字符为单位)。在这个例子中,每个块的大小是200个字符。
chunk_overlap=50, # 指定块之间的重叠部分的大小(以字符为单位)。在这个例子中,块之间的重叠部分大小是200个字符。
length_function=len,
is_separator_regex=False, # 表示是否识别separator为正则规则
add_start_index=True, # 截断索引
)
texts = text_splitter.create_documents([state_of_the_union])
print(len(texts))
print(texts[0])
"""
chunk_overlap
这个是指切割后的每个 document 里包含几个上一个 document 结尾的内容,
主要作用是为了增加每个 document 的上下文关联。比如,chunk_overlap=0时,
第一个 document 为 aaaaaa,第二个为 bbbbbb;当 chunk_overlap=2 时,
第一个 document 为 aaaaaa,第二个为 aabbbbbb。
不过,这个也不是绝对的,要看所使用的那个文本分割模型内部的具体算法。
"""

将文档进行分割,并且添加元数据标记,可以用于字段新增
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=metadatas)
print(documents[0])
首先,定义了一个名为metadatas的列表,其中包含两个字典元素。每个字典元素代表一个文档的元数据,其中"document"键表示文档的编号。
然后,使用text_splitter对象的create_documents方法来将文本进行分割并创建文档。在这个例子中,使用了两个相同的state_of_the_union文本作为输入,并将metadatas列表作为metadatas参数传递给create_documents方法。
最后,通过打印documents列表的第一个元素来查看分割后的文档。每个文档是一个字符串,表示分割后的文本块。

1.2 拆分代码
查看支持拆分代码的语种
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)
print([e.value for e in Language])
演示拆分Python代码
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
1.3 拆分markdown
MarkdownHeaderTextSplitter
from langchain.text_splitter import MarkdownHeaderTextSplitter
# 读取makdown文件
with open('../docs/demo1.md', encoding='utf-8') as f:
markdown_document = f.read()
# 设置markdown标题识别
headers_to_split_on = [
('#', "Header 1"),
('##', "Header 2"),
('###', "Header 3"),
]
# 创建分割应用
markdown_spliter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# 进行分割
md_splited = markdown_spliter.split_text(markdown_document)
print(md_splited)
print(type(md_splited[0]))
下面共计14个doc
[Document(page_content='这个标题描述的是水果的种类', metadata={'Header 1': '水果'}),
Document(page_content='苹果也分大小', metadata={'Header 1': '水果', 'Header 2': '苹果'}),
Document(page_content='更好吃', metadata={'Header 1': '水果', 'Header 2': '苹果', 'Header 3': '大苹果'}),
Document(page_content='更难吃', metadata={'Header 1': '水果', 'Header 2': '苹果', 'Header 3': '小苹果'}),
Document(page_content='西瓜也大小', metadata={'Header 1': '水果', 'Header 2': '西瓜'}),
Document(page_content='超级甜', metadata={'Header 1': '水果', 'Header 2': '西瓜', 'Header 3': '大西瓜'}),
Document(page_content='一般般', metadata={'Header 1': '水果', 'Header 2': '西瓜', 'Header 3': '小西瓜'}),
Document(page_content='这个标题是描述的是植物的种类', metadata={'Header 1': '植物'}),
Document(page_content='榕树也有大小', metadata={'Header 1': '植物', 'Header 2': '榕树'}),
Document(page_content='可以遮挡风雨', metadata={'Header 1': '植物', 'Header 2': '榕树', 'Header 3': '大榕树'}),
Document(page_content='遮挡不住风雨', metadata={'Header 1': '植物', 'Header 2': '榕树', 'Header 3': '小榕树'}),
Document(page_content='鲜花当然也属于植物', metadata={'Header 1': '植物', 'Header 2': '鲜花'}),
Document(page_content='送给老婆', metadata={'Header 1': '植物', 'Header 2': '鲜花', 'Header 3': '红玫瑰'}),
Document(page_content='送给女朋友', metadata={'Header 1': '植物', 'Header 2': '鲜花', 'Header 3': '郁金香'})]
<class 'langchain.schema.document.Document'>
MarkdownHeaderTextSplitter中不可以设置根据字符直接切割
结合RecursiveCharacterTextSplitter进行切割
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=5, chunk_overlap=3
)
res2 = text_splitter.split_documents(md_splited)
print(res2)
print(len(res2))
可以看到切割出来的documents变多了

1.4 根据tokens拆分
- 正常切割会超过设置chunk_size 基本上是根据字符语义拆解的
- 如果要保证用token数目进行切割,那么使用这个
基本上模型的调用,都是需要tokens计费的,这里切割按照模型的设置临界值
# 加载长文本
with open('../docs/我有一剑10章.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(state_of_the_union)
print(texts)
请注意,如果使用CharacterTextSplitter.from_tiktoken_encoder,文本仅会被CharacterTextSplitter分割,而tiktoken分词器则用于合并分割后的结果。这意味着分割后的文本长度可能超过tiktoken分词器所允许的块大小。
为解决这个问题,我们可以使用RecursiveCharacterTextSplitter.from_tiktoken_encoder来进行分割,以确保每个分割后的文本块大小不超过语言模型所允许的最大标记块大小。
如果某个分割后的文本块大小超过了语言模型所允许的最大标记块大小,则会递归地进行进一步的分割,以确保每个分割后的文本块大小都不会超过最大标记块大小。
另外,我们也可以直接加载一个tiktoken splitter,这样可以确保每个分割后的文本块大小都不会超过语言模型所允许的最大标记块大小。
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
在Langchain中,CharacterTextSplitter.from_tiktoken_encoder和TokenTextSplitter是用于文本拆分的两种不同方法。
CharacterTextSplitter.from_tiktoken_encoder是基于字符级别的拆分方法,它使用了tiktoken编码器。这种方法将文本视为字符序列,并根据字符的编码将文本拆分成片段。每个片段的长度由字符数确定。
TokenTextSplitter是基于标记级别的拆分方法。它使用了Langchain中的分词器,可以是单词、子词或字符级别的分词器。这种方法将文本视为标记序列,并根据标记的数量将文本拆分成片段。每个片段的长度由标记数确定。
这两种方法的区别在于拆分的粒度不同。CharacterTextSplitter.from_tiktoken_encoder基于字符级别进行拆分,而TokenTextSplitter基于标记级别进行拆分。选择使用哪种方法取决于具体的应用场景和需求。如果需要更细粒度的控制,可以使用CharacterTextSplitter.from_tiktoken_encoder;如果需要基于语义单元进行拆分,可以使用TokenTextSplitter。
1.5 Spacy
spaCy是一个用于高级自然语言处理的开源软件库,用编程语言 Python 和 Cython 编写。
另一种替代方法NLTK是使用spaCy tokenizer。
from langchain.text_splitter import SpacyTextSplitter
text_spliter = SpacyTextSplitter(chunk_size=1000)
texts = text_spliter.split_text(state_of_the_union)
# 会超过1000,因为语义切割了,但是保留了换行等

