







本章核心一句话:
卸下包袱,轻装上阵。--尼采
总述:本章所学内容
0.引子:
上一章介绍的 RNN 之所以不擅长学习时序数据的长期依赖关系,是因为 BPTT 会发生梯度消失和梯度爆炸的问题。本节我们将首先回顾一下上一章介绍的 RNN 层,并通过一个实际的例子来说明为什么 RNN 层不擅长长期记忆。
1.在简单的RNN的学习中,存在梯度消失和梯度爆炸的问题。



梯度爆炸的原因:(这里仅关注RNN层)


仅关注 RNN 层的矩阵乘积时的反向传播的梯度、
反向传播时梯度的值通过 MatMul 节点时会如何变化呢?一旦有了疑问,最好的方法就是做实验
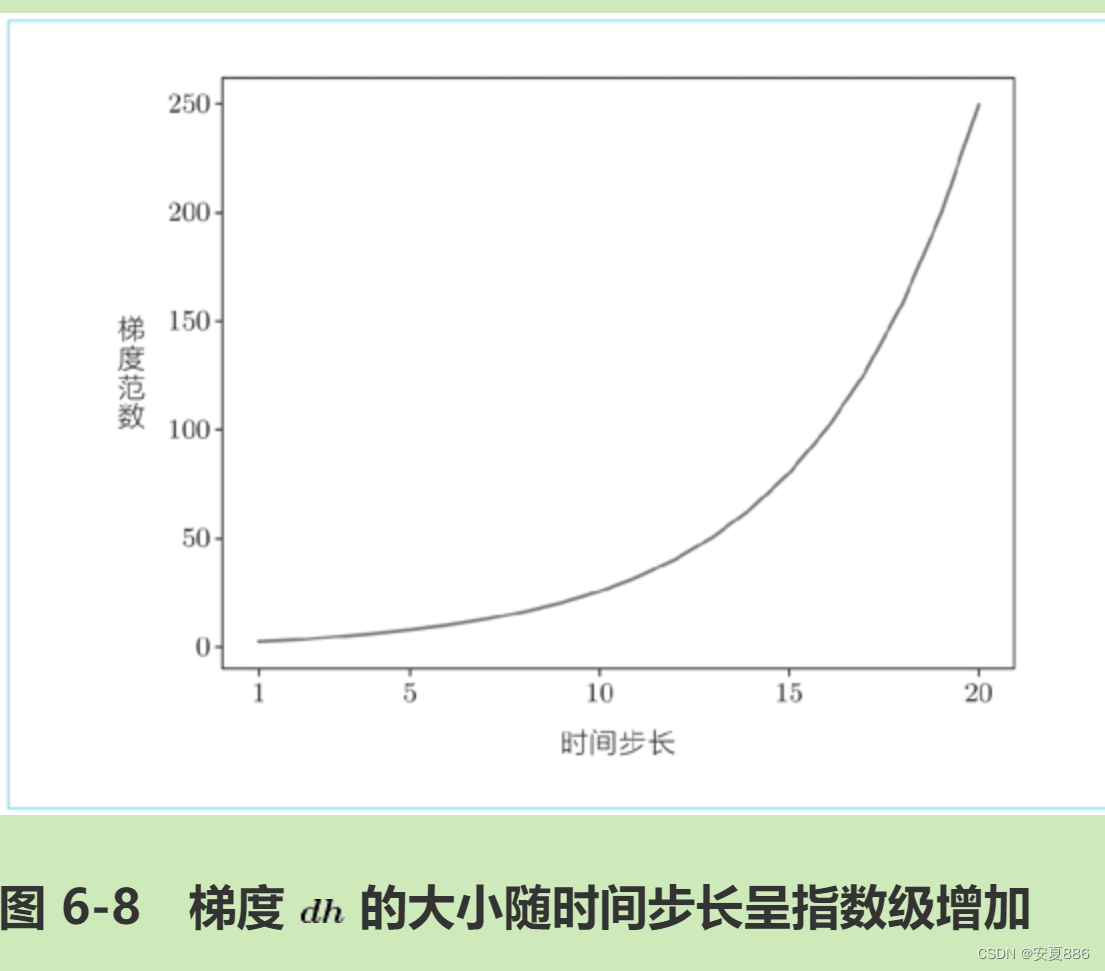
如图 6-8 所示,可知梯度的大小随时间步长呈指数级增加,这就是梯度爆炸(exploding gradients)。如果发生梯度爆炸,最终就会导致溢出,出现 NaN(Not a Number,非数值)之类的值。如此一来,神经网络的学习将无法正确运行。
现在我们做第二个实验:梯度消失

