







python爬虫实战
1.爬取知乎某页html
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://zhuanlan.zhihu.com/p/77560712")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
运行结果:
该页的html
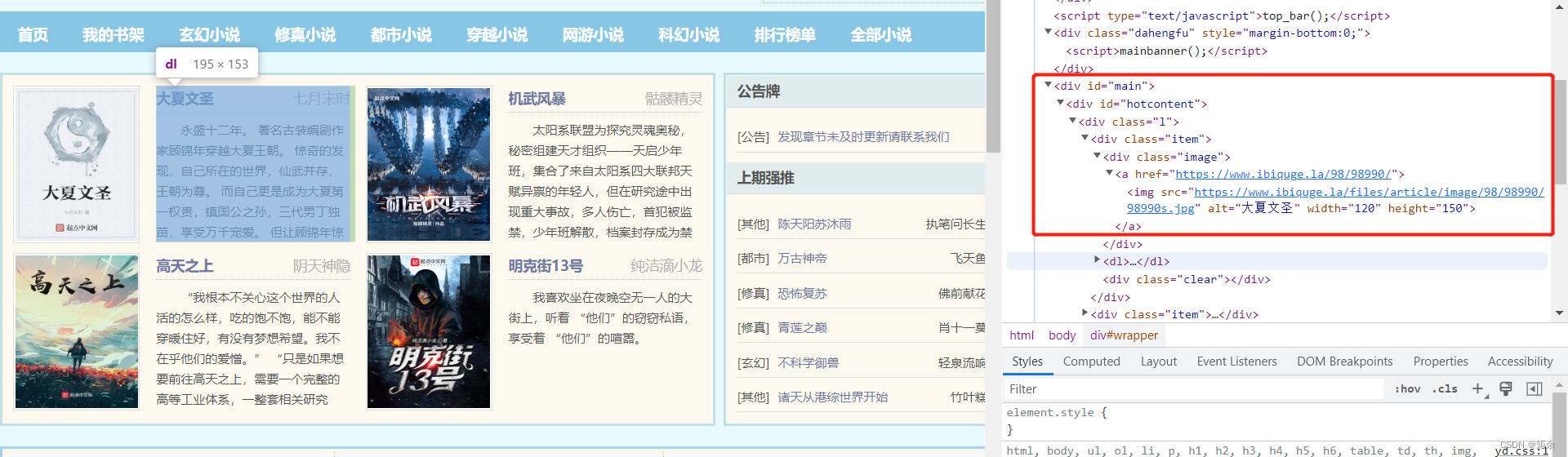
2.笔趣阁小说网址写入data.txt
import requests
from lxml import etree
url = "https://www.xbiquge.la/"
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67'}
def main():
html_text = requests.get(url = url, headers = headers).text
#解析
#先实例化一个etree对象
html_etree_object = etree.HTML(html_text)
passage_title_list1 = html_etree_object.xpath("//div/dl/dt/a[@href]")
passage_addre_list1 = html_etree_object.xpath("//dt/a/@href")
fp = open('data.txt','w',encoding='utf-8')
# print(passage_title_list1)
# print(passage_addre_list1)
# print(passage_title_list1[0].xpath('./text()'))
#局部解析并写入文件
for (ti,ad) in zip(passage_title_list1,passage_addre_list1):
fp.write(ti.xpath("./text()")[0] + ":" + ad + '\n')
fp.close()
main()
输出data.txt结果:
大夏文圣:https://www.ibiquge.la/98/98990/
机武风暴:https://www.ibiquge.la/34/34606/
高天之上:https://www.ibiquge.la/96/96419/
明克街13号:https://www.ibiquge.la/90/90492/
斗罗大陆5重生唐三:https://www.ibiquge.la/24/24770/
恐怖复苏:https://www.ibiquge.la/21/21210/
万古神帝:https://www.ibiquge.la/7/7552/
穷鬼的上下两千年:https://www.ibiquge.la/15/15550/
我家娘子,不对劲:https://www.ibiquge.la/96/96930/
灵境行者:https://www.ibiquge.la/47/47167/
爬取图片网站,把图片写入文件夹
import requests
from lxml import etree
import os
def get_picture():
try:
url = "https://pic.netbian.com/4kdongman/index_2.html"
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
#抓取网页
html_pic = requests.get(url = url , headers = headers)
#查看状态码,若不是200返回异常
html_pic.raise_for_status()
#编码utf-8
html_pic.encoding = html_pic.apparent_encoding
#使用xpath数据解析
html_text = html_pic.text
etree_html = etree.HTML(html_text)
li_list = etree_html.xpath('//div[@class="slist"]/ul/li')
#创建文件夹
if not os.path.exists('./pictures1'):
os.mkdir('./pictures1')
#写入文件picture1
for li in li_list:
#局部解析出图片地址和名字
pic_add ="https://pic.netbian.com/" + li.xpath("./a/img/@src")[0]#注意xpath返回一个列表所以取下标[0],而且返回的地址不完全,所以在网址上打开看一下,把少的域名补上
pic_name = li.xpath("./a/img/@alt")[0] + '.jpg'
img_data = requests.get(url = pic_add,headers = headers).content
img_path = "pictures1/" + pic_name
with open(img_path,'ab') as fp:
fp.write(img_data)
print(pic_name,"保存成功!")
fp.close()
except:
return"产生异常"
def main():
get_picture()
main()















 3328
3328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









