







👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【python】python小说数据抓取+可视化(源码+数据)【独一无二】
一、功能描述
主要采集是创世中文网,网页中主要功能如下:
-
爬取小说信息: 通过循环遍历预设的小说类型和页数,使用requests库发送HTTP请求获取每一页小说信息的HTML页面,然后解析库提取页面中的小说标题、等级、类型、字数和简介等信息,并保存到Excel文件中。
-
数据清洗和转换: 读取Excel文件中的数据,对字数进行单位统一和异常处理,确保数据的准确性和一致性。
-
数据可视化: 绘制多种图表,包括散点图、折线图、柱状图、饼图和词云图,展示了小说数据的不同特征和分布情况,如小说等级与字数的关系、小说标题长度与字数的关系、不同类型小说的总字数和数量分布、每种类型小说的平均字数以及字数最多的前15篇小说等。
-
提供数据分析: 通过观察和分析生成的图表,用户可以更直观地了解小说数据的特征和规律,例如不同类型小说的数量和字数分布情况,以及字数最多的小说等。这些分析有助于用户做出进一步的决策或研究。
数据抓取内容如下,主要采集了 2000+ 条数据,保存到excel文件中:

👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
爬取内容显示如下:

二、可视化展示
- 折线图:名字最长的前10篇小说的字数
- 通过
plt.plot()函数绘制折线图,横轴为前10篇小说的标题,纵轴为字数(单位为万字)。 - 通过
plt.xticks()函数设置横坐标的旋转角度和对齐方式,使得标题能够清晰显示。 - 通过
plt.title()函数设置图表标题,plt.ylabel()函数设置纵坐标标签,plt.tight_layout()函数调整布局,最后使用plt.show()函数显示图表。
- 通过
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
- 柱状图:类型 vs 总字数
- 首先使用
groupby()函数按照小说类型对数据进行分组,然后使用sum()函数计算每种类型小说的总字数。 - 通过
plot(kind='bar')函数绘制柱状图,横轴为小说类型,纵轴为总字数(单位为万字)。 - 同样使用
plt.title()函数设置图表标题和纵坐标标签,最后使用plt.show()函数显示图表。
- 首先使用
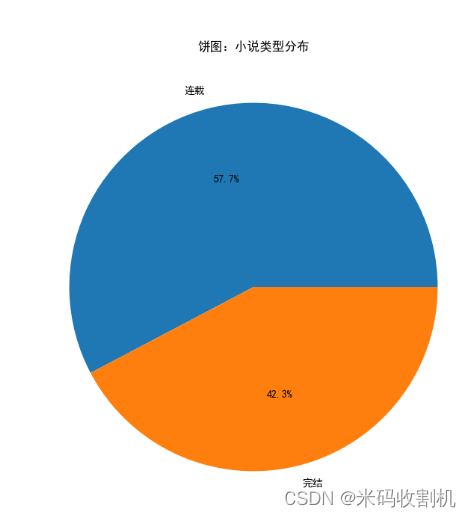
- 饼图:小说类型分布
- 使用
value_counts()函数统计每种小说类型的数量。 - 通过
plot(kind='pie')函数绘制饼图,展示不同类型小说的数量占比。 - 使用
autopct='%1.1f%%'参数显示每个扇形的百分比标签,并通过plt.title()函数设置图表标题,最后使用plt.show()函数显示图表。
- 使用
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
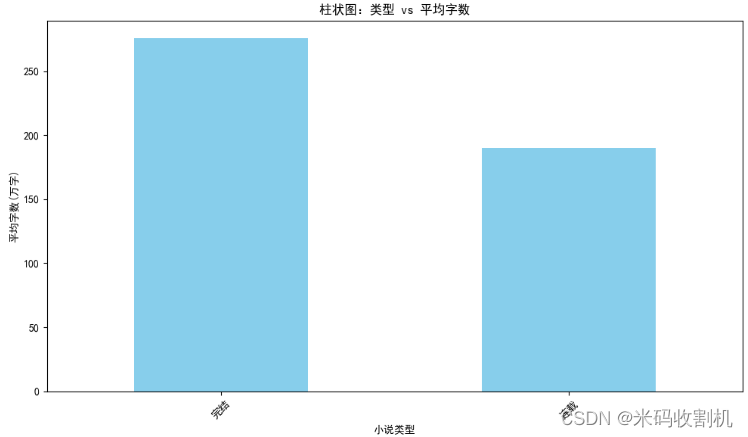
- 柱状图:类型 vs 平均字数
- 使用
groupby()函数按照小说类型对数据进行分组,然后使用mean()函数计算每种类型小说的平均字数。 - 通过
plot(kind='bar')函数绘制柱状图,横轴为小说类型,纵轴为平均字数(单位为万字)。 - 使用
plt.title()函数设置图表标题和坐标轴标签,最后使用plt.show()函数显示图表。
- 使用
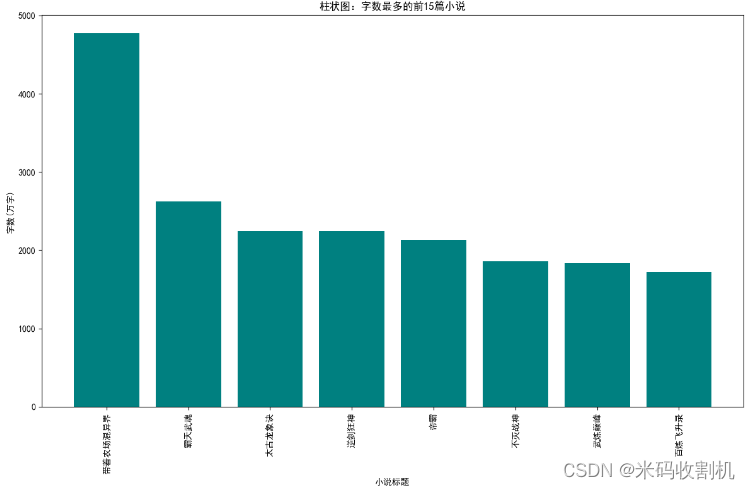
- 柱状图:字数最多的前15篇小说
- 使用
nlargest()函数选择字数最多的前15篇小说。 - 通过
plt.bar()函数绘制柱状图,横轴为小说标题,纵轴为字数(单位为万字)。 - 使用
plt.title()函数设置图表标题和坐标轴标签,通过plt.xticks()函数设置横坐标标签的旋转角度和对齐方式,最后使用plt.show()函数显示图表。
- 使用
- 词云图:标题
- 使用 WordCloud 库生成词云图,通过
generate()函数传入小说标题数据,生成词云图。 - 通过
plt.imshow()函数显示词云图,使用interpolation='bilinear'参数设置插值方法,使图像更加平滑。 - 最后通过
plt.axis('off')函数关闭坐标轴,plt.title()函数设置图表标题,最后使用plt.show()函数显示词云图。