从图 6-9 中可以看出,这次梯度呈指数级减小,这就是 梯度消失(vanishing gradients)。如果发生梯度消失,梯度将迅速变小。一旦梯度变小,权重梯度不能被更新,模型就会无法学习长期的依赖关系。
在这里进行的实验中,梯度的大小或者呈指数级增加,或者呈指数级减小。为什么会出现这样的指数级变化呢?因为矩阵 Wh 被反复乘了 T 次。如果 Wh 是标量,则问题将很简单:当 Wh 大于 1 时,梯度呈指数级增加;当 Wh 小于 1 时,梯度呈指数级减小。
2.梯度裁剪对解决梯度爆炸有效,LSTM,GRU等Gated RNN对解决梯度消失有效
梯度爆炸的对策:

梯度消失对策:

RNN层与LSTM层的比较:

LSTM的优越性:
Gate的引入:

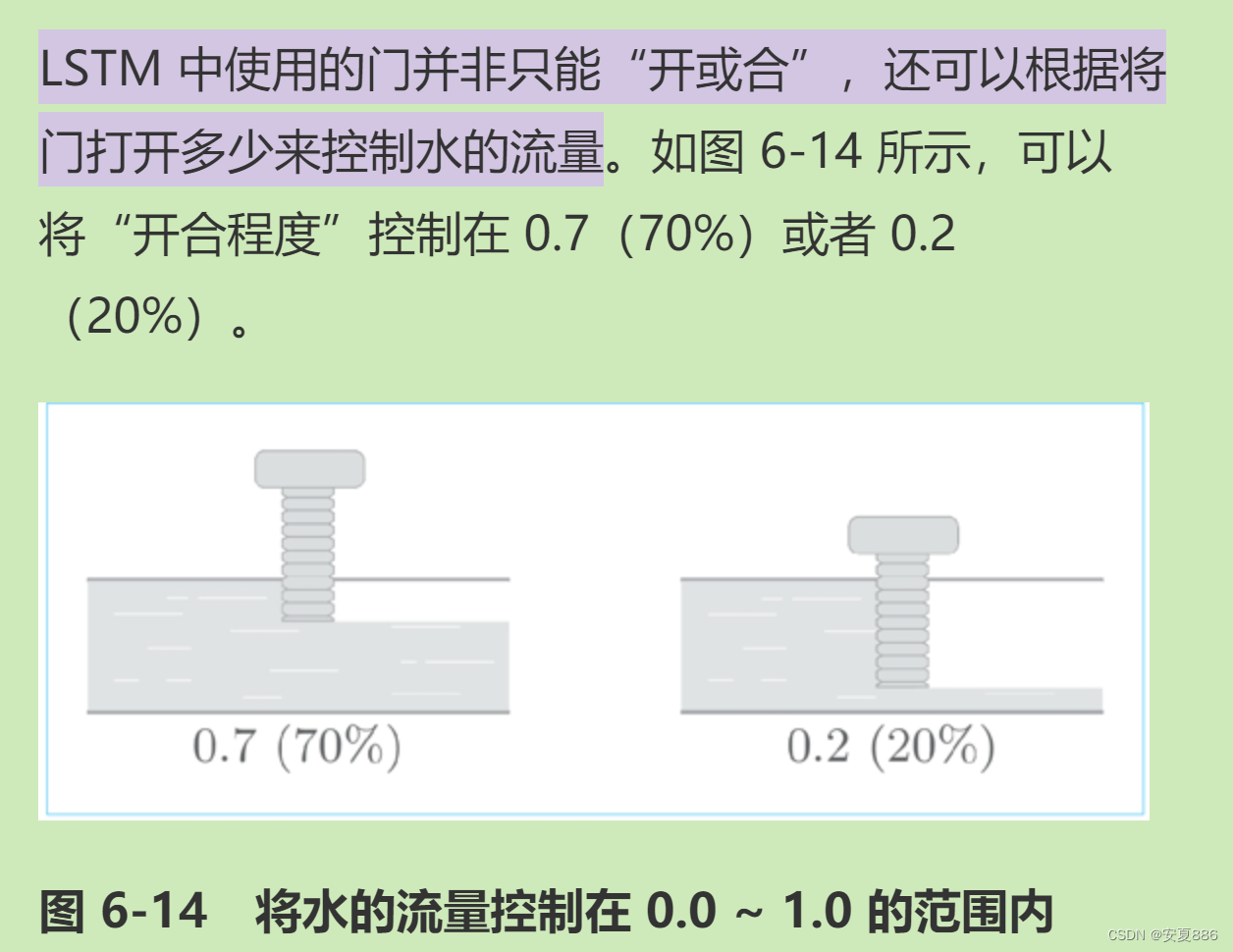

3.LSTM中有3个门:输入门,遗忘门和输出门。
什么是输出门:


以上就是 LSTM 的输出门。这样一来,LSTM 的输出部分就完成了,接着我们再来看一下记忆单元的更新部分。
知识点拓展:
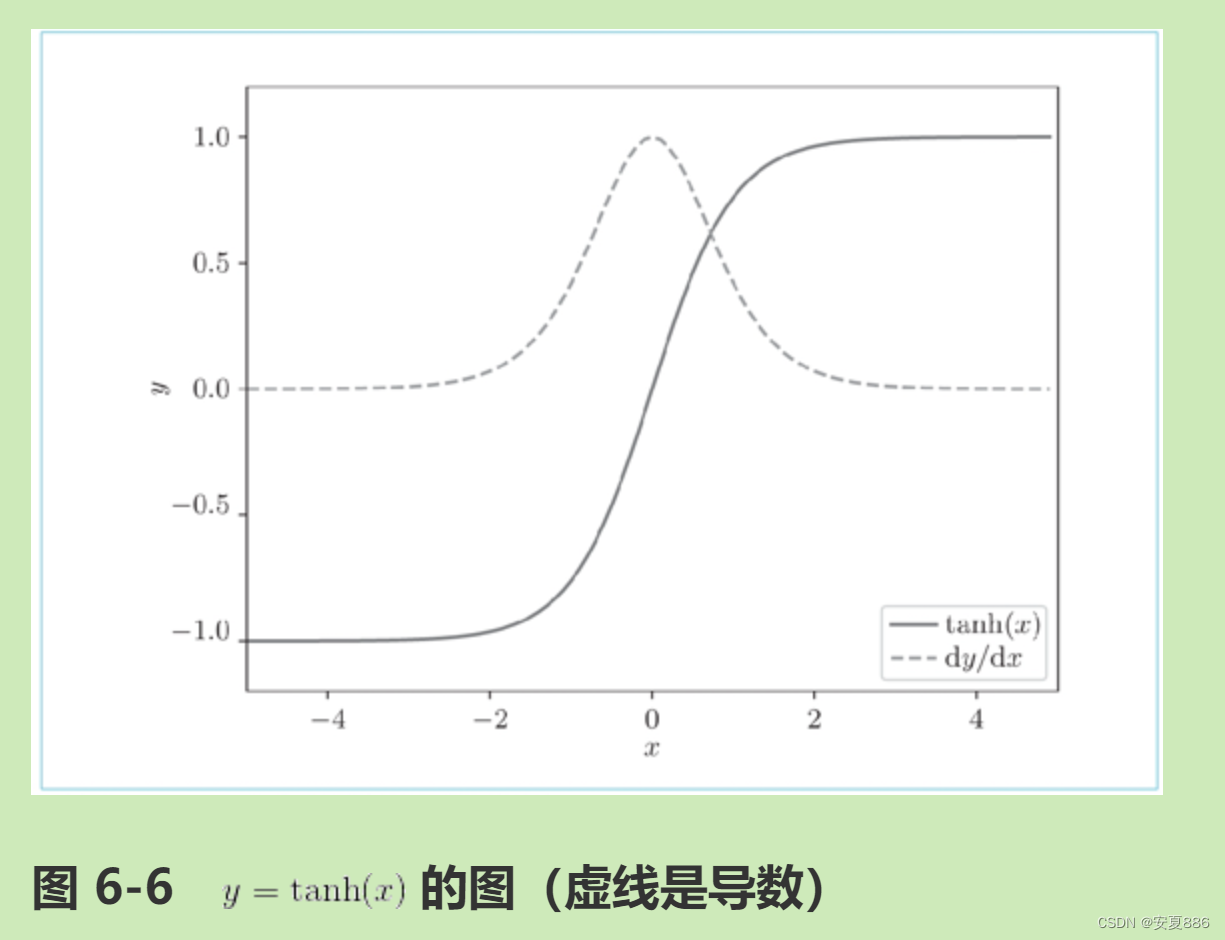
tanh 的输出是 -1.0 ~ 1.0 的实数。我们可以认为这个 -1.0 ~ 1.0 的数值表示某种被编码的“信息”的强弱(程度)。而 sigmoid 函数的输出是 0.0~1.0 的实数,表示数据流出的比例。因此,在大多数情况下,门使用 sigmoid 函数作为激活函数,而包含实质信息的数据则使用 tanh 函数作为激活函数。
什么是遗忘门:


