










卷积四分类项目
分类目标选取
鲜花
- 杏花 apricot_blossom
- 桃花 peach_blossom
- 梨花 pear_blossom
- 梅花 plum_blossom
模型选择
卷积
- LeNet5
- VGG16
- ResNet18
- ResNet34
以图搜图
获取相似度前10的搜图结果
数据清洗
鲜花四分类
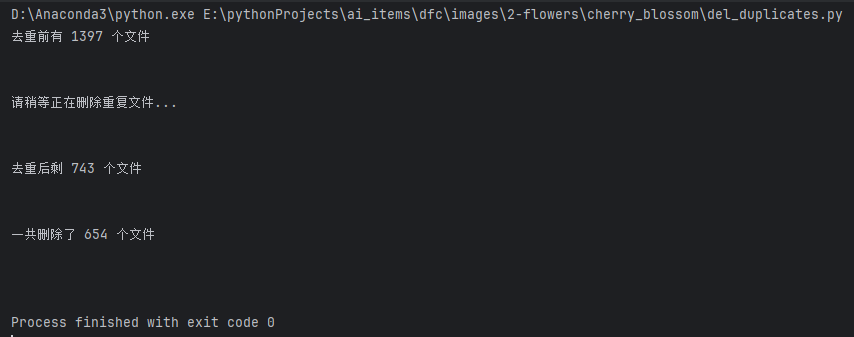
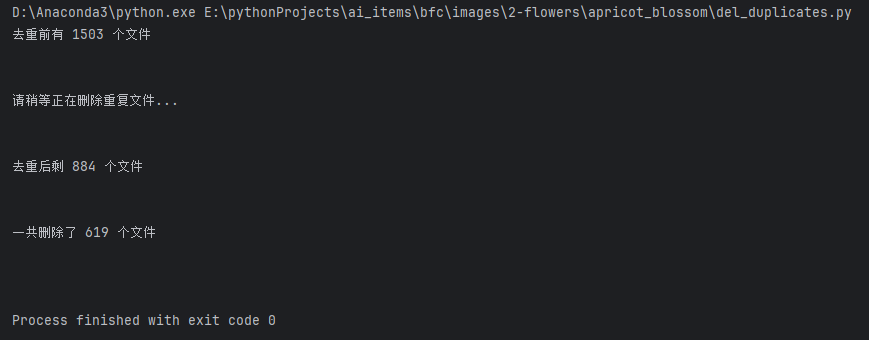
删除非图片文件
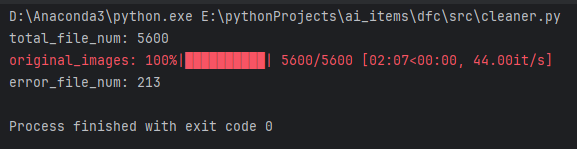
删除重复图片
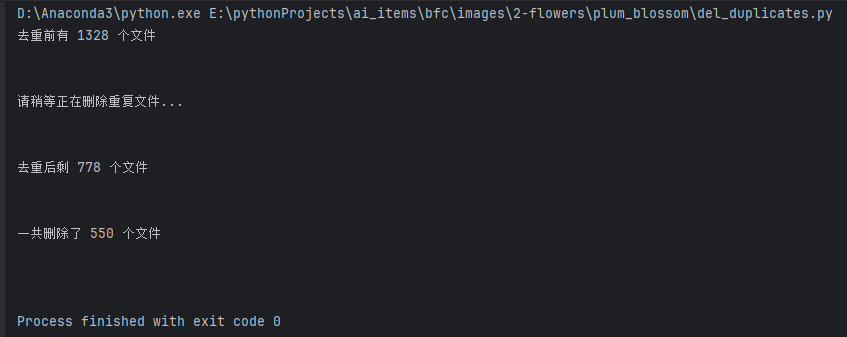
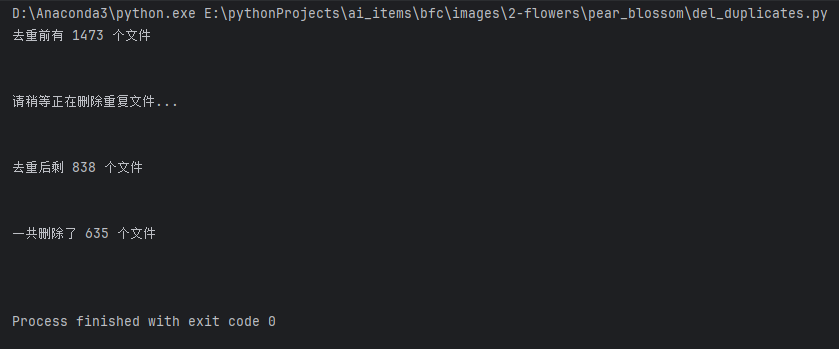
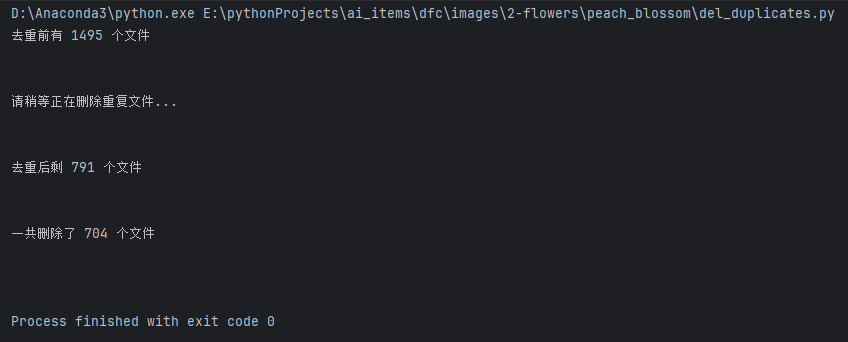
整理数据集
鲜花四分类
每种类别数据:训练500、测试50、预测10
总训练集:2500
总测试集:250
总预测集:40
训练模型
报错
ValueError: num_samples should be a positive integer value, but got num_samples=0
换了电脑后,数据集的存储位置不同,更换路径后解决
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
原因:错误内容就在类型不匹配,根据报错内容可以看出Input type为torch.FloatTensor(CPU数据类型),而weight type(即网络权重参数这些)为torch.cuda.FloatTensor(GPU数据类型)
方案:将输入类型转变为GPU类型
输入数据和网络都切换到cuda,但问题仍存在
检查网络,修改模型隐藏层初始化方式后,解决了问题
鲜花
v1:LeNet5:bn
输出4分类