这SentenceTransformersTokenTextSplitter是一个专门的文本分割器,与句子转换器模型一起使用。默认行为是将文本分割成适合您要使用的句子转换器模型的标记窗口的块。
要使用GPU
# 加载长文本
with open('../docs/我有一剑10章.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
from langchain.text_splitter import SentenceTransformersTokenTextSplitter
splitter = SentenceTransformersTokenTextSplitter(chunk_overlap=0)
text = "Lorem "
count_start_and_stop_tokens = 2
text_token_count = splitter.count_tokens(text=text) - count_start_and_stop_tokens
print(text_token_count)
1.6 NLTK
自然语言分割,不仅仅是\n\n进行分割
https://www.nltk.org/py-modindex.html
# 加载长文本
with open('../docs/我有一剑10章.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
1.7 hugging face
https://huggingface.co/docs/tokenizers/index
2、文章检索 长上下文
Post retrieval
下面这个案例意思是,
比如我有一个小说有很长的内容1M
现在提取出一个问题,“萧炎在什么时候获取的青莲地火的”
正常来说,是对1M进行文本切割,然后在对document对象进行检索,这样非常的慢
那么可以利用如下LongContextReorder,对问题注入然后文本重新排序,然后进行提问,这样就会非常快
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_transformers import (
LongContextReorder,
)
from langchain.chains import StuffDocumentsChain, LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# Get embeddings.
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
texts = [
"巴斯克球是一项伟大的运动",
"飞我到月球是我最喜欢的歌曲之一",
"凯尔特人队是我最喜欢的球队",
"这是一份关于波士顿凯尔特人队的文件",
"我就是喜欢看电影",
"波士顿凯尔特人队以20分的优势赢得了比赛",
"这只是一个随机文本",
"Elden Ring是过去15年来最好的游戏之一",
"科内特是凯尔特人最好的球员之一",
"拉里·伯德是NBA的标志性球员.",
]
# 创建一个检索文件库
retriever = Chroma.from_texts(texts, embedding=embeddings).as_retriever(
search_kwargs={"k": 10}
)
query = "关于凯尔特人,你能告诉我什么?"
# 按相关性得分排序获取相关文档
docs = retriever.get_relevant_documents(query)
print('\n 第一种', docs)
# 重新排序文档:
# 不太相关的文档将位于列表的中间,而更多
# 开始/结束时的相关元素。
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
"""
reorder = LongContextReorder(
max_tokens=2048, # 限制最大令牌数
stride=512, # 步幅
context_size=1024, # 上下文大小
padding_strategy="longest", # 填充策略
)
"""
print('\n 第二种', reordered_docs)
# 准备并运行一个自定义的Stuff链,将重新排序的文档作为上下文。
# 替代提示
document_prompt = PromptTemplate(
input_variables=["page_content"], template="{page_content}"
)
document_variable_name = "context"
llm = OpenAI()
stuff_prompt_override = """给定此文本摘录:
-----
{context}
-----
请回答以下问题:
{query}"""
prompt = PromptTemplate(
template=stuff_prompt_override, input_variables=["context", "query"]
)
# 实例化链
llm_chain = LLMChain(llm=llm, prompt=prompt)
chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt,
document_variable_name=document_variable_name,
)
res = chain.run(input_documents=reordered_docs, query=query)
print('\n 第三种', res)

三、文本嵌入模型
文本嵌入模型 Text embedding models
https://python.langchain.com/docs/integrations/text_embedding/
加载文档后,通常会想要对其进行转换以更好地适合应用程序。最简单的例子是,可能希望将长文档分割成更小的块,以适合模型的上下文窗口。LangChain 有许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。
1、CacheBackedEmbeddings
使用 CacheBackedEmbeddings.from_bytes_store() 方法创建一个 CacheBackedEmbeddings 实例。这个类是一个嵌入器的包装器,它在计算嵌入向量时会先检查缓存(在这里是 InMemoryStore)。如果缓存中存在相应的嵌入向量,则直接返回缓存的结果,否则使用底层的 OpenAIEmbeddings 实例计算嵌入向量并将其存储到缓存中。这可以提高性能,特别是对于重复计算相同文本的嵌入向量的情况。namespace 参数用于避免在缓存中发生冲突,例如当使用不同的嵌入模型时。
from langchain.storage import InMemoryStore, LocalFileStore, RedisStore
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# 一定要设置该namespace参数,以避免使用不同嵌入模型嵌入的相同文本发生冲突。
# 这个其实选择embedding模型
underlying_embeddings = OpenAIEmbeddings()
# 实例化向量文件存储目录
fs = LocalFileStore('./cache/')
# CacheBackedEmbeddings 用于缓存嵌入模型结果的接口对象
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, # 用户计算的嵌入器
fs, # 用于缓存文档嵌入的存储
namespace=underlying_embeddings.model # 以避免使用不同嵌入模型嵌入的相同文本发生冲突
)
# 进行缓存前,可以看到数据为空
datas = list(fs.yield_keys())
#### 开始处理一些文档存储到向量数据库中
# 加载文件,简单切割处理
raw_documents = TextLoader("../../docs/我有一剑10章.txt", encoding='utf-8').load()
text_spliter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
documents = text_spliter.split_documents(raw_documents)
# 创建向量数据库
# https://api.python.langchain.com/en/latest/vectorstores/langchain.vectorstores.faiss.FAISS.html
# cached_embedder 相同内容情况下,再次生成向量数据库,会非常的快
# 当然如果这里直接使用underlying_embeddings则速度会慢
# 可以直接用 underlying_embeddings 跑2次 对比速度
# 与cached_embedder跑2此 对比速度
db = FAISS.from_documents(documents, underlying_embeddings)
print(db)
print(list(fs.yield_keys())) # text-embedding-ada-002 是向量计算模型

1.1 存储内存中
同样的第二次运行的时候,也是非常的快
from langchain.storage import InMemoryStore
from langchain.embeddings import CacheBackedEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
store = InMemoryStore()
CacheBackedEmbeddings.from_bytes_store(
embeddings,
store,
namespace=embeddings.model
)
res2 = embeddings.embed_documents(['hello', 'goodbye'])
print(res2)

1.2 在本地文件中操作
from langchain.storage import InMemoryStore, LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
fs = LocalFileStore("./test_cache/")
embedder2 = CacheBackedEmbeddings.from_bytes_store(
embeddings, fs, namespace=embeddings.model
)
res = embedder2.embed_documents(["hello", "goodbye"])
print(res)
1.3 Redis
from langchain.storage import RedisStore
from langchain.embeddings import CacheBackedEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
l
store = RedisStore(redis_url="redis://:Bijfa759jfamOOB11@121.5.174.148:12735", client_kwargs={'db': 11},
namespace='embedding_caches')
embeddings = OpenAIEmbeddings()
embedder = CacheBackedEmbeddings.from_bytes_store(
embeddings, store, namespace=embeddings.model
)
res = embedder.embed_documents(["hello", "goodbye"])
print(res)

四、向量数据库
Vector stores
存储和搜索非结构化数据的最常见方法之一是嵌入它并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。矢量存储负责存储嵌入数据并为您执行矢量搜索。

这里介绍一个常用向量数据库
1、Chromadb
1.1 通过相似性搜索
similarity_search
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
source_documents = TextLoader('../../../docs/beiyin.txt', encoding='utf-8').load()
text_spliter = CharacterTextSplitter(
chunk_size=50,
chunk_overlap=0,
separator='\n'
)
documents = text_spliter.split_documents(source_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
query = "父亲给我买了什么"
docs = db.similarity_search(query)
print(docs)

1.2 通过向量搜索
注意:生成向量数据库的embeddings相同的才能作为搜索,如果用openai的,然后用facebook的embedding就会出错,类型不同
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
将chromadb持久化到本地
db = Chroma.from_documents(
documents, OpenAIEmbeddings(),
persist_directory='./chroma_db_demo' # 存储db地址
)

对本地db提问
documents = Chroma(persist_directory='./chroma_db_demo', embedding_function=OpenAIEmbeddings())
docs = documents.similarity_search('父亲给我买了什么?')
print(docs[0].page_content)
"""
我说道,“爸爸,你走吧。”他望车外看了看,说,“我买几个橘子
"""
可以看到回答的就是原文,如何进行情感回复呢?
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff", # 表示使用检索和生成两个步骤来回答问题。首先,系统会从给定的文档中检索相关信息,然后使用语言模型生成答案
retriever=documents.as_retriever(), # 这是一个文档检索器,用于从一组文档中查找与问题相关的信息
return_source_documents=True, # 返回原文
)
res = qa({'query': '父亲给我买了什么?'})
print(res)

2、Faiss
pip install faiss-cpu
2.1 搜索
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../docs/beiyin.txt', encoding='utf-8').load()
text_splitter = CharacterTextSplitter(chunk_size=50,
chunk_overlap=0,
separator='\n')
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
# 通过相似性询问
docs = db.similarity_search('父亲给我买了什么?')
# 向量询问也支持
将db保存到本地
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
raw_documents = TextLoader('../../docs/beiyin.txt', encoding='utf-8').load()
text_splitter = CharacterTextSplitter(chunk_size=50,
chunk_overlap=0,
separator='\n')
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
# 存储本地
db.save_local("faiss_index")
# 加载本地
new_db = FAISS.load_local("faiss_index", OpenAIEmbeddings())
docs = new_db.similarity_search('父亲给我买了什么?')
print(docs)
可以使用异步向量数据库处理,多并发这样可以不用进行等待
query = "父亲给我买了什么"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
五、检索器
Retrievers
在信息检索和自然语言处理任务中,Retrievers(检索器)是一种用于从大量文档中检索与给定查询相关的文档或信息片段的工具。
在 Langchain 这个项目中,Retrievers 的作用是从预先构建的文档向量存储(例如 FAISS)中找到与输入查询最相关的文档或文本片段。
通常,Retrievers 会执行以下步骤:
-
将输入查询转换为向量表示(通常使用词嵌入或预训练的语言模型)。
-
在向量存储中搜索与查询向量最相似的文档向量(通常使用余弦相似度或欧几里得距离等度量方法)。
-
返回与查询最相关的文档或文本片段,以及它们的相似度得分。
1、检索器原理
VectorstoreIndexCreator
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
loader = TextLoader('../../docs/beiyin.txt', encoding='utf8')
index = VectorstoreIndexCreator(
text_splitter=CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=0)
).from_loaders([loader])
print(index)
# 直接返回答案
query = "父亲给我买了什么?"
res = index.query(query)
print(res)
# 返回更多信息 PS:这边是将index代入到gpt询问,如果加载的文本超出了字节,会报错
res2 = index.query_with_sources(query)
print(res2)

index.vectorstore # 向量库对象
index.vectorstore.as_retriever() # 通过langchain是的可以检索向量数据库