什么是输入门:
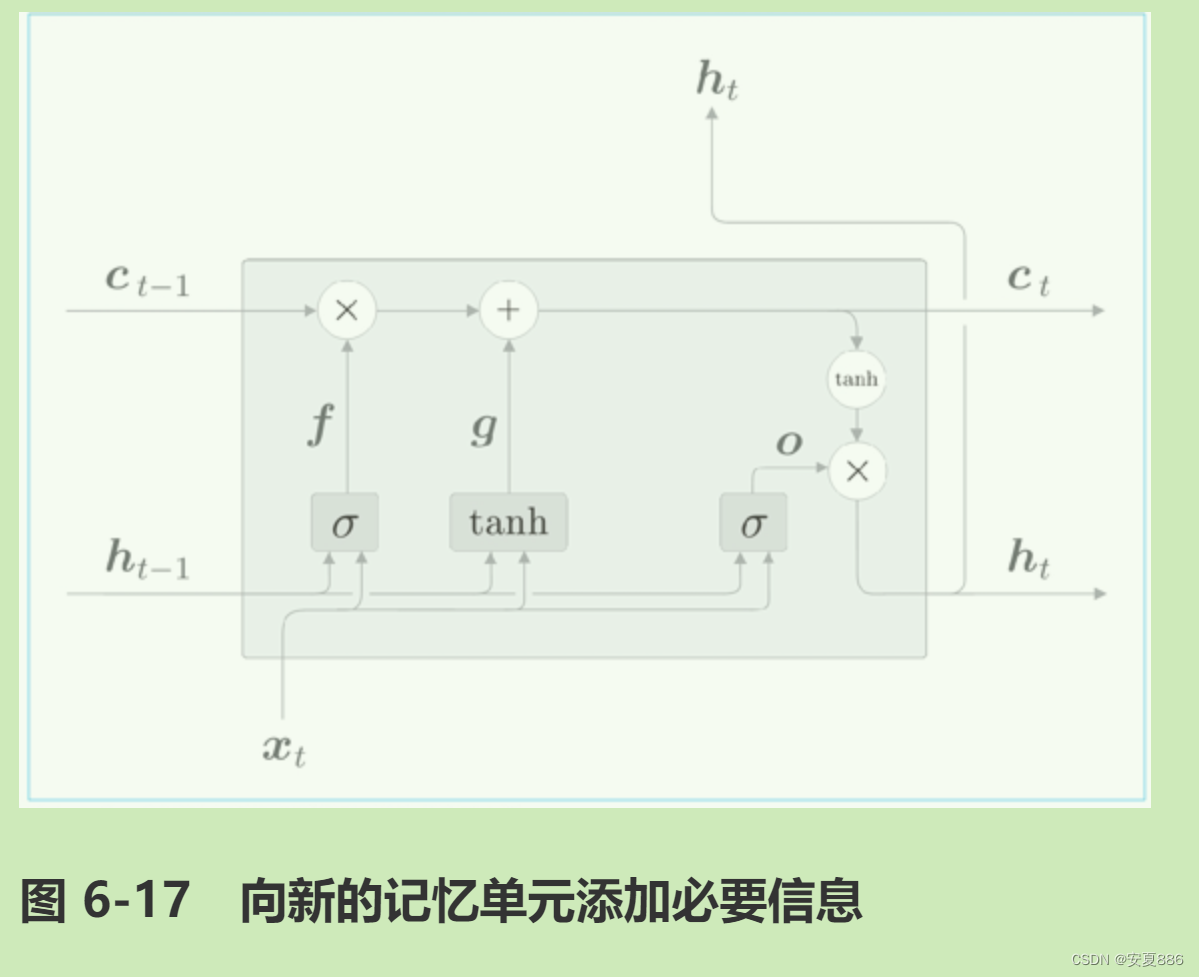

最后,我们给图 6-17 的 g 