v2:VGG16:bn
数据太差,提前中断了训练
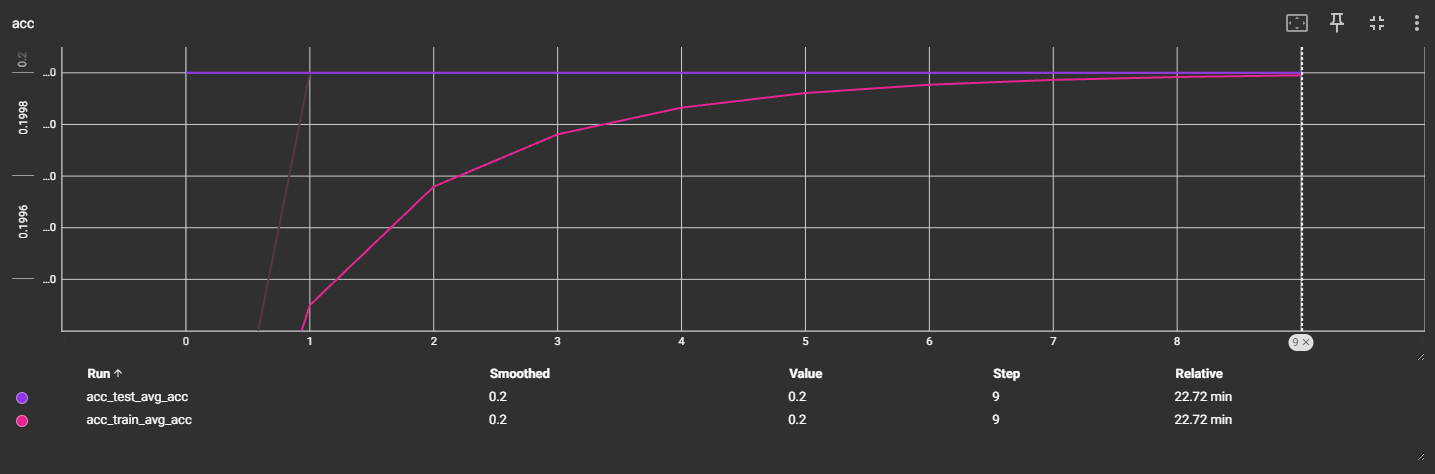
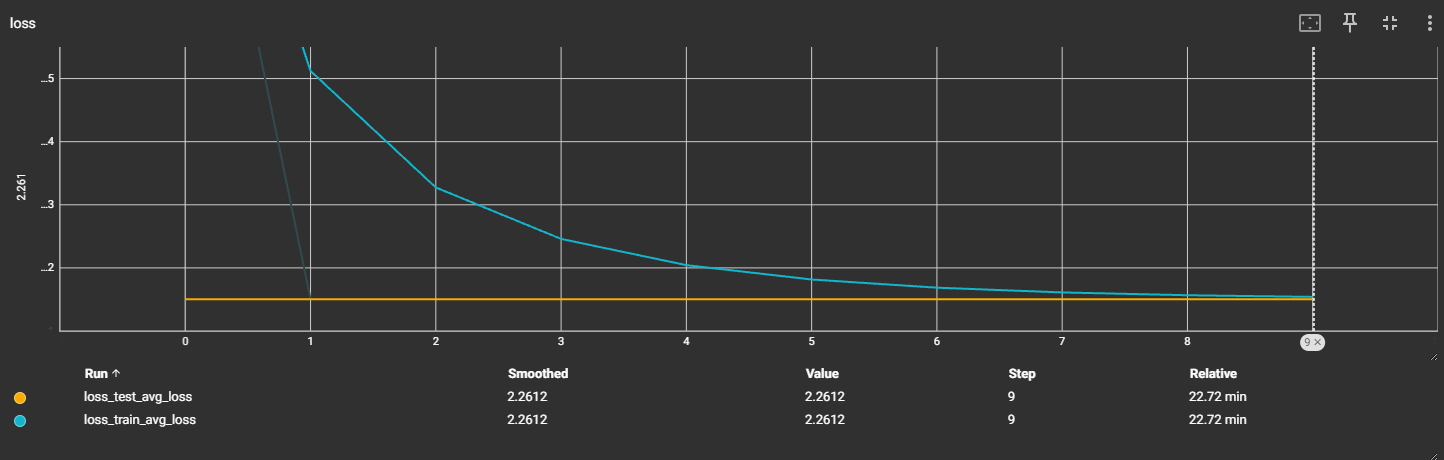

v3:ResNet18:bn
输出4分类
f4_v3:32x32
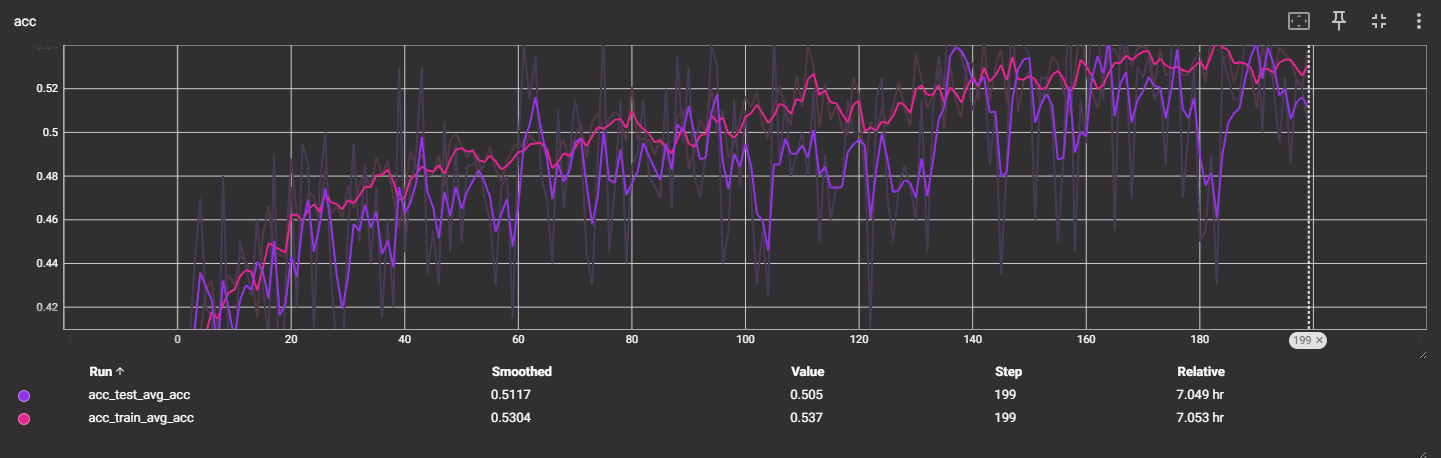
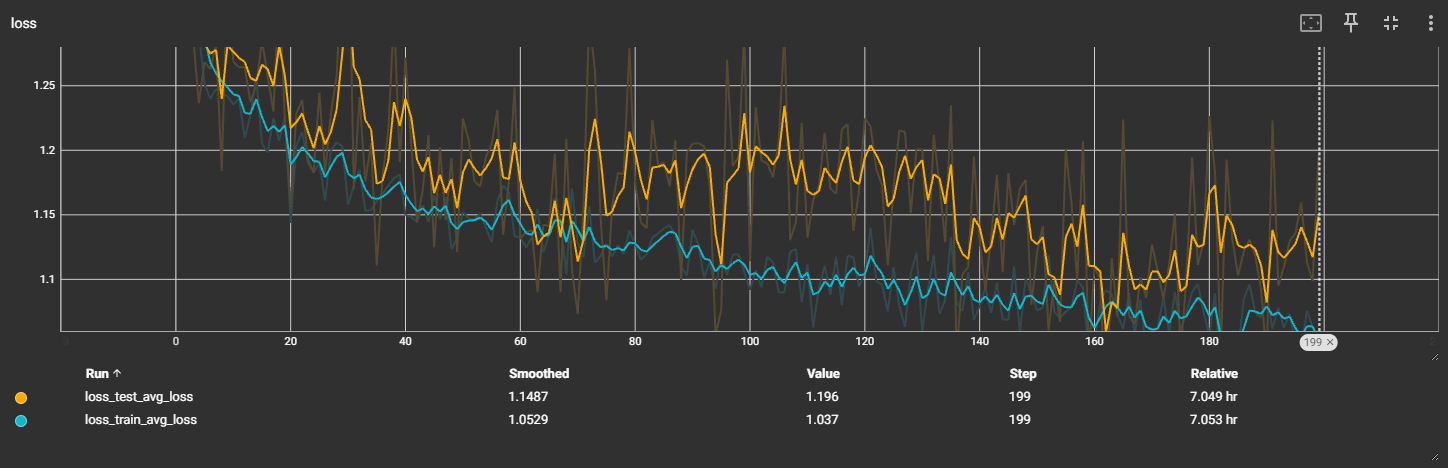