- 使用 WordCloud 库生成词云图,通过
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
三、部分代码
import time
import requests
from lxml import etree
import csv
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
plt.rcParams["font.sans-serif"]=["SimHei"]
def save_data(data_list):
# 使用'utf-8-sig'编码来确保UTF-8文件可以正确地读取中文字符
# 略...
# 略...
# 略...
# 略...
# 略...
# 略...
# 略...> 👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
# 爬取url集合
url_dic = {
# 略....
# 略....
# 略.... # 略....> 👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
# 略.... # 略....
# 略.... # 略....
# 略.... # 略....
# 略....
}
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
save_data(["标题", "等级", "类型", "字数 ", "简介"]) # 标题
for url, page in url_dic.items():
for i in range(1, page + 1):
time.sleep(2)
nurl = url + str(i)
html = requests.get(url=nurl, headers=header)
for k in range(1, 20):
try:
# 提取页面信息
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# > 👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
except:
print("异常页数,已经略过...")
continue
time.sleep(3)
# 读取数据
df = pd.read_csv('noval_data1.csv')
# 首先进行替换(数据清洗)
df['字数 '] = df['字数 '].str.replace('万字', '', regex=False)
# 然后进行转换(数据处理)
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
# 略。。。。。。
> 👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
df['字数 '] = df['字数 '].apply(convert_to_wan)
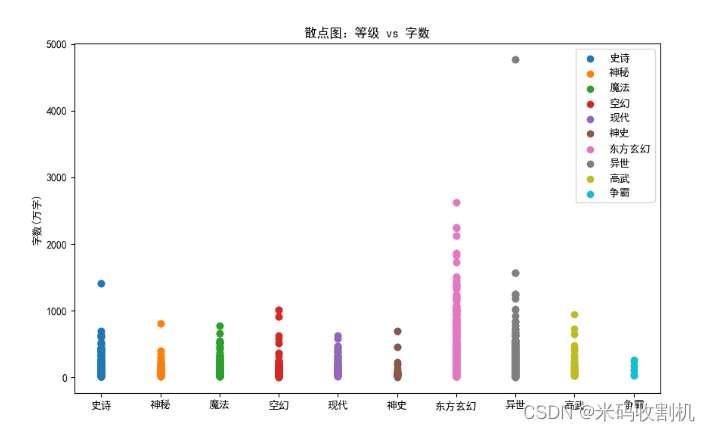
# 散点图:等级 vs 字数
plt.figure(figsize=(10, 6))
for level in df['等级'].unique():
plt.scatter(df[df['等级'] == level]['等级'], df[df['等级'] == level]['字数 '], label=level)
plt.title("散点图:等级 vs 字数")
plt.ylabel("字数(万字)")
plt.legend()
plt.show()
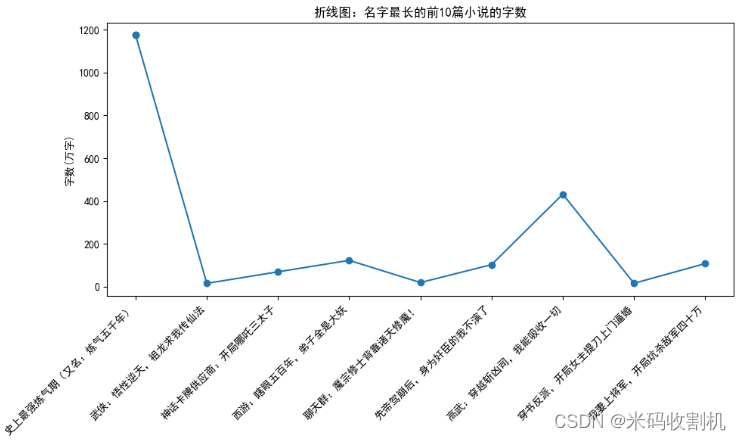