实际上在面的方法等同于如下代码,通过此类方法简化
1.将文档分割成块
2.为每个文档创建嵌入
3.在向量存储中存储文档和嵌入
from langchain import OpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
loader = TextLoader('../../docs/beiyin2.txt', encoding='utf8')
# 加载,切割文档
text_splitter =CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=0)
source_documents = loader.load()
documents = text_splitter.split_documents(source_documents)
# 生成向量库
db = Chroma.from_documents(documents, OpenAIEmbeddings())
print(db.as_retriever())
"""
VectorStoreRetriever(tags=['Chroma', 'OpenAIEmbeddings'],
metadata=None, vectorstore=<langchain.vectorstores.chroma.Chroma object at 0x00000269D777BA90>,
search_type='similarity', search_kwargs={})
"""
# 提问
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=db.as_retriever())
res = qa.run('父亲给我买了什么?')

当然,我们可以创建很多不同功能检索器实现对查询数据的时候
进行相关操作
2、多查询检索器
MultiQueryRetriever
基于距离的向量数据库检索方法的优缺点。在检索过程中,会根据距离来查找相似的嵌入文档,但如果有细微变化的查询或嵌入不能很好地捕获数据的语义,检索结果也会受到影响。
为了解决这些问题,通常需要进行及时的工程调整,但手动解决可能会很乏味。
MultiQueryRetriever通过使用LLM从不同角度为给定的用户输入查询生成多个查询,可以自动执行提示调整过程,从而获取更大的一组潜在相关文档。通过这种方式,MultiQueryRetriever可以克服基于距离的检索的一些限制并获得更丰富的结果集。
from langchain.vectorstores import Chroma
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
import logging
# 加载一篇网络文章
loader = WebBaseLoader('http://www.ccview.net/htm/xiandai/zzq/zzqsw003.htm')
data = loader.load()
# 切割内容
text_spliter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_spliter.split_documents(data)
# 生成向量数据库
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# 创建检索器
question = '父亲给我买了什么'
llm = ChatOpenAI(temperature=0)
retrivers_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
# 设置日志
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
# 进行提问
docs = retrivers_from_llm.get_relevant_documents(query='父亲给我买了什么')
print(docs)

上面则是自动生成,的可以看到有3个查询语句
可以用下面的方法,生成自己想要的提示查询器
from langchain.vectorstores import Chroma
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
import logging
# 加载一篇网络文章
loader = WebBaseLoader('http://www.ccview.net/htm/xiandai/zzq/zzqsw003.htm')
data = loader.load()
# 切割内容
text_spliter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_spliter.split_documents(data)
# 生成向量数据库
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# 设置日志
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
from typing import List
from langchain.chains import LLMChain
from pydantic import BaseModel, Field
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
# 创建验证器,对于问题解析成列表
class LineList(BaseModel):
lines: List[str] = Field(description="Lines of text")
class LineListOutputParser(PydanticOutputParser):
def __init__(self) -> None:
super().__init__(pydantic_object=LineList)
def parse(self, text: str) -> LineList:
print(text)
lines = text.strip().split("\n")
return LineList(lines=lines)
output_parser = LineListOutputParser()
QUERY_PROMPT = PromptTemplate(
input_variables=["question"], # 输入参数
template="""你是一个人工智能语言模型助理。你的任务是生成五个
给定用户问题的不同版本,以从向量中检索相关文档
数据库通过生成关于用户问题的多个视角,您的目标是帮助
用户克服了基于距离的相似性搜索的一些限制。
提供这些用换行符分隔的备选问题。
原始问题:{question}""", # 提示模板
)
llm = ChatOpenAI(temperature=0)
# 创建chain链路
llm_chain = LLMChain(
llm=llm,
prompt=QUERY_PROMPT,
output_parser=output_parser,
)
# 创建检索器
retriever = MultiQueryRetriever(
retriever=vectordb.as_retriever(),
llm_chain=llm_chain,
parser_key='lines',
)
docs = retriever.get_relevant_documents(
query="父亲给我买了什么"
)
len(docs)
print(docs)
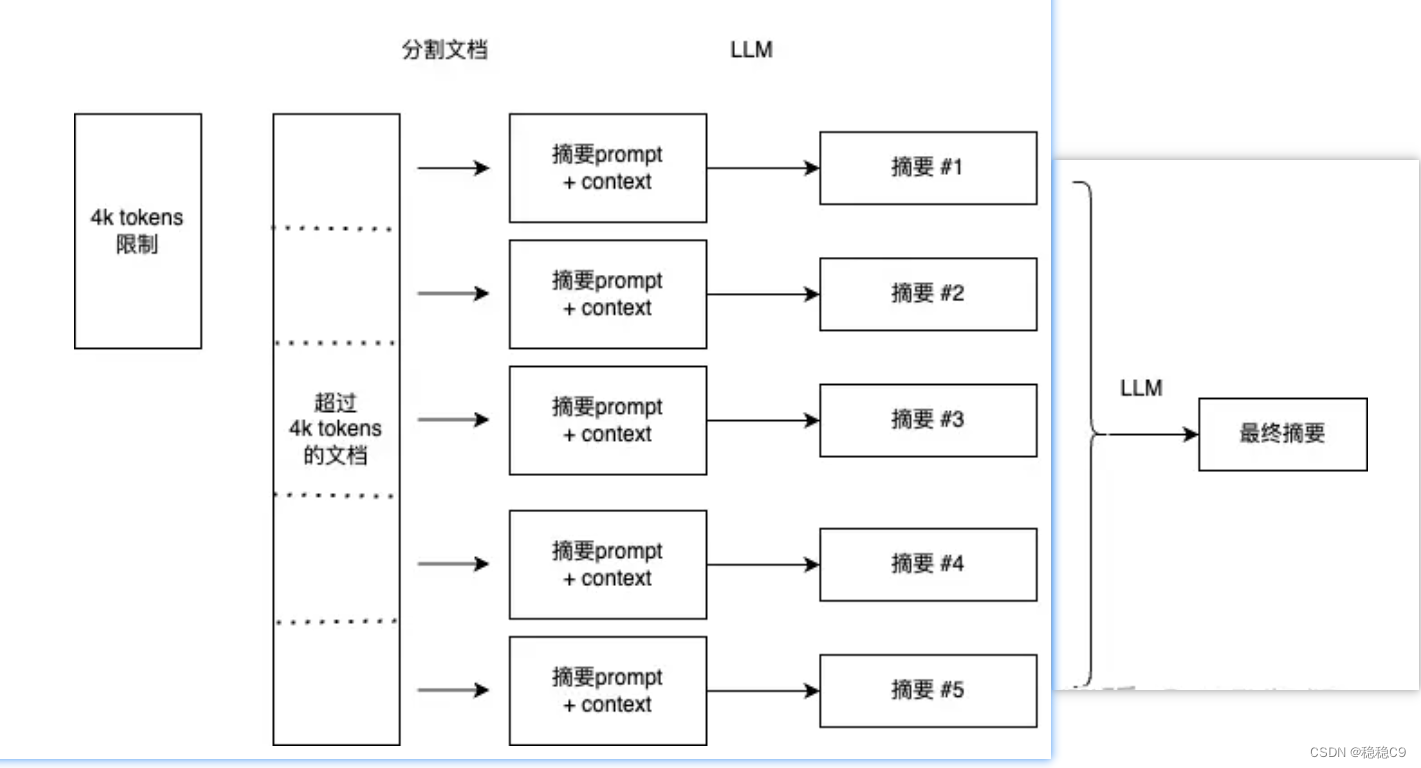
3、上下文压缩
Contextual compression
通常而言,对于数据进行查询的时候,通常而言是对整个数据存储进行“问题”检索,这样会消耗更多时间。
为了解决上面的场景问题:
1.利用检索器
2.使用文档压缩器
过滤出与问题相关文档,其原理如下图