添加门,这里将这个新添加的门称为输入门

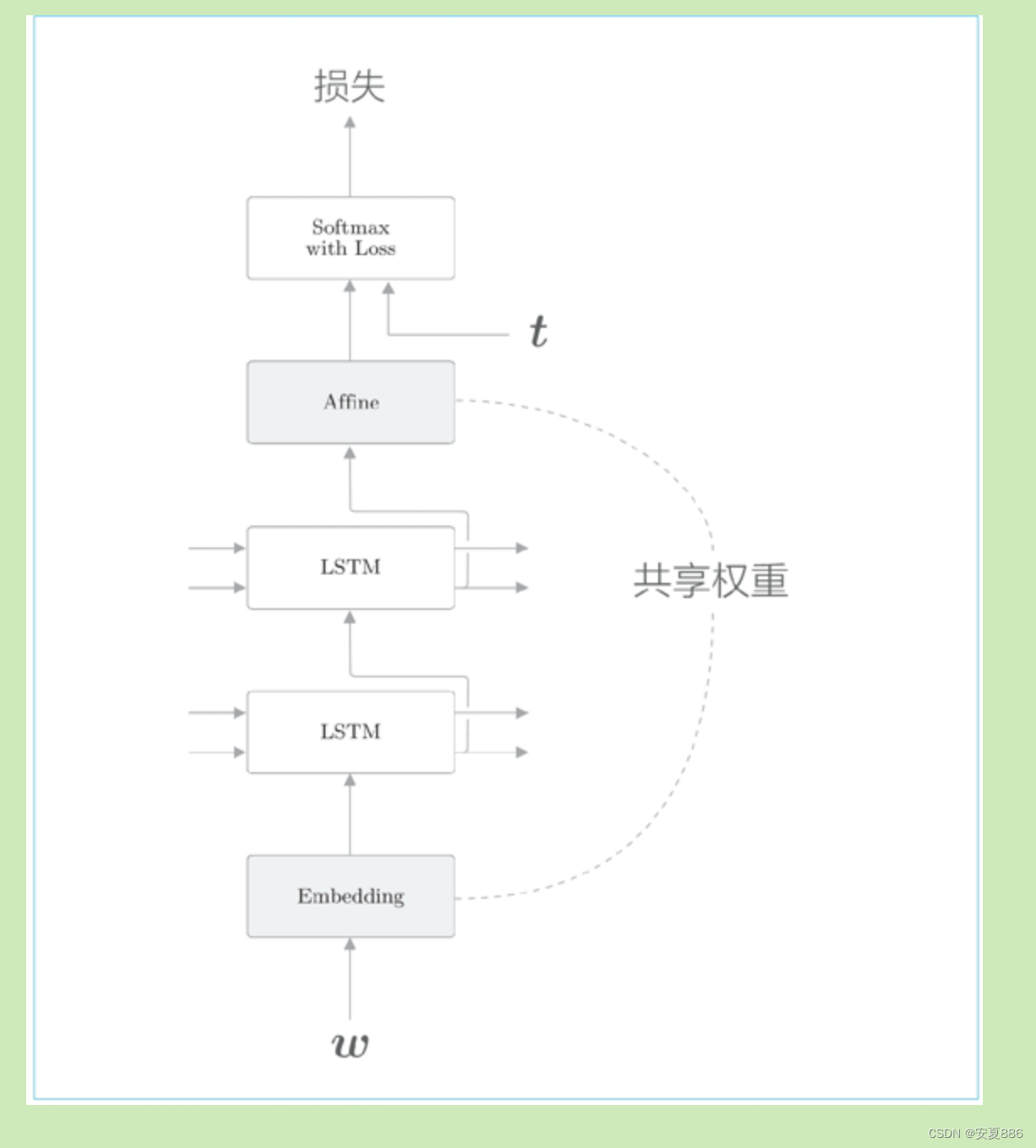