# 根据标题的长度进行排序并选取前10篇
top_10_longest_titles = df.sort_values(by='标题', key=lambda x: x.str.len(), ascending=False).head(10).copy()
# 折线图:按标题的字数
plt.figure(figsize=(10, 6))
plt.plot(top_10_longest_titles['标题'], top_10_longest_titles['字数 '], marker='o')
plt.title("折线图:名字最长的前10篇小说的字数")
plt.xticks(rotation=45, ha='right')
plt.ylabel("字数(万字)")
plt.tight_layout()
plt.show()
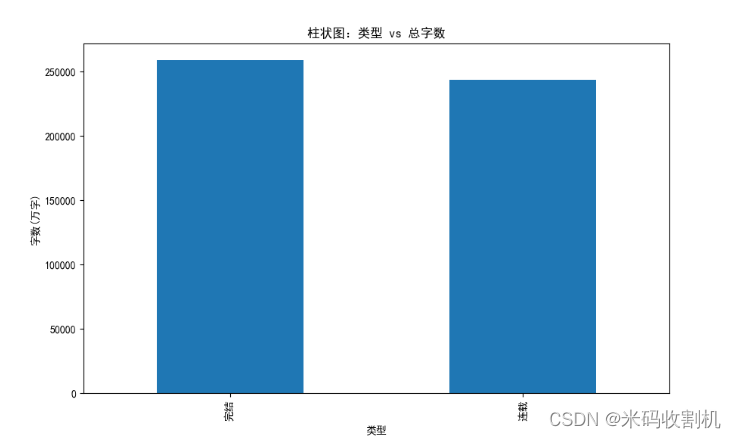
# 柱状图:按类型的总字数
type_sum = df.groupby('类型')['字数 '].sum()
type_sum.plot(kind='bar', figsize=(10, 6))
plt.title("柱状图:类型 vs 总字数")
plt.ylabel("字数(万字)")
plt.show()
# 饼图:每个类型的小说数量
type_counts = df['类型'].value_counts()
type_counts.plot(kind='pie', figsize=(8, 8), autopct='%1.1f%%')
plt.title("饼图:小说类型分布")
plt.ylabel("")
plt.show()
# 根据类型计算平均字数
avg_word_by_type = df.groupby('类型')['字数 '].mean()
# 柱状图:类型 vs 平均字数
plt.figure(figsize=(10, 6))
avg_word_by_type.plot(kind='bar', color='skyblue')
plt.title("柱状图:类型 vs 平均字数")
plt.ylabel("平均字数(万字)")
plt.xlabel("小说类型")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
> 👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
# 选择字数最多的前15篇小说
top_15_by_word_count = df.nlargest(15, '字数 ')
# 柱状图:标题 vs 字数
plt.figure(figsize=(12, 8))
plt.bar(top_15_by_word_count['标题'], top_15_by_word_count['字数 '], color='teal')
plt.title("柱状图:字数最多的前15篇小说")
plt.ylabel("字数(万字)")
plt.xlabel("小说标题")
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
# 词云图:标题
wordcloud = WordCloud(font_path=r'msyh.ttc', width=800, height=400, background_color='white').generate(' '.join(df['标题']))
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title("词云图:标题")
plt.show()
👉👉👉源码关注【测试开发自动化】公众号,回复 “ 小说数据抓取 ” 获取。👈👈👈
















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