在没有经过压缩的情况下使用检索
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.vectorstores import Chroma
documents = TextLoader('../docs/beiyin.txt', encoding='utf-8').load()
text_spliter = CharacterTextSplitter(chunk_size=200, chunk_overlap=0,separator='\n')
texts = text_spliter.split_documents(documents)
# 构建文档检索器
retriever = Chroma.from_documents(documents=texts, embedding=OpenAIEmbeddings()).as_retriever()
# 查询最相关的内容
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join([f"Document {i + 1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
# 没有经过压缩
docs = retriever.get_relevant_documents('父亲给我买了什么?')
print(pretty_print_docs(docs))

加上,上下文检索器
1.LLMChainExtractor
2.ContextualCompressionRetriever
它将迭代最初返回的文档,并从每个文档中提取与问题相关的内容
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
# 上下文压缩检索包装
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("父亲给我买了什么?")
pretty_print_docs(compressed_docs)
可以看到效果非常明显

3.1 LLMChainFilter
返回一个文档,问题检索不到的话,返回空
使用 LLM 链来决定过滤掉最初检索到的文档中的哪些以及返回哪些文档,而无需操作文档内容。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.llms import OpenAI
from langchain.retrievers.document_compressors import LLMChainFilter
llm = OpenAI(temperature=0.8)
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=_filter, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("家中光景") # 这里替换成 父亲给我买了什么
pretty_print_docs(compressed_docs)
compressed_docs = compression_retriever.get_relevant_documents("父亲给我买了什么")
此时查询不到问题
3.2 EmbeddingsFilter
对于每个生成检索向量的数据,调用LLM,非常耗钱,而且速度会慢。
那么使用EmbeddingsFilter通过嵌入文档和查询并仅返回那些与查询具有足够相似嵌入的文档,提供了更便宜和更快的选项。
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.vectorstores import Chroma
documents = TextLoader('../docs/beiyin.txt', encoding='utf-8').load()
text_spliter = CharacterTextSplitter(chunk_size=200, chunk_overlap=0, separator='\n')
texts = text_spliter.split_documents(documents)
# 构建文档检索器
embeddings = OpenAIEmbeddings()
retriever = Chroma.from_documents(documents=texts, embedding=embeddings).as_retriever()
# 查询最相关的内容
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join([f"Document {i + 1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain.retrievers import ContextualCompressionRetriever
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(base_compressor=embeddings_filter, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("父亲给我买了什么?")
pretty_print_docs(compressed_docs)
3.3 压缩器与文档分割组合
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.vectorstores import Chroma
documents = TextLoader('../docs/beiyin.txt', encoding='utf-8').load()
text_spliter = CharacterTextSplitter(chunk_size=200, chunk_overlap=0, separator='\n')
texts = text_spliter.split_documents(documents)
# 构建文档检索器
embeddings = OpenAIEmbeddings()
retriever = Chroma.from_documents(documents=texts, embedding=embeddings).as_retriever()
# 查询最相关的内容
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join([f"Document {i + 1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
from langchain.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline, EmbeddingsFilter
from langchain.text_splitter import CharacterTextSplitter
from langchain.retrievers import ContextualCompressionRetriever
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(base_compressor=pipeline_compressor, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("父亲给我买了什么?")
pretty_print_docs(compressed_docs)
4、多检索器使用
利用 EnsembleRetriever 可以将多种检索器进行合并使用,常见如下:
1.稀疏检索器(如 BM25)
2.密集检索器(如嵌入相似性)
它们的优势是互补的。它也被称为“混合搜索”。
稀疏检索器擅长根据关键词查找相关文档,而密集检索器擅长根据语义相似度查找相关文档。
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
doc_list = [
"我喜欢苹果",
"我喜欢橘子",
"苹果和橘子都是新鲜水果",
]
# 构建BM25检索器
bm25_retriever = BM25Retriever.from_texts(doc_list)
bm25_retriever.k = 2 # 要返回的文档数量
embedding = OpenAIEmbeddings()
# 构建检索向量
faiss_vectorstore = FAISS.from_texts(doc_list, embedding)
# 构建检索器
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# 组装多检索器
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5])
docs = ensemble_retriever.get_relevant_documents("苹果")
print(docs)

5、多向量检索器
在处理大量文本数据时,通常会将每篇文档表示为一个向量,向量的每个维度代表一个特定的特征或主题。
为了更好地捕捉文档间的相似性和差异,通常会为每个文档创建多个向量。这些向量可以来源于不同的文本块、摘要、或者通过回答假设性问题得到的答案等。
对于如何为每个文档创建多个向量,有以下几种方法:
-
分割文档:将每篇文档分割成较小的块(比如句子或段落),并为每个块分别生成一个向量。这种方法的优点是能够捕捉到文档中的局部信息,比如特定段落或句子所关注的主题。然而,这也增加了模型的复杂性,因为需要处理更多的文本块。
-
创建摘要:为每篇文档创建一个摘要,这个摘要可以是文档内容的压缩形式,或者是对文档主题的总结。然后,可以用这个摘要为文档生成一个向量。这种方法的优点是能够减少需要处理的数据量,并且可以捕捉到文档的主要主题。然而,创建高质量的摘要是一项具有挑战性的任务,需要大量的训练数据和计算资源。
-
回答假设性问题:对于每个文档,提出一些假设性的问题并回答它们。然后,可以用这些问题和答案为文档生成一个向量。这种方法的优点是能够捕捉到文档中隐含的信息,比如文档中没有明确提到的假设或前提。然而,提出好的假设性问题是一项具有挑战性的任务,需要深入理解文档的内容和背景知识。
在实践中,如何选择创建多个向量的方法取决于具体的应用场景和资源限制。例如,如果处理的数据量非常大,可能需要选择能够减少处理复杂性的方法,如创建摘要或回答假设性问题。如果想要更准确地捕捉文档的局部信息,可能需要选择将文档分割成小块的方法。
最后,“手动添加导致文档恢复的问题或查询以获得更多控制权”意味着,在某些情况下,可以自己创建一些问题或查询,这些问题或查询能够引导模型以特定的方式处理文档。这给你提供了更大的灵活性,可以根据需要引导模型专注于文档的特定方面或主题。但是,这也需要更高的专业知识,需要了解如何针对特定任务创建有效的问题或查询。
5.1 使用多向量检查器
step1:加载文档内容
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载文档对对象
loaders = [
TextLoader('../docs/beiyin.txt', encoding='utf-8'), # 朱自清 背影
TextLoader('../docs/htys.txt', encoding='utf-8'), # 朱自清 荷塘月色
]
# 加载对象内容合并到一起
docs = []
for l in loaders:
docs.extend(l.load())
# 文档切割
text_spliter = RecursiveCharacterTextSplitter(chunk_size=200)
docs = text_spliter.split_documents(docs)
step2:切割文本内容为更小的块(设置文本检索和存储的组件和对象)
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
import uuid
# 向量数据库
vectorstore = Chroma(
collection_name="full_documents",
embedding_function=OpenAIEmbeddings()
)
# 文档存储器
store = InMemoryStore()
id_key = "doc_id"
# 组装多向量检索器
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# 创建文档标识符
doc_ids = [str(uuid.uuid4()) for _ in docs]
首先,导入了langchain.embeddings、langchain.retrievers、langchain.storage和langchain.vectorstores模块。
然后,创建了一个名为vectorstore的Chroma对象。Chroma是一个向量存储库,用于存储文档的向量表示。在这里,它使用了OpenAIEmbeddings()函数作为嵌入函数,用于将文本转换为向量。
接着,创建了一个名为store的InMemoryStore对象。InMemoryStore是一个内存中的文档存储器,用于存储文档数据。
定义了一个名为id_key的变量,它被用作文档标识符的键。
创建了一个名为retriever的MultiVectorRetriever对象。MultiVectorRetriever是一个多向量检索器,用于从向量存储库中检索文档。它使用了之前创建的vectorstore和store对象,以及指定的id_key。
最后,通过列表推导式生成了一个名为doc_ids的列表,其中包含了使用uuid.uuid4()函数生成的随机文档标识符。
总体而言,以上代码是在设置和准备一些用于文本检索和存储的组件和对象。具体的功能和用途可能需要进一步的上下文才能确定。
docstore是一个文档存储器,用于存储文档数据。在上述代码中,
docstore是一个InMemoryStore对象,它是一个内存中的文档存储器。
在实际应用中,可以使用不同的文档存储器,例如数据库或文件系统。文档存储器的作用是将文档数据存储在持久化存储中,以便于后续的检索和查询。
在多向量检索器中,文档存储器通常与向量存储库一起使用,以便将文档数据与其向量表示关联起来,并支持根据向量进行检索和查询。
step3:切割文档,赋予文档ID,存储向量数据与文档存储器中
切割文档,进行处理
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = []
for i, doc in enumerate(docs):
_id = doc_ids[i]
_sub_docs = child_text_splitter.split_documents([doc])
for _doc in _sub_docs:
_doc.metadata[id_key] = _id # 构建文档序号属性
sub_docs.extend(_sub_docs) # 追加到一个文档库中
# 新增到向量数据库中
retriever.vectorstore.add_documents(sub_docs)
# 新增到文档存储器中
retriever.docstore.mset(list(zip(doc_ids, docs)))
step4:尝试搜索