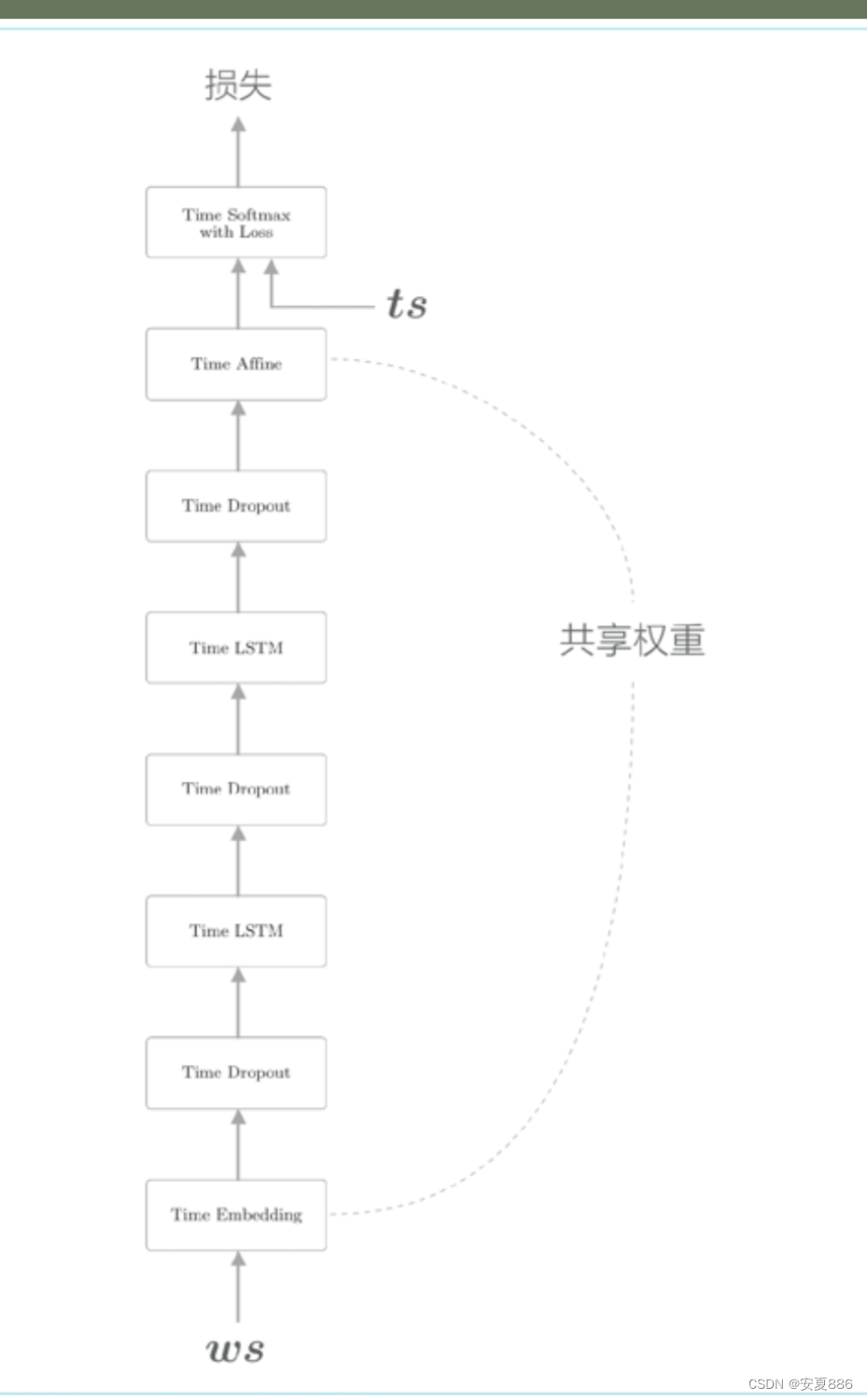
4.LSTM的多层化,Dropput和权重共享等技巧可以有效改进语言模型