准确率仍上不去,预估增大迭代次数,准确率能慢慢提升
f4_v3.3:224x224
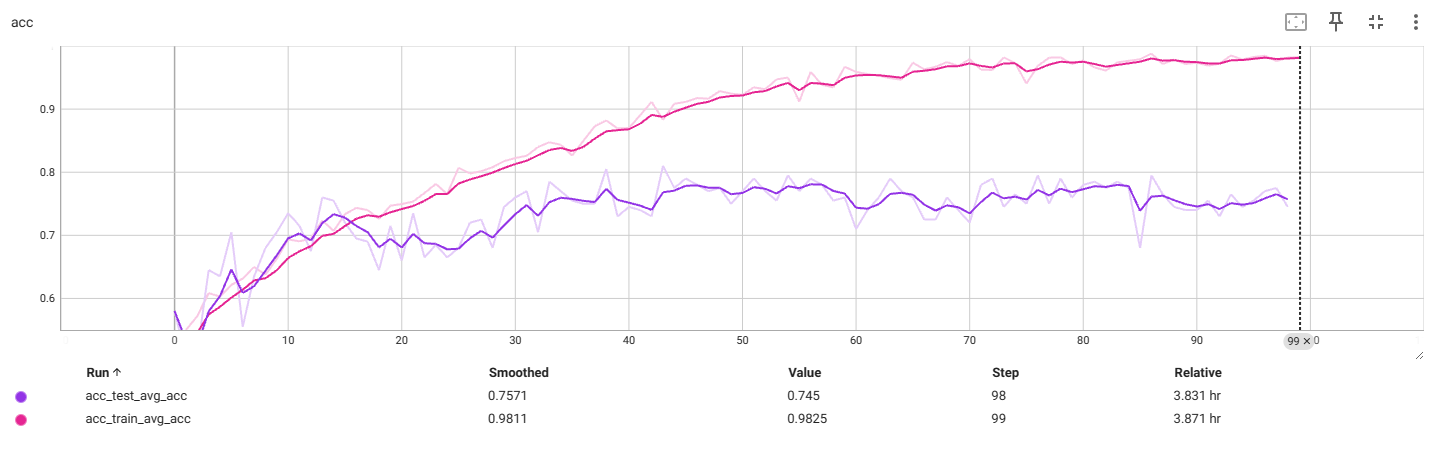
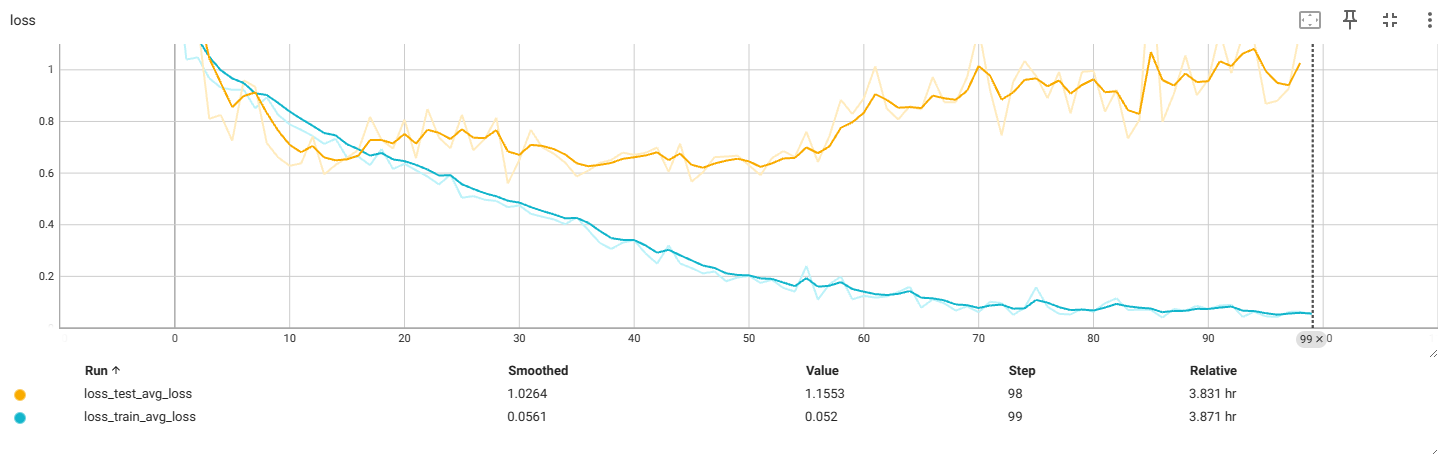
过拟合前最佳:

测试数据出现过拟合现象,考虑减小数据大小
f4_v3.4:112x112
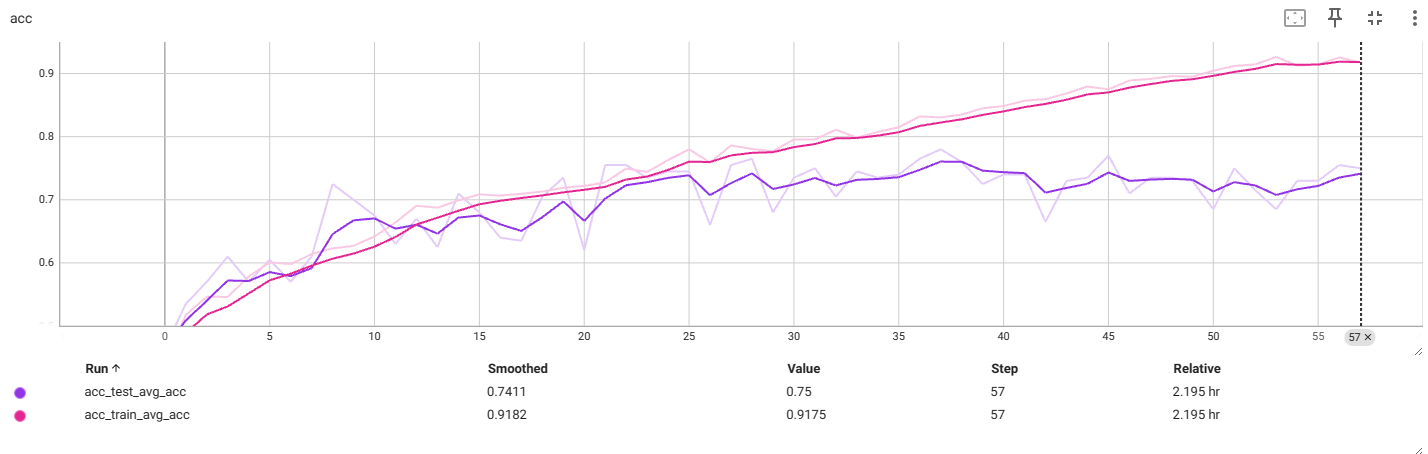
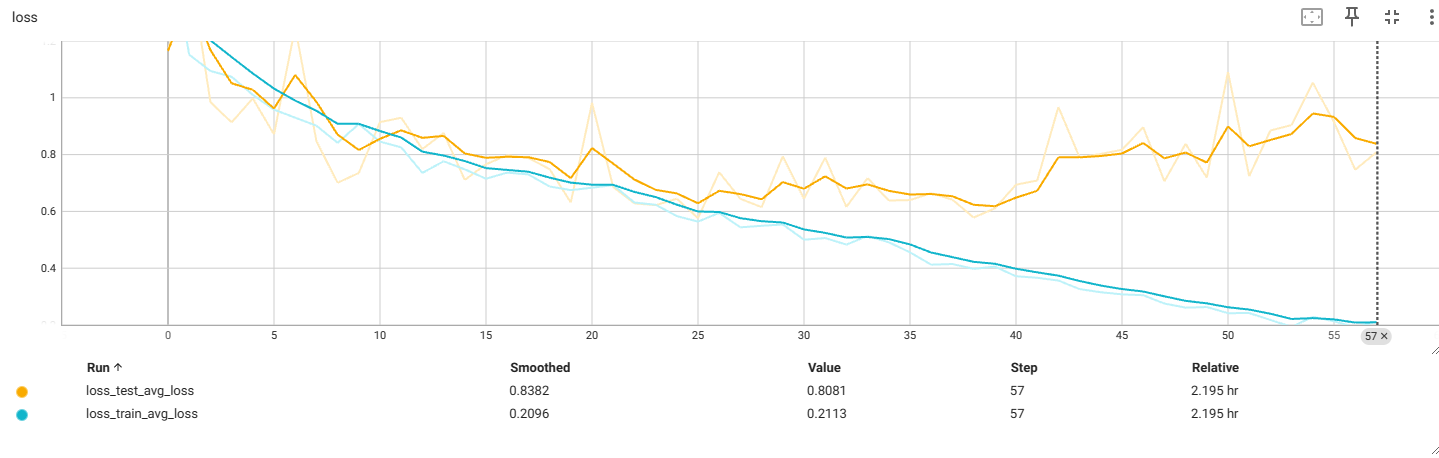
过拟合前最佳:

再次出现过拟合,提前中断了训练
f4_v3.5:56x56
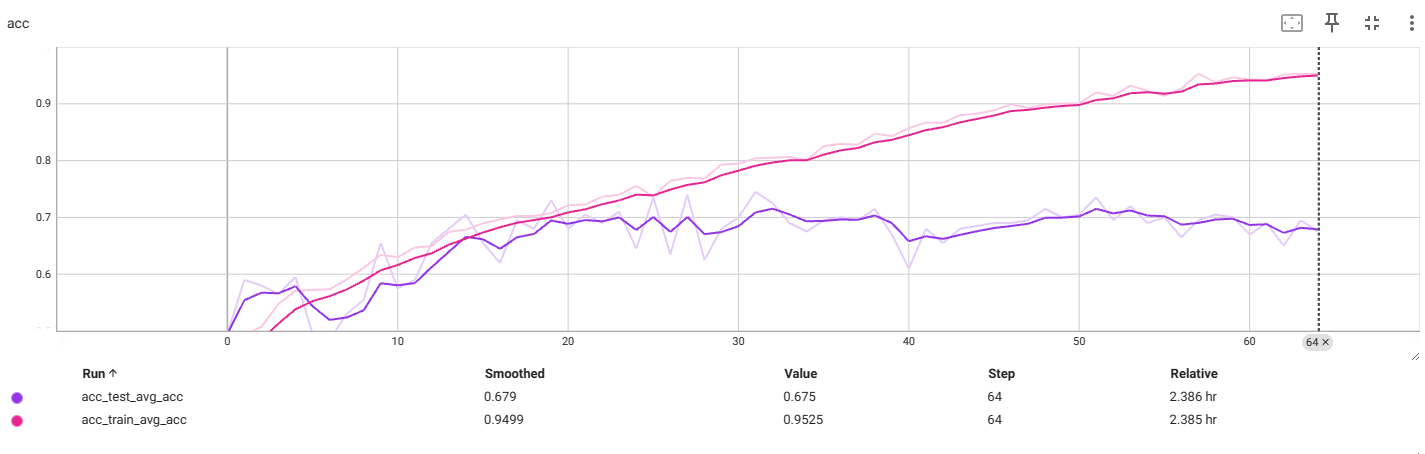
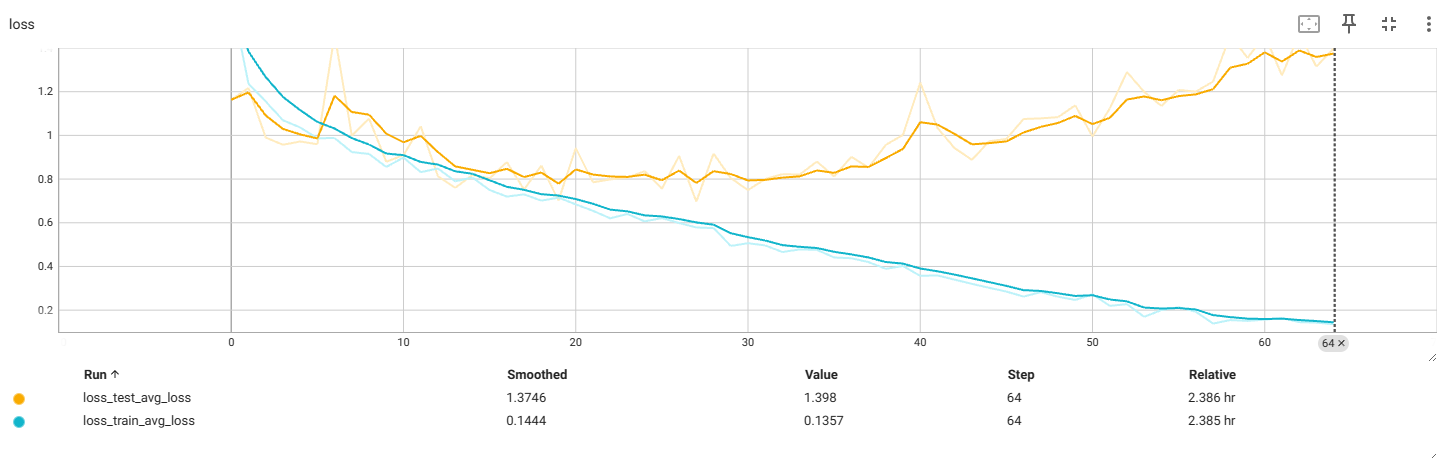
过拟合前最佳:

再次出现过拟合,提前中断了训练
结论:图片缩放大小无法解决过拟合问题
f4_v3.6:32x32,减4个残差块
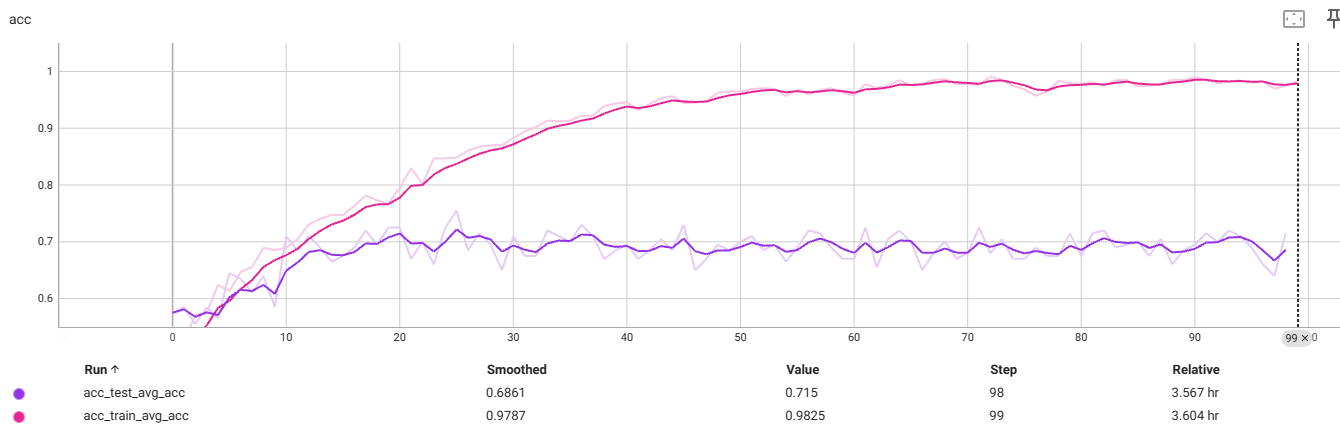
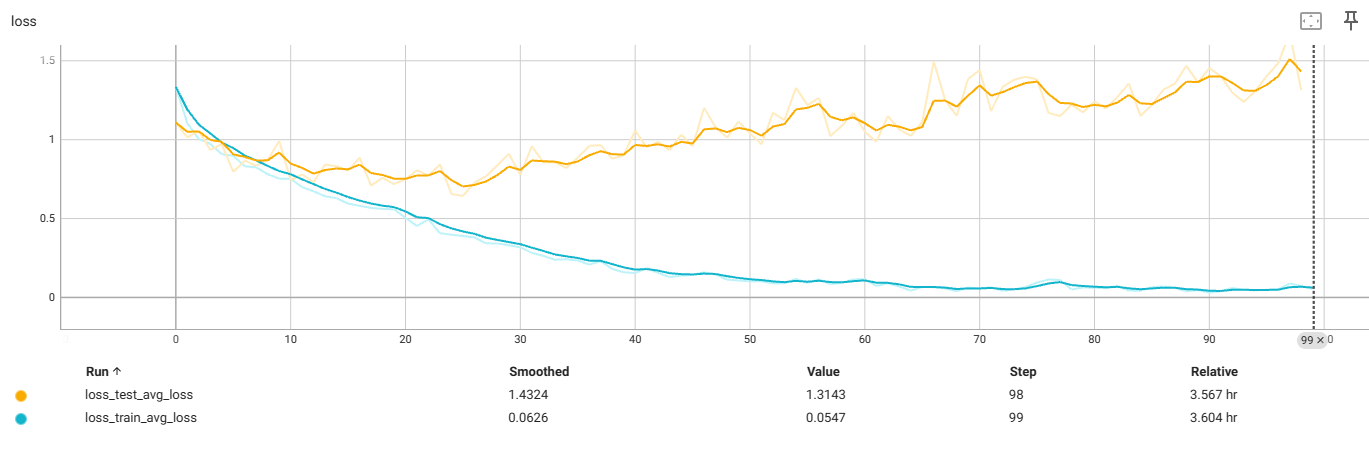
测试集过拟合前