尝试搜索
res = retriever.vectorstore.similarity_search('我喜欢什么')
print(len(res))
print(res)
5.2 加入文档摘要
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
import uuid
from langchain.schema.document import Document
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")
| ChatOpenAI(max_retries=0)
| StrOutputParser()
)
这段代码使用LangChain库对中文文档进行自动摘要。它定义了一个处理流程,称为“chain”,包括以下步骤:
输入文档被传递给一个lambda函数,该函数提取其内容。 然后使用内容填充一个提示模板,该模板用中文总结文档。
生成的提示被发送到OpenAI的聊天API以生成摘要。 聊天API的输出被解析为字符串。
最后,将处理流程应用于一批文档,最大并发数为5,并将生成的摘要存储在名为“summaries”的变量中。
完整代码:
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
import uuid
from langchain.schema.document import Document
# 加载文档对对象
loaders = [
TextLoader('../../docs/beiyin.txt', encoding='utf-8'), # 朱自清 背影
TextLoader('../../docs/htys.txt', encoding='utf-8'), # 朱自清 荷塘月色
]
# 加载对象内容合并到一起
docs = []
for l in loaders:
docs.extend(l.load())
# 文档切割
text_spliter = RecursiveCharacterTextSplitter(chunk_size=200)
docs = text_spliter.split_documents(docs)
# 加入文档摘要
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("中文总结如下文档:\n\n{doc}")
| ChatOpenAI(max_retries=0)
| StrOutputParser()
)
summaries = chain.batch(docs, {"max_concurrency": 5})
# 构建检索器
vectorstore = Chroma(
collection_name="summaries",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
# 向量数据库
docstore=store, # 文档存储器
id_key=id_key,
)
# 摘要文档存储到向量库与文档检索器中
doc_ids = [str(uuid.uuid4()) for _ in docs]
summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
print(summary_docs)
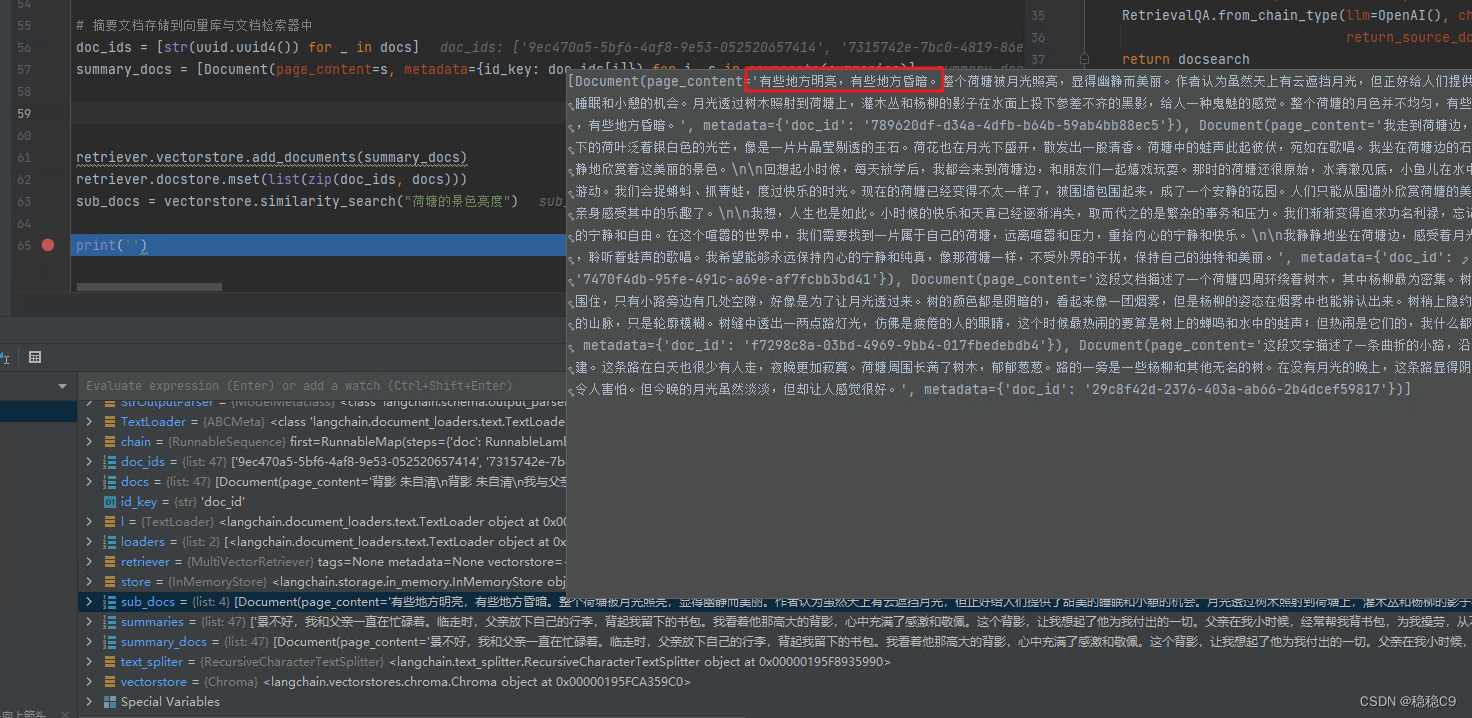
如上是两篇文章,通过打印可以进行观察 summary_docs 文档的摘要