在图 6-20 中,4 个权重(或偏置)被整合为了 1 个。如此,原本单独执行 4 次的仿射变换通过 1 次计算即可完成,可以加快计算速度。这是因为矩阵库计算“大矩阵”时通常会更快,而且通过将权
重整合到一起管理,源代码也会更简洁。
5.RNN的正规化很重要,人们处理各种基于Dropout的方法。
通过叠加 LSTM 层,可以期待能够学习到时序数据的复杂依赖关系。换句话说,通过加深层,可以创建表现力更强的模型,但是这样的模型往往会发生过拟合(overfitting)。更糟糕的是,RNN 比常规的前馈神经网络更容易发生过拟合,因此 RNN 的过拟合对策非常重要。
抑制过拟合已有既定的方法:一是增加训练数据;二是降低模型的复杂度。我们会优先考虑这两个方法。除此之外,对模型复杂度给予惩罚的正则化也很有效。比如,L2 正则化会对过大的权重进行惩罚。
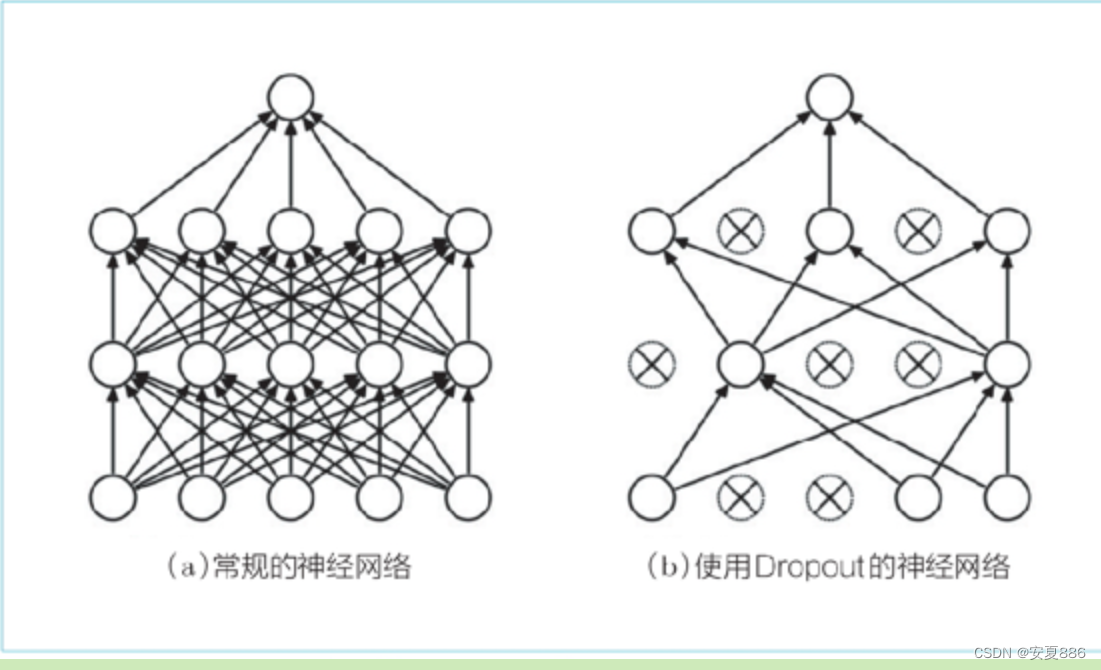
此外,像 Dropout[9] 这样,在训练时随机忽略层的一部分(比如 50 %)神经元,也可以被视为一种正则化(图 6-30)。本节我们将仔细研究 Dropout,并将其应用于 RNN。