最佳

f4_v3.6:32x32,减4个残差块,transforms减Norm
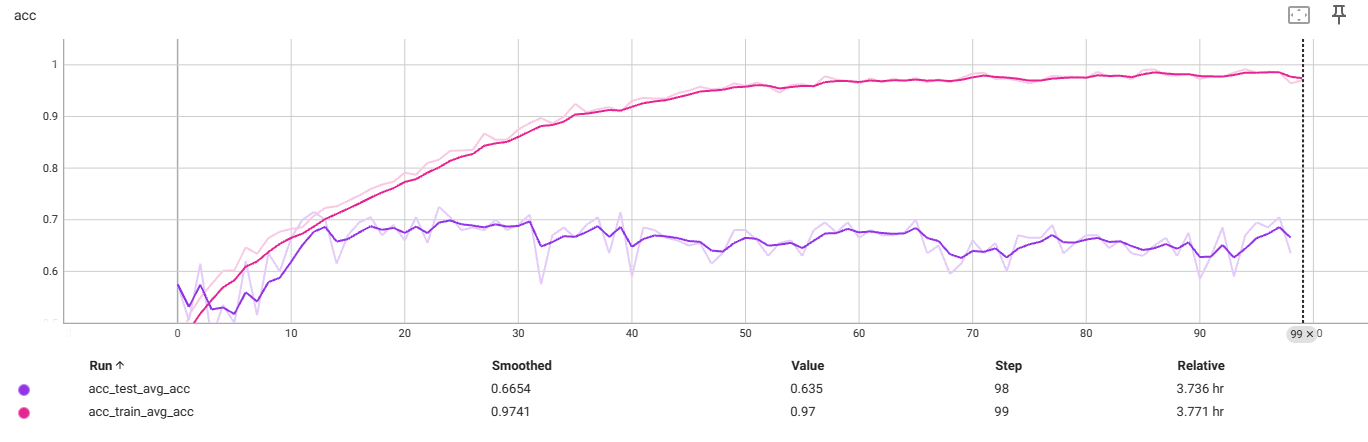
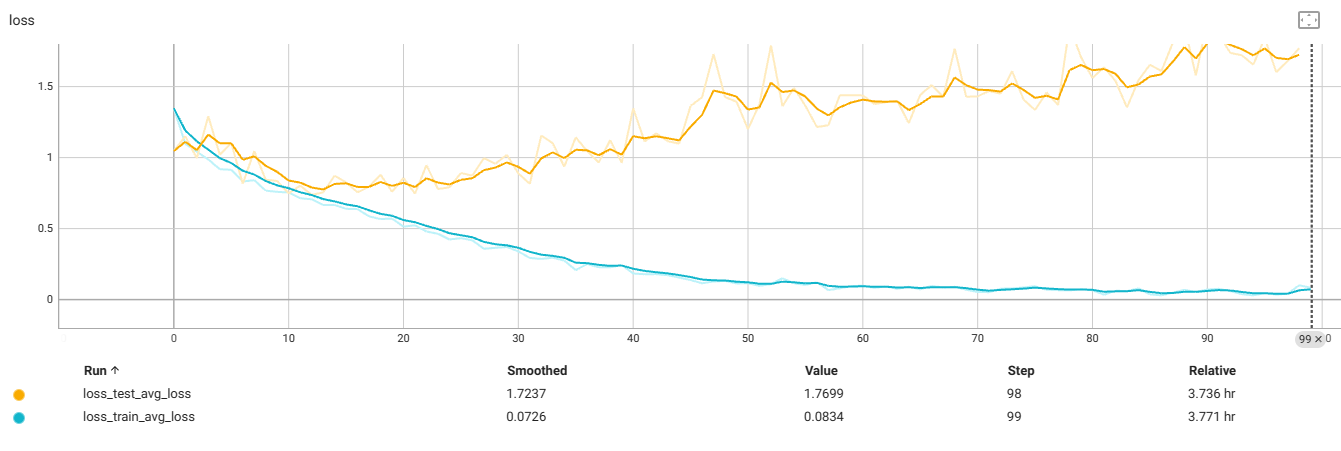
测试集过拟合前