现在尝试进行提问:
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
sub_docs = vectorstore.similarity_search("荷塘的景色亮度")
5.3 针对文档设置假设性问题
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载文档对对象
loaders = [
TextLoader('../../docs/beiyin.txt', encoding='utf-8'), # 朱自清 背影
TextLoader('../../docs/htys.txt', encoding='utf-8'), # 朱自清 荷塘月色
]
# 加载对象内容合并到一起
docs = []
for l in loaders:
docs.extend(l.load())
# 文档切割
text_spliter = RecursiveCharacterTextSplitter(chunk_size=200)
docs = text_spliter.split_documents(docs)
functions = [
{
"name": "hypothetical_questions",
"description": "Generate hypothetical questions",
"parameters": {
"type": "object",
"properties": {
"questions": {
"type": "array",
"items": {
"type": "string"
},
},
},
"required": ["questions"]
}
}
]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
# 理解起来组装起了一个组件
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template(
"Reply in Chinese and Generate a list of 3 hypothetical questions that the below document could be used to answer:\n\n{doc}")
| ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"})
| JsonKeyOutputFunctionsParser(key_name="questions")
)
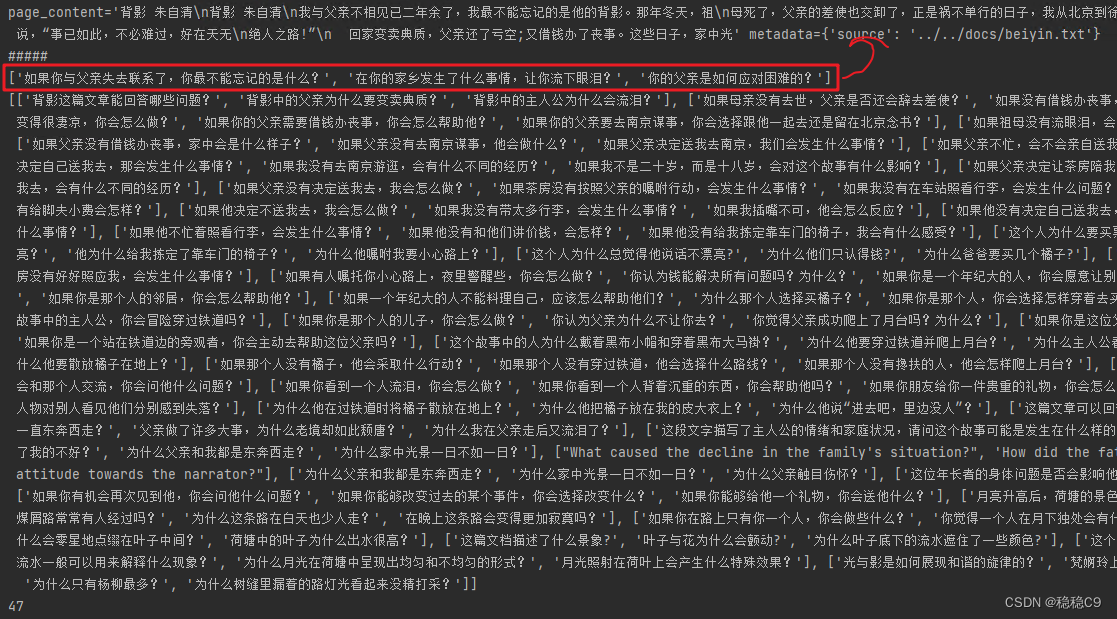
res = chain.invoke(docs[0])
print(docs[0])
print('#' * 5)
print(res)
hy_questions = chain.batch(docs, {"max_concurrency": 5})
print(hy_questions)
print(len(hy_questions))
首先,它使用TextLoader类来加载两个指定的文本文件,这两个文件分别是 “beiyin.txt” 和 “htys.txt”,并指定了文件的编码格式是 ‘utf-8’。
然后,它将加载的文本内容合并到一个名为docs的列表中。
接下来,它使用RecursiveCharacterTextSplitter类将这些文本内容分割成一系列的片段,每个片段的大小是200个字符。
定义了一个函数列表functions,其中包含了一个名为"hypothetical_questions"的函数,这个函数用于生成假设性问题,并指定了该函数的参数格式。
使用JsonKeyOutputFunctionsParser类来解析函数的输出结果。
之后,它构建了一个名为chain的处理链,这个处理链首先将文档内容作为输入,然后使用ChatPromptTemplate生成一个聊天提示模板,然后调用ChatOpenAI对象进行聊天,并指定了函数和函数调用方式,最后使用JsonKeyOutputFunctionsParser来解析函数的输出结果。
最后,它调用了这个处理链的invoke方法来处理第一个文档,并打印出处理结果。然后,它使用batch方法批量处理所有文档,并设置了最大并发数为5。
完善一下代码,加入向量数据库,跟文档检索器进行查找
vectorstore = Chroma(
collection_name="hypo-questions",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 遍历每个文档,对于切后的块,绑定3个假设性问题
question_docs = []
for i, question_list in enumerate(hy_questions):
question_docs.extend([Document(page_content=s, metadata={id_key: doc_ids[i]}) for s in question_list])
# 假设性问题保存到向量数据库中
retriever.vectorstore.add_documents(question_docs)
# 文档存储到文档存储器中
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 提出问题对于,向量数据库找到相关的假设性问题
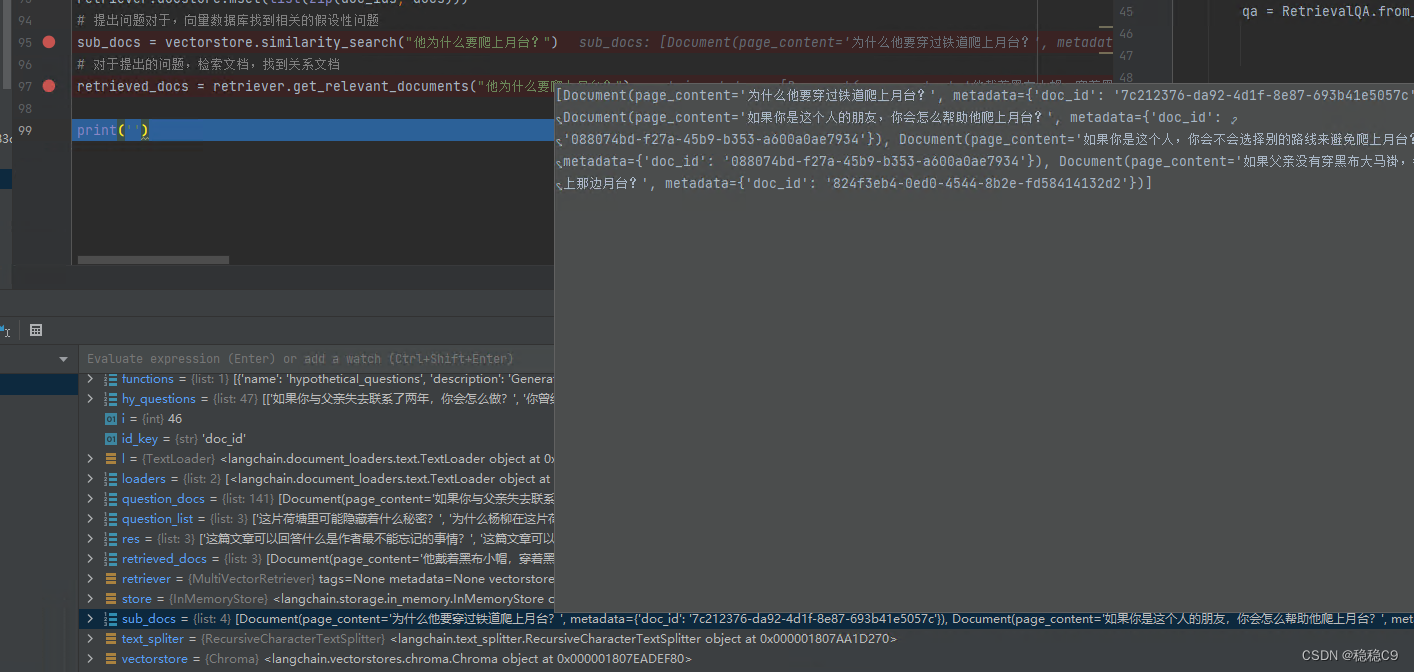
sub_docs = vectorstore.similarity_search("他为什么要爬上月台?")
# 对于提出的问题,检索文档,找到关系文档
retrieved_docs = retriever.get_relevant_documents("他为什么要爬上月台?")
6、父文档检索器
Parent Document Retriever
细粒度的文档块,这样在使用向量模型进行编码的时候,就能更好的表示这个文档块的语义含义,而且这个文档块所含的噪音数据会更少
粗粒度的文档块,当我们召回后需要调用大模型进行生成回答,细粒度的文档块会丢失一些上下文信息,有一定的语义损失
LangChain 中的 Parent Document Retriever
就相当于结合了不同粒度的文本块去构建检索过程,具体的实现流程如下:首先就是使用两个文本分割器去将文本切分为父文档块和子文档块,然后建立向量存储区存储子块,建立内存存储区存储父块。之后我们需要创建
Parent Document Retriever,将上面定义好的分割器、存储器,并执行add_documents
方法将文档添加到检索器中。在使用的时候,调用 get_relevant_documents 方法,这个时候实际上会调用向量检索返回子块的 ID,然后根据子块ID
将对应父块的内容返回给用户。
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# 加载文档对对象
loaders = [
TextLoader('../../docs/beiyin.txt', encoding='utf-8'), # 朱自清 背影
TextLoader('../../docs/htys.txt', encoding='utf-8'), # 朱自清 荷塘月色
]
# 加载对象内容合并到一起
docs = []
for l in loaders:
docs.extend(l.load())
# 创建切割器
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)
# 向量数据库
vectorstore = Chroma(
collection_name="hypo-questions",
embedding_function=OpenAIEmbeddings()
)
# 文档存储器
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
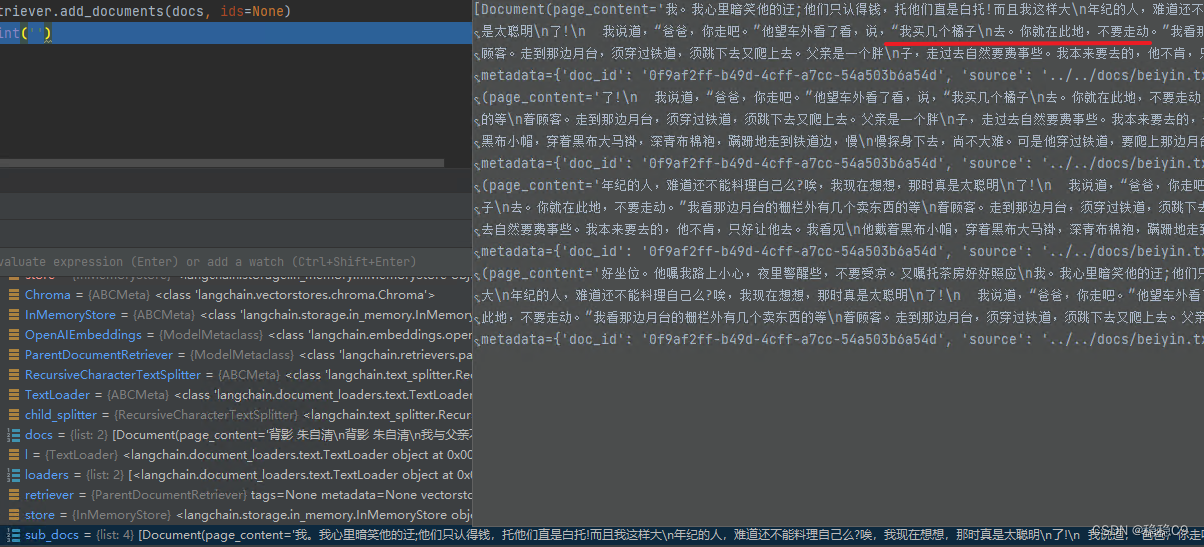
retriever.add_documents(docs, ids=None)
因为是对2个文档进行操作,所以产生了2个key