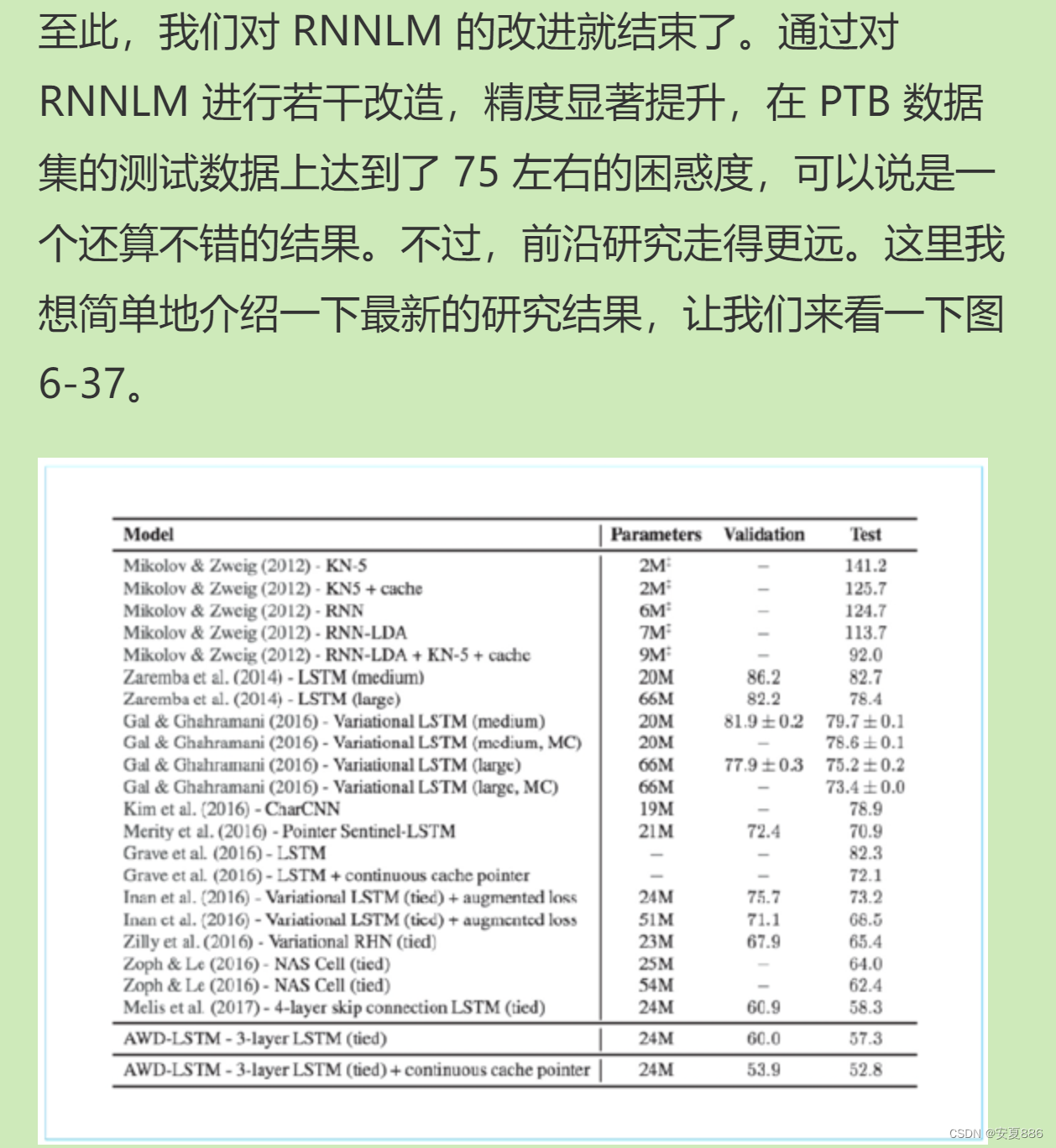
















 2848
2848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