最佳

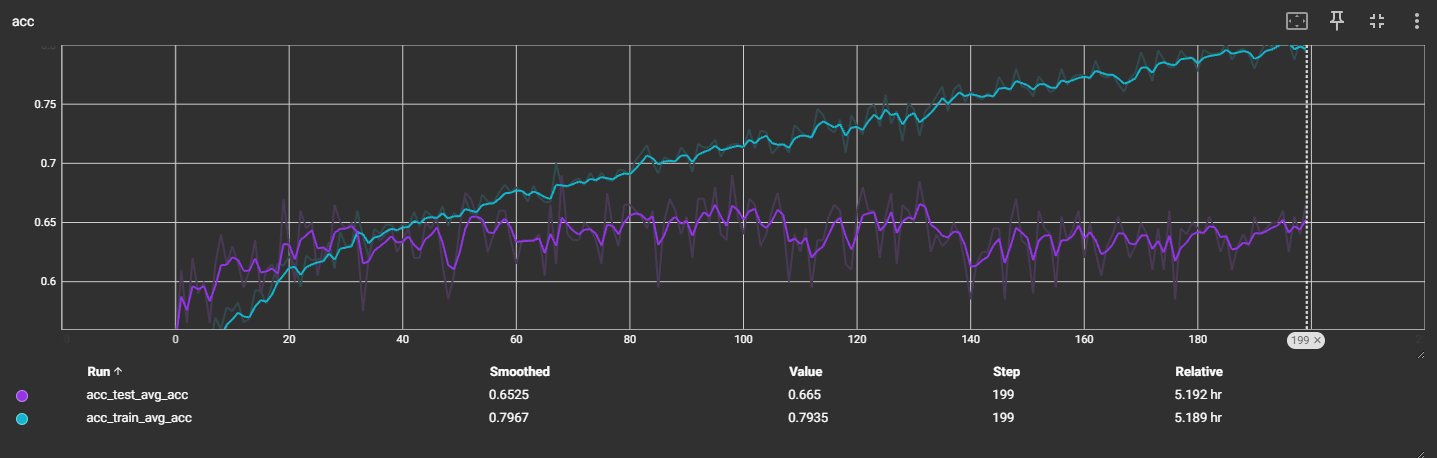
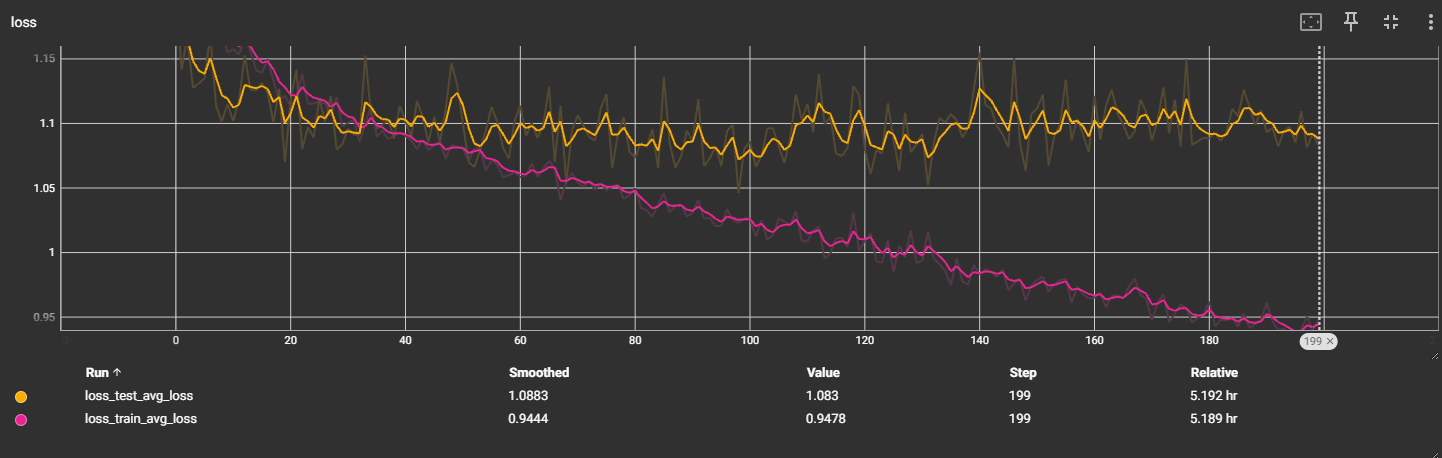
v4:ResNet34:bn
输出4分类
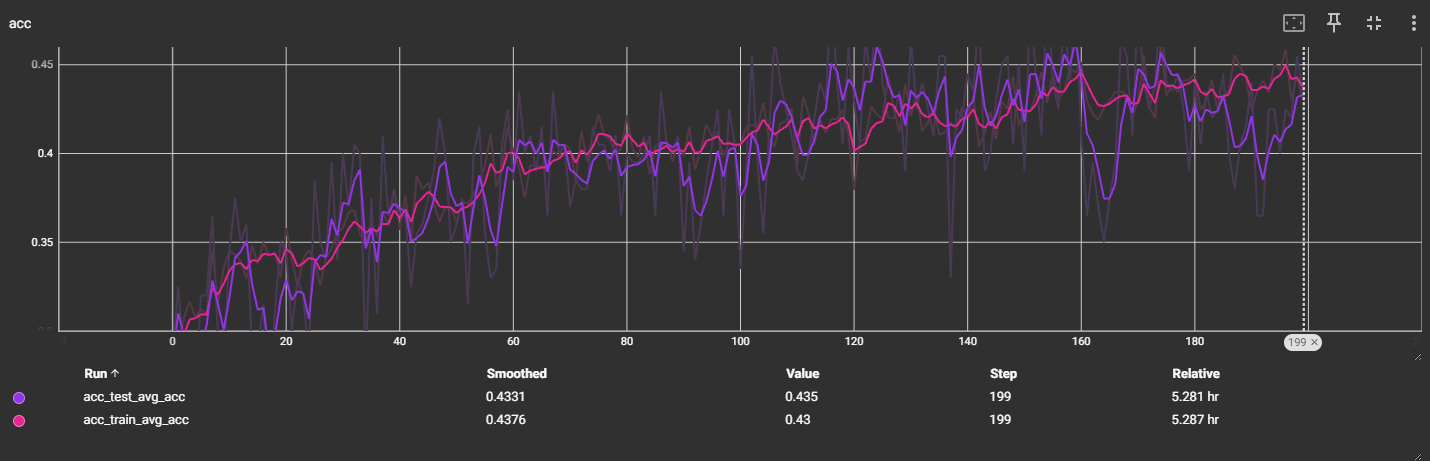
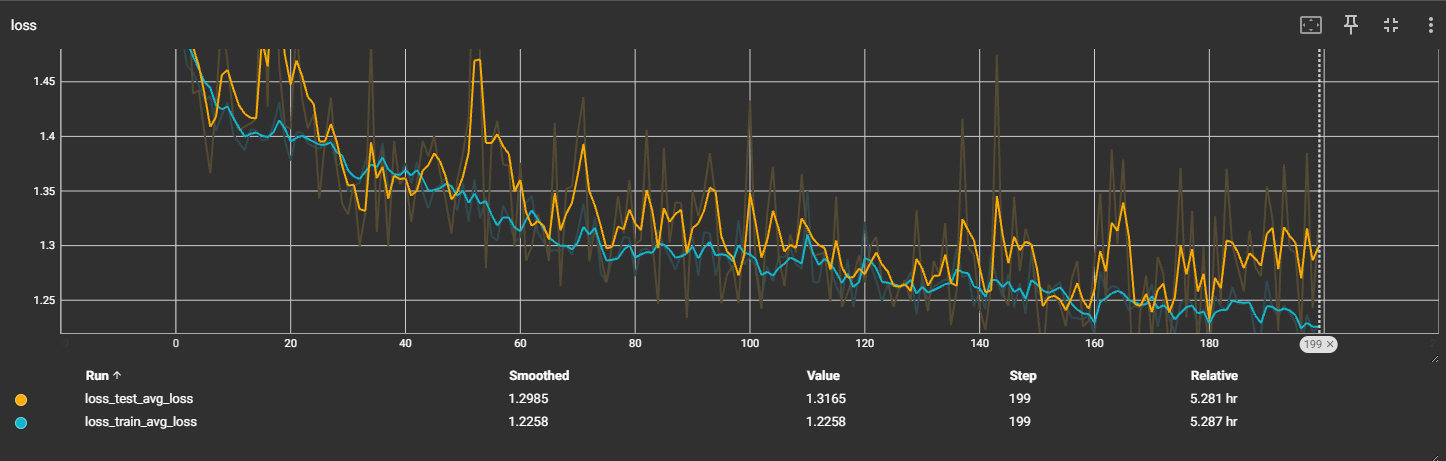

预估:增加迭代次数,可能能缓慢提升准确率
以图搜图
报错
ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 512, 1, 1])

