







实验内容
计算以上边界的阶数为20的形状数及其相应的近似多边形。
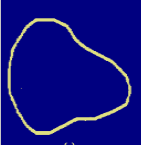
实验原理
形状数是一种基于链码的,反映边界形状的描述子。形状数定义为具有最小值的一阶差分码,其值限定了可能的不同形状数目。
对链码来说,有两种基本的链码表示方法:
 可以按照各个方向的数字来确定相应的图像边界的方向,从而构成图像,对于每相邻的两个方向之间的差则构成了一阶差分码,一阶差分码的最小值即形状数。
可以按照各个方向的数字来确定相应的图像边界的方向,从而构成图像,对于每相邻的两个方向之间的差则构成了一阶差分码,一阶差分码的最小值即形状数。
过程分析
首先先对图像进行二值化处理,得到只有0和1的图像矩阵,然后还需对图像进行相应的小处理,使图像只有轮廓是白色,其余背景部分均为黑色。得到图像如图所示:

然后对图像的每一行进行扫描,找出图像中每一行白色区域的临界端点,然后将两个端点之间的中间区域填充为白色,得到图像如下图所示:

接着调用bwperim函数对得到的二值图像进行轮廓提取:

然后对得到的轮廓图像进行重采样操作,即完整的图像轮廓分散到距离相同的点位处,采样间隔为20个像素点,得到重采样后的图像如下:

最后找出一个起始点进行链码搜索操作,从0方向开始搜索重采样后的图像,并将搜索到的点置0,这样可以防止搜索死循环,且做差后即可得到链码搜索后的图像。最终将各个点存入到矩阵当中并进行连线,得到的近似多边形如下图所示:
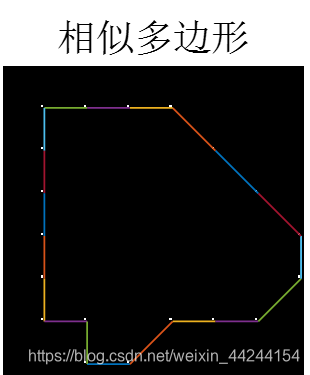
求得的链码为:
对其做差即可求得一阶差分,求具有最小值的一阶差分链码即为形状数。
实验代码如下:
clear all
clc
t1=imread('9.png');
t1=im2bw(t1);%图像二值化
t=t1;
%图像边缘有白边,将其过滤掉
t(:,1)=0;
t(144:145,:)=0;
figure;
imshow(t),title('原图');
[m,n]=size(t);%获取图像大小
%%
%按每一行来进行扫描,找出图像每一行白色区域的临界端点,并将中间区域填充为白色
for i=1:m
lie=t(i,:);
x1=0;x2=n;
zong=sum(lie);
if zong~=0
for j=1:n
if lie(j)==1
x1=j;
break
end
end
lie=flip(lie);
for j=1:n
if lie(j)==1
x2=n-j+1;
break
end
end
for k=x1+1:x2-1
t(i,k)=1; %将中间区域填充为白色
end
end
end
figure;
imshow(t),title('填充区域');
t=bwperim(t,8);%对二值图像进行轮廓提取
figure;
imshow(t),title('轮廓提取');
%%
%重采样
t1=t;
t2=zeros(m,n);
for i=1:m
for j=1:n
if t(i,j)==1
if round(j/20)==0
t2(20*round(i/20),20*(round(j/20)+1))=1;
else
t2(20*round(i/20),20*round(j/20))=1;
end
end
end
end
figure,imshow(t2),title('重取样后');
%%
qidian=[0 0];%保存起点
lianma=[];%保存链码
duandian=zeros(20,2);%保存端点
k=0;
t=t2;
%找出一个起点进行链码搜索
for i=1:m
for j=1:n
if t(i,j)==1
qidian=[i j];
qidian
break;
end
end
end
x=qidian(1);
y=qidian(2)+1;
while (x~=qidian(1)||y~=qidian(2)) && k<21
k=k+1;
if k==1
y=y-1;
end
if y+20<=n
if t(x,y+20)==1
lianma(k)=0;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
y=y+20;
continue;
end
end
if x-20>0&&y+20<=n
if t(x-20,y+20)==1
lianma(k)=1;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
x=x-20;
y=y+20;
continue;
end
end
if x-20>0
if t(x-20,y)==1
lianma(k)=2;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
x=x-20;
continue;
end
end
if x-20>0&&y-20>0
if t(x-20,y-20)==1
lianma(k)=3;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
x=x-20;
y=y-20;
continue;
end
end
if y-20>0
if t(x,y-20)==1
lianma(k)=4;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
y=y-20;
continue;
end
end
if y-20>0
if t(x+20,y-20)==1
lianma(k)=5;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
x=x+20;
y=y-20;
continue;
end
end
if t(x+20,y)==1
lianma(k)=6;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
x=x+20;
continue;
end
if y+20<=141
if t(x+20,y+20)==1
lianma(k)=7;
duandian(k,1)=x;
duandian(k,2)=y;
t(x,y)=0;
x=x+20;
y=y+20;
continue;
end
end
end
lianma
xt=t2-t;
figure,imshow(xt),title('相似多边形'),hold on;
for i=1:19
if i==19
plot([duandian(19,2);duandian(1,2)],[duandian(19,1);duandian(1,1)]);
else
plot(duandian(i:i+1,2),duandian(i:i+1,1));
end
end


















 5836
5836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