尝试搜索向量数据库文档
sub_docs = vectorstore.similarity_search("父亲去买了什么")
这个返回的是被切割后的小块文档
返回大块文档
retrieved_docs = retriever.get_relevant_documents("父亲去买了什么")
对于这个文档,字节数也挺大,那么源文档如果更大,那么就会出现问题
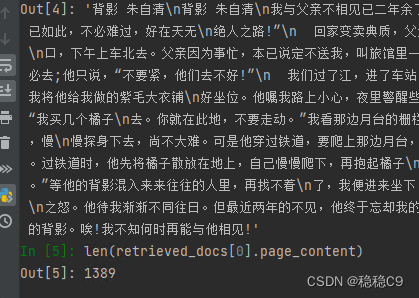
检索更大的文档
为了解决检索更大的源文档,可以对于父文档进行再次切割处理
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# 加载文档对对象
loaders = [
TextLoader('../../docs/beiyin.txt', encoding='utf-8'), # 朱自清 背影
TextLoader('../../docs/htys.txt', encoding='utf-8'), # 朱自清 荷塘月色
]
# 加载对象内容合并到一起
docs = []
for l in loaders:
docs.extend(l.load())
# 创建子切割器
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)
# 创建父文档切割器
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 向量数据库
vectorstore = Chroma(
collection_name="hypo-questions",
embedding_function=OpenAIEmbeddings()
)
# 文档存储器
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter, # 子文档切割器
parent_splitter=parent_splitter, # 父文档切割器
)
# 检索器进行文档存储
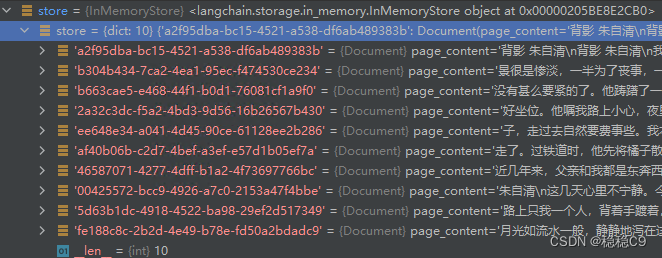
retriever.add_documents(docs, ids=None)
l = len(list(store.yield_keys())) # 源文档
sub_docs = vectorstore.similarity_search("父亲去买了什么")
retriever.get_relevant_documents('父亲去买了什么')
关于stroe,即文档存储器,相对上面没有进行父文档切割(原本存储的是2个),分出了10个
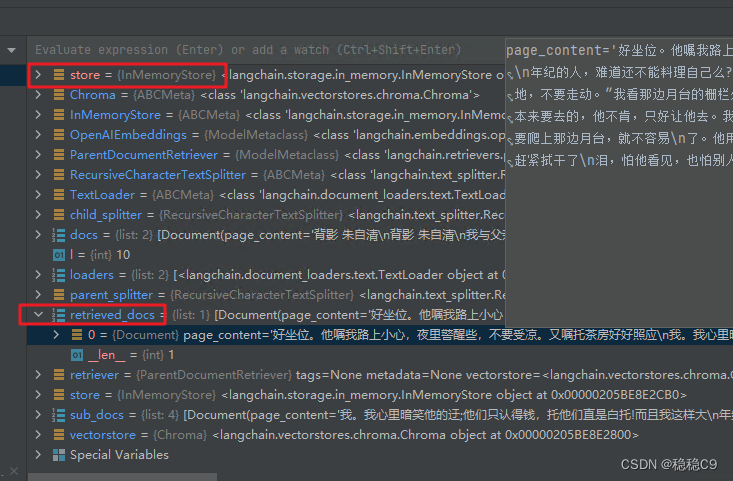
长度上变的更小了,检索出来的源文档

7、自查询
自查询检索器,顾名思义,是一种能够查询自身的检索器。具体来说,给定任何自然语言查询,检索器使用查询构造 LLM 链来编写结构化查询,然后将该结构化查询应用于其底层 VectorStore。这允许检索器不仅使用用户输入的查询与存储的文档的内容进行语义相似性比较,而且还从对存储的文档的元数据的用户查询中提取过滤器并执行这些过滤器。
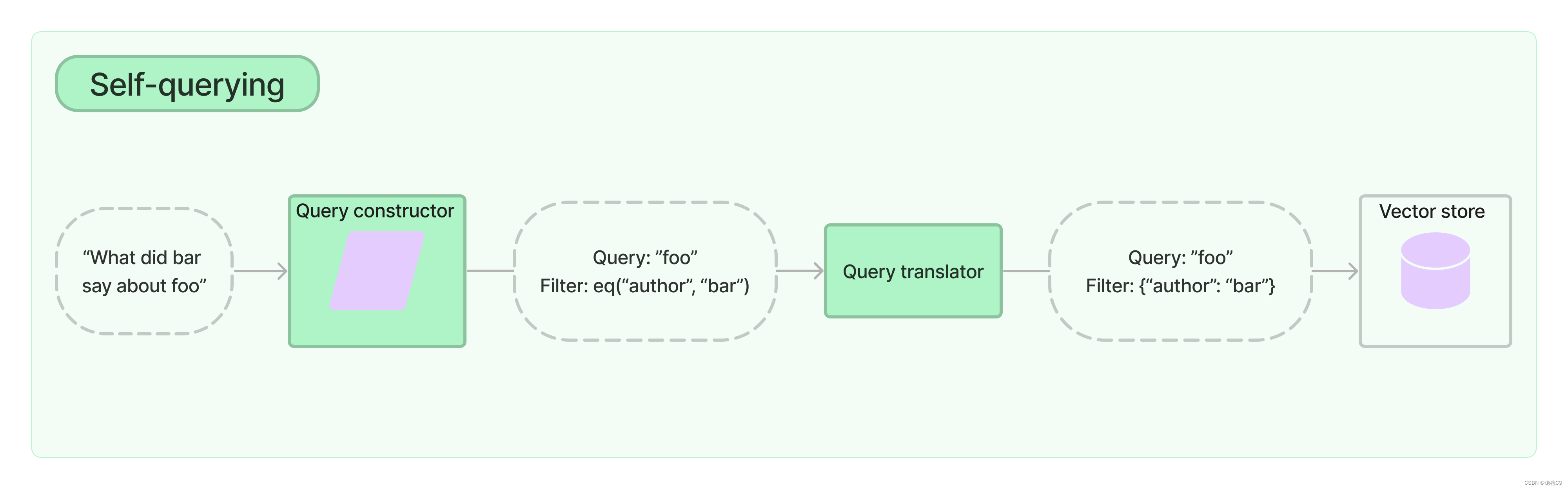
在 Anthropic 的 langchain 模型中,Self-querying 指的是模型可以查询自身的能力。
具体来说,Self-querying 的工作机制是:
1.模型接收到一个需要外部知识才能回答的问题时,它不会直接输出“我不知道”,而是主动生成一个查询语句,向自身进行查询。
2.模型以问答的形式,用生成的查询语句向自身提问,目的是获取问题所需的外部知识。
3.模型用检索到的外部知识来回答原始的问题。
4.如果第一步的查询没有获取到足够的外部知识,模型会递归地生成更多的查询,以便获取更多相关信息。
5.模型会重复上述自查询的过程,直到收集到足够的外部知识来回答原始问题为止。
通过这种自查询的方式,langchain 模型学习到了主动获取外部知识的能力,从而能更好地回答需要依赖大量外部资料才能推理出的复杂问题。这大大增强了模型的知识容量和推理能力。
总之,Self-querying使得langchain不仅可以回答已知的问题,还可以主动查询自身去学习回答原本不知道的问题。这是langchain区别于传统问答系统的一个重要能力。
创建一个电影数据,存储到向量数据库
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.schema.document import Document
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
# 创建示例文档
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,
"rating": 9.9,
"director": "Andrei Tarkovsky",
"genre": "science fiction",
},
),
]
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(docs, embeddings, persist_directory='./chroma_db_movie')
# 加载本地向量数据库
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(embedding_function=embeddings, persist_directory='./chroma_db_movie')
# 预先对文档进行问题字段提醒说明,比如可能会对电影名称,年份,导演,评分
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string or list[string]",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
document_content_description = "Brief summary of a movie"
llm = OpenAI(temperature=0)
# 尝试对文档进行提问
retriever = SelfQueryRetriever.from_llm(
llm, vectorstore, document_content_description, metadata_field_info, verbose=True
)
res = retriever.get_relevant_documents('I want to watch a movie rated higher than 8.5')
控制台看到,有提取出关键词