LeNet5模型能正常运行,ResNet18和ResNet34模型报错
正常运行
报错
报错
原因:模型中含有nn.BatchNorm层,训练时需要batch_size大于1,来计算当前batch的running mean and std。自定义数据数量除以batch_size后刚好余1,就发生了上述报错
方案1:在pytorch的Dataloader中设置drop_last=True即可,这样会忽略最后一个batch
尝试在数据集增加drop_last=True,再次训练,尚未解决这个问题
方案2:在添加数据前增加model.eval()
代码原本就有这个语句,仍存在这个问题
方案3:修改训练模型数据预处理中Resize大小32–>224,问题解决
搜图结果
v1:LeNet5:bn
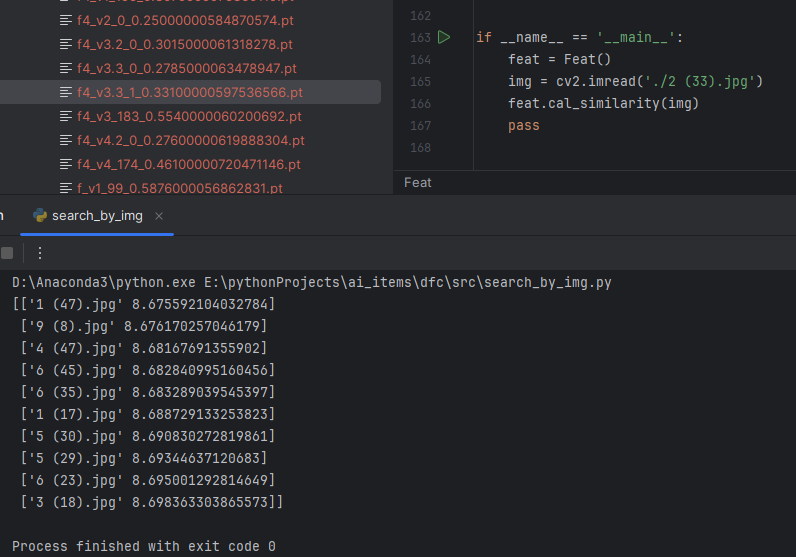
没有一个是正确分类
v3:ResNet18:bn
f4_v3:32x32
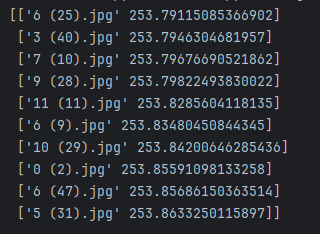
没有一个是正确分类,且相似度差距很大
f4_v3.3:224x224
过拟合前最佳:

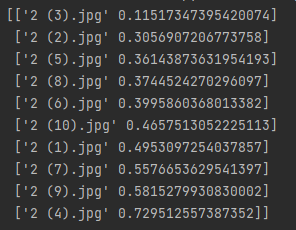
预测最佳类别中top10图片和原图类别相同,但与top1图片与原图相似度不是0
原因:检索库图片根据特征处理、带参数的模型生成对应的特征文件,更换特征处理方式或参数后,生成的特征文件有所不同,所以计算相似度,哪怕是原图也不为0
解决方案:更换特征处理方式或参数后,重新初始化特征文件,再进行预测,解决了这个问题
v4:ResNet34:bn
f4_v4:32x32
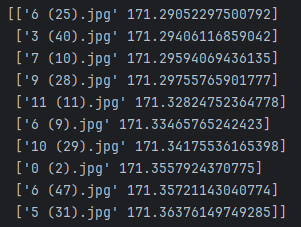
没有一个是正确分类,且相似度差距很大
f4_v4.3:224x224

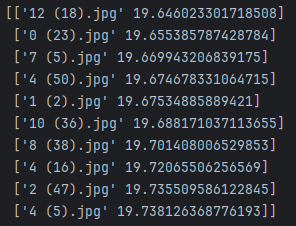
出现了一个正确分类,由于时间问题,v4.3版没有完成足够的训练,不确定迭代后的数据能否达到预期效果
特征处理
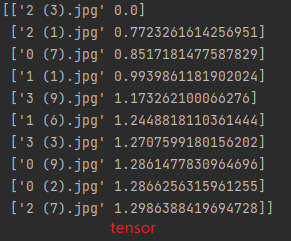
feat_v3.3.0:tensor
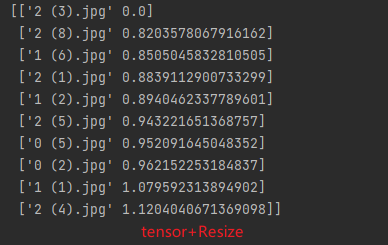
feat_v3.3.1:tensor+Resize56
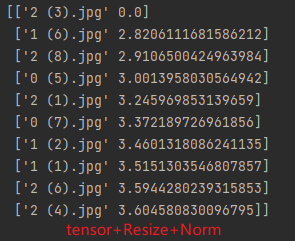
feat_v3.3.2:tensor+Resize56+Norm
feat_v3.3.3:tensor+crop+Resize56
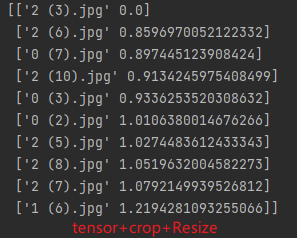
feat_v3.3.4:tensor+Resize+crop+Resize56
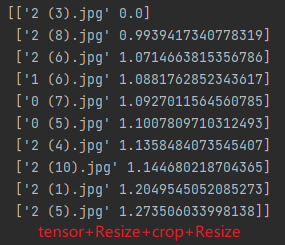
feat_v3.3.5:tensor+Resize+crop+Resize224
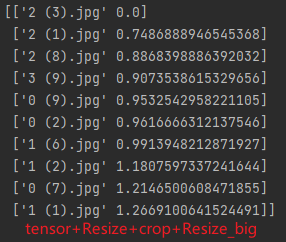
feat_v3.3.6:tensor+Resize+crop+Resize112
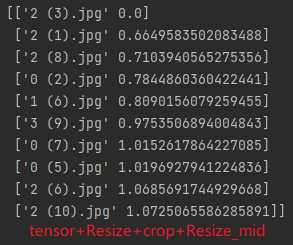
feat_v3.3.7:tensor+Resize+crop+Resize32
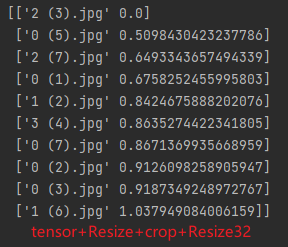
总结
feat_v3.3.4.txt版本的特征处理效果最好
特征处理方式:tensor+Resize600+crop400+Resize56
搜图效果
相似度前10的结果,top1是原图,6张正确类别花,3张错误类别花
原因:这四类花本身比较相似,不便于学习;也可能是数据量不够多,训练效果不够好;也可能迭代的次数不够多,模型没有训练到足够好的效果
















 2810
2810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











