







一.梯度下降优化算法
首先我们先来介绍一下什么是梯度,BP神经网络反向传播的过程就是对权值
w
i
j
w_{ij}
wij进行更新的的过程,而更新权值则离不开梯度的计算。
大学时我们学过怎样求函数
y
=
f
(
x
)
y=f(x)
y=f(x)的极值。函数的极值点,就是它的导数
f
′
(
x
)
=
0
f '(x)=0
f′(x)=0的那个点。因此我们可以通过解方程
f
′
(
x
)
=
0
f '(x)=0
f′(x)=0,求得函数的极值点
(
x
0
,
y
0
)
(x_0,y_0)
(x0,y0)。
不过对于计算机来说,它可不会解方程。但是它可以凭借强大的计算能力,一步一步的去把函数的极值点『试』出来。如下图所示:
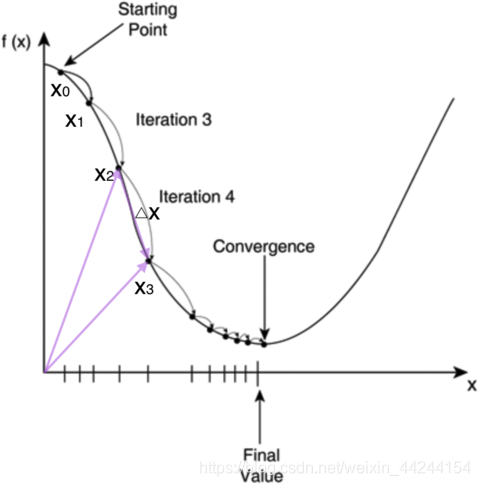
首先,我们随便选择一个点开始,比如上图的
x
0
x_0
x0点。接下来,每次迭代修改的
x
x
x为
x
1
,
x
2
,
x
3
,
x_1,x_2,x_3,
x1,x2,x3,…,经过数次迭代后最终达到函数最小值点。
你可能要问了,为啥每次修改
x
x
x的值,都能往函数最小值那个方向前进呢?这里的奥秘在于,我们每次都是向函数
y
=
f
(
x
)
y=f(x)
y=f(x)的梯度的相反方向来修改。
什么是梯度呢?翻开大学高数课的课本,我们会发现梯度是一个向量,它指向函数值上升最快的方向。显然,梯度的反方向当然就是函数值下降最快的方向了。我们每次沿着梯度相反方向去修改
x
x
x的值,当然就能走到函数的最小值附近。之所以是最小值附近而不是最小值那个点,是因为我们每次移动的步长不会那么恰到好处,有可能最后一次迭代走远了越过了最小值那个点。步长的选择是门手艺,如果选择小了,那么就会迭代很多轮才能走到最小值附近;如果选择大了,那可能就会越过最小值很远,收敛不到一个好的点上。
按照上面的讨论,我们就可以写出梯度下降算法的公式:
X
n
e
w
=
X
o
l
d
−
η
∇
f
(
x
)
X_{new}=X_{old}-\eta\nabla f(x)
Xnew=Xold−η∇f(x)其中,
∇
\nabla
∇是梯度算子,
∇
f
(
x
)
\nabla f(x)
∇f(x)就是指
f
(
x
)
f(x)
f(x)的梯度。
η
\eta
η是步长,也称作学习速率。
对于BP神经网络来说,每个结点之间的权值更新公式为:
w
j
i
←
w
j
i
+
η
δ
j
x
j
i
w_{ji}\leftarrow w_{ji}+\eta\delta_jx_{ji}
wji←wji+ηδjxji其中,是
w
j
i
w_{ji}
wji节点到节点的权重,
η
\eta
η是一个成为学习速率的常数,
δ
j
\delta_j
δj是节点j的误差项,
x
j
i
x_{ji}
xji是节点i传递给节点的输入。
也就是说,如果要求出梯度,就要求出每个结点的误差项
δ
j
\delta_j
δj
二.反向传播算法与推导
反向传播算法(Back Propagation)
我们假设每个训练样本为
(
x
⃗
,
t
⃗
)
(\vec{x},\vec{t})
(x,t),其中向量
x
⃗
\vec{x}
x是训练样本的特征,
t
⃗
\vec{t}
t而是样本的目标值。如下图所示:
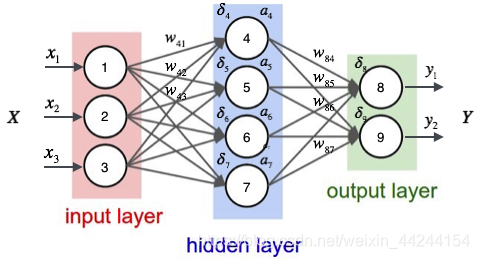
其中,
i
n
p
u
t
input
input
l
a
y
e
r
layer
layer表示样本的输入,有三个节点,我们将其依次编号为1、2、3,在上图中有三个样本的输入
x
1
,
x
2
,
x
3
x_1,x_2,x_3
x1,x2,x3,
h
i
d
d
e
n
hidden
hidden
l
a
y
e
r
layer
layer表示隐藏层,在上图中隐藏层有四个结点,编号依次为4、5、6、7,
o
u
t
p
u
t
output