返回出2个结果

当然也可以设置查询出来的文档数量
enable_limit=True 设置这个即可
SelfQueryRetriever.from_llm(
llm, vectorstore, document_content_description, metadata_field_info, verbose=True, enable_limit=True,
)
在 langchain 中,enable_limit 参数是用于控制是否启用检索文档数量限制的。
langchain 在检索文档时,默认会对检索出的文档数量进行限制,以防止返回过多不相关的文档。这个限制的默认值是20。
enable_limit 参数就用于控制是否启用这个限制:
如果设置为True(默认值),则会启用限制,最多返回20个文档。
如果设置为False,则不启用限制,会返回所有检索到的文档,数量不受限制。
8、时间加权向量检索器
该检索器结合使用语义相似性和时间衰减。
对它们进行评分的算法是:
semantic_similarity + (1.0 - decay_rate) ^ hours_passed
值得注意的是,指的是自上次访问hours_passed检索器中的对象以来经过的小时数,而不是自创建以来经过的小时数。这意味着经常访问的对象保持“新鲜”。
我尝试了chrom。但是好像不行?
衰减
from langchain.schema.document import Document
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from datetime import datetime, timedelta
from langchain.retrievers import TimeWeightedVectorStoreRetriever
from langchain.docstore import InMemoryDocstore
embeddings_model = OpenAIEmbeddings()
# 初始化一个空的向量数据库
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})
# 设置衰减操作
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=.0000000000000000000000001, k=1)
yesterday = datetime.now() - timedelta(days=1)
# 添加内容到库
retriever.add_documents([Document(page_content="hello world,Python", metadata={"last_accessed_at": yesterday})])
retriever.add_documents([Document(page_content="hello world,Java")])
# 检索文档
res = retriever.get_relevant_documents('hello world')
返回的是hello,java,python设置成昨天了

高衰减
如果是高位decay rate(例如,几个 9),recency score很快就会变为 0!如果将其一直设置为 1,则recency所有对象都为 0,这再次相当于向量查找。
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=.999, k=1)
为了方便测试,提供了一些组件进行操作
from langchain.utils import mock_now
import datetime
with mock_now(datetime.datetime(2011, 2, 3, 10, 11)):
print(retriever.get_relevant_documents("hello world"))
9、向量存储支持的检索器
先看最普通的
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
documents = TextLoader('../../docs/htys.txt', encoding='utf-8').load()
text_spiliter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0, separator='\n')
texts = text_spiliter.split_documents(documents)
vectordb = Chroma.from_documents(texts, embedding=OpenAIEmbeddings())
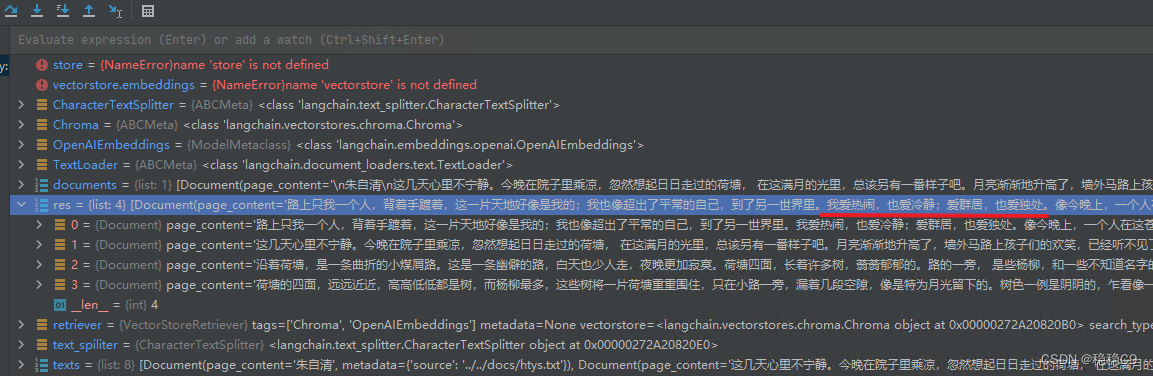
retriever = vectordb.as_retriever()
res = retriever.get_relevant_documents('我爱什么')
9.1 推荐算法
默认情况下,向量存储检索器使用相似性搜索。
如果底层向量存储支持最大边际相关性搜索,可以将其指定为搜索类型。
retriever = vectordb.as_retriever(search_type='mmr')
res = retriever.get_relevant_documents('我爱什么')
可以看到检索出来的东西有不一样的
关于mmr算法
https://zhuanlan.zhihu.com/p/102285855
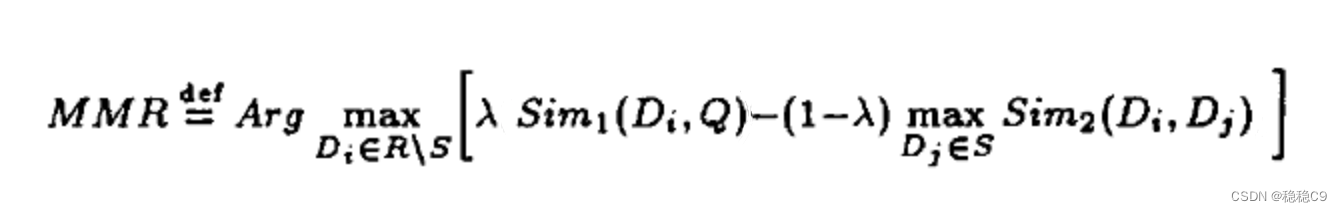
9.2 相似度算法
retriever = vectordb.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": .5})
res = retriever.get_relevant_documents('我爱什么')
9.3 关键字搜索
retriever = vectordb.as_retriever(search_kwargs={"k": 1})
res = retriever.get_relevant_documents('我爱什么')
10、网络检索器
接入搜索引擎
给定一个查询,该检索器将:
- 制定一组相关的 Google 搜索
- 搜索每个
- 加载所有生成的 URL
- 然后在合并的页面内容上嵌入查询并执行相似性搜索
需要购买 key
https://developers.google.com/custom-search/docs/paid_element?hl=zh-cnwe
案例参考:
https://python.langchain.com/docs/modules/data_connection/retrievers/web_research















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