output
l
a
y
e
r
layer
layer表示样本的输出,在上图中有两个样本的输出
y
1
,
y
2
y_1,y_2
y1,y2。
那么,每个结点的误差项
δ
i
\delta_i
δi为:
·对于输出层结点 i i i
δ
i
=
y
i
(
1
−
y
i
)
(
t
i
−
y
i
)
\delta_i =y_i(1-y_i)(t_i-y_i)
δi=yi(1−yi)(ti−yi)其中,
δ
i
\delta_i
δi是节点
i
i
i的误差项,
y
i
y_i
yi是节点
i
i
i的输出值,
t
i
t_i
ti是样本对应于节点
i
i
i的目标值。
举个例子,根据上图,对于输出层节点8来说,它的输出值是
y
1
y_1
y1,而样本的目标值是
t
1
t_1
t1,带入上面的公式得到节点8的误差项
δ
8
\delta_8
δ8应该是:
δ
8
=
y
1
(
1
−
y
1
)
(
t
1
−
y
1
)
\delta_8 =y_1(1-y_1)(t_1-y_1)
δ8=y1(1−y1)(t1−y1)
·对于隐藏层结点
δ
i
=
a
i
(
1
−
a
i
)
∑
k
∈
o
u
t
p
u
t
s
w
k
i
δ
k
\delta_i =a_i(1-a_i)\sum_{k∈outputs}w_{ki}\delta_k
δi=ai(1−ai)k∈outputs∑wkiδk其中,
a
i
a_i
ai是节点
i
i
i的输出值,
w
k
i
w_{ki}
wki是节点
i
i
i到它的下一层节点
k
k
k的连接的权重,
δ
k
\delta_k
δk是节点
i
i
i的下一层节点
k
k
k的误差项。
例如,对于隐藏层节点4来说,计算方法如下:
δ
4
=
a
4
(
1
−
a
4
)
(
w
8
4
δ
8
+
w
9
4
δ
9
)
\delta_4 =a_4(1-a_4)(w_84\delta_8+w_94\delta_9)
δ4=a4(1−a4)(w84δ8+w94δ9)最后,更新每个连接上的权值:
w
j
i
←
w
j
i
+
η
δ
j
x
j
i
w_{ji}\leftarrow w_{ji}+\eta\delta_jx_{ji}
wji←wji+ηδjxji其中,
w
j
i
w_{ji}
wji是节点
i
i
i到节点
j
j
j的权重,
η
\eta
η是一个成为学习速率的常数,
δ
j
\delta_j
δj是节点
j
j
j的误差项,
x
j
i
x_{ji}
xji是节点
i
i
i传递给节点
j
j
j的输入。
例如,权重
w
84
w_{84}
w84的更新方法如下:
w
84
←
w
84
+
η
δ
8
a
4
w_{84}\leftarrow w_{84}+\eta\delta_8{a_4}
w84←w84+ηδ8a4类似的,权重
w
41
w_{41}
w41的更新方法如下:
w
41
←
w
41
+
η
δ
4
x
1
w_{41}\leftarrow w_{41}+\eta\delta_4{x_1}
w41←w41+ηδ4x1而偏置项的输入值永远为1。
以上神经网络每个节点误差项的计算和权重更新方法。
显然,计算一个节点的误差项,需要先计算每个与其相连的下一层节点的误差项。这就要求误差项的计算顺序必须是从输出层开始,然后反向依次计算每个隐藏层的误差项,直到与输入层相连的那个隐藏层。这就是反向传播算法的名字的含义。
当所有节点的误差项计算完毕后,我们就可以根据
w
j
i
←
w
j
i
+
η
δ
j
x
j
i
w_{ji}\leftarrow w_{ji}+\eta\delta_jx_{ji}
wji←wji+ηδjxji来更新所有的权重。
反向传播算法的推导
由于博客编写公式太过麻烦,下面我用图片手写公式来推导BP反向传播算法
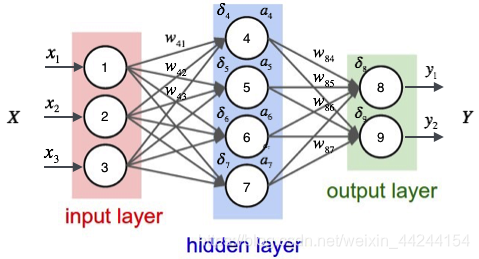
1.观察上图,先进行正向前馈过程:

2.接下来是训练过程:

随机梯度下降法(Stochastic Gradient Descent, SGD):
如果我们根据总误差批量处理来训练模型,那么我们每次更新的迭代,要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(Batch Gradient Descent)。如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。
因此,实用的算法是SGD算法。在SGD算法中,每次更新的迭代,只计算一个样本。也就是采用随机处理来处理单个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对更新数百万次,效率大大提升。由于样本的噪音和随机性,每次更新并不一定按照减少的方向。然而,虽然存在一定随机性,大量的更新总体上沿着减少的方向前进的,因此最后也能收敛到最小值附近。
3.求E对于各个参数的梯度
①对于输出层结点来说, E E E是 y k y_k yk的函数,而 y k y_k yk是 n e t k net_k netk的函数, n e t k net_k netk是 w j k w_{jk} wjk和 b k b_k bk的函数,根据链式求导法则得:


这样,我们便推导出了输出层结点得误差项啦
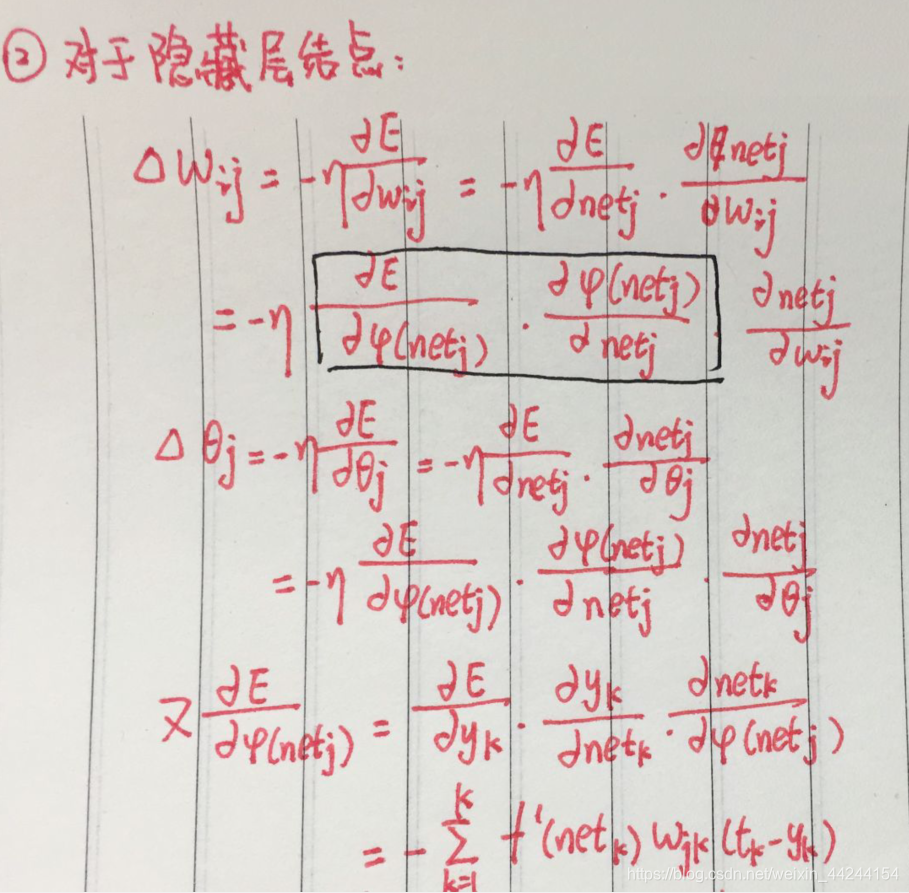
②对于隐藏层结点来说,由链式求导法则对其进行拆分,转而求得隐藏层结点得误差项















 3011
3011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









