






普通的神经网络
输入input,经过Hidden得到Output,将Output与实际y对比差距,这个差距经过一系列计算,再输入input,改善output

改进神经网络——RNN
RNN的⽬的是让有sequential关系的信息得到考虑。
什么是sequential关系?
就是信息在时间上的前后关系。
相⽐于普通神经⽹络:

每个时间点中的S计算

这个神经元最终的输出, 基于最后⼀个S

简单来说,对于t=5来说,其实就相当于把⼀个神经元拉伸成五个 换句话说,S就是我们所说的记忆(因为把t从1-5的信息都记录下来了)
由前⽂可⻅,RNN可以带上记忆。 假设,⼀个『⽣成下⼀个单词』的例⼦: 『这顿饭真好』——>『吃』 很明显,我们只要前5个字就能猜到下⼀个字是啥了 However, 如果我问你,『穿⼭甲说了什么?』 你能回答嘛?
LSTM (长效短期记忆)
RNN

LSTM

LSTM中最重要的就是这个Cell State, 它⼀路向下,贯穿这个时间线, 代表了记忆的纽带。 它会被XOR和AND运算符搞⼀搞, 来更新记忆

⽽控制信息的增加和减少的, 就是靠这些阀⻔:Gate 阀⻔嘛,就是输出⼀个1于0之间的值: 1 代表,把这⼀趟的信息都记着 0 代表,这⼀趟的信息可以忘记了

模拟⼀遍信息在LSTM⾥跑
第⼀步:忘记⻔ 来决定我们该忘记什么信息
它把上⼀次的状态ht-1和这⼀次的输⼊xt相⽐较 通过gate输出⼀个0到1的值(就像是个activation function⼀样), 1 代表:给我记着! 0 代表:快快忘记!


第⼆步:记忆⻔ 哪些该记住
这个⻔⽐较复杂,分两步: 第⼀步,⽤sigmoid决定什么信息需要被我们更新(忘记旧的) 第⼆部,⽤Tanh造⼀个新的Cell State(更新后的cell state)

第三步:更新⻔ 把⽼cell state更新为新cell state ⽤XOR和AND这样的⻔来更新我们的cell state:

第四步:输出⻔ 由记忆来决定输出什么值
我们的Cell State已经被更新, 于是我们通过这个记忆纽带,来决定我们的输出: (这⾥的Ot类似于我们刚刚RNN⾥直接⼀步跑出来的output)


案例
以字母为元素点
维度1,下一个字母是什么?
以单词为元素点
维度2,下一个单词是什么?
同理
维度3,下一个句子?
维度N,下一个图片/音符...
RNN做文本生成
看LSTM怎么玩的
这里用温斯顿丘吉尔人物传记作为我们的学习资料
各种中文语料可以自行网上查找, 英文的小说语料可以从古登堡计划网站下载txt平文本
用讯飞/jieba分词
第一步,导入库
import numpy
from keras .models import Sequential
from keras.layers import Densefrom
from keras.layers import Dropout
from keras .layers import LSTM
from keras,callbacks import ModelCheckpoint
from keras.utils import np_utils文本读入
raw text = open('../input/Winston Churchil.txt').read()
raw text = raw text.lower()减小数据复杂度,尽量够集中
以每个字母为层级,字母总共才26个,所以我们可以很方便的用One-Hot来编码出所有的字母(当然,可能还有些标点符号和其他noise)
chars = sorted(list(set(raw text)))
char to int = dict((c, i) for i,c in enumerate(chars))
int to char = dict((i, c) for i,c in enumerate(chars))一共有多少
len(chars)源文本有多少
len(raw_text)简单的文本预测就是,给出前置字母,下一个字母是?
你如,Winsto 给出 n
第二步,构造训练测试集
把raw_text变成可以训练的x,y
x是前置字母们,y是后一个字母
for循环遍历整篇文章,given给出的东西,比如前100作为x,后面一个是y
seq length = 100
x = []
y = []
for i in range(0,len(raw text) - seg length):
given = raw text[i:i + seg length]
predict = raw text[i + seg length]
x.append([char to int[char] for char in given])
y.append(char to int[predict])print(x[:3])
print(y[:3])数据集长相

以上上这些表达方式,类似就是一个词袋,或者说 index。
接下来我们做两件事:
1,我们已经有了一个input的数字表达 (index),我们要把它变成LSTM需要的数组格式:[样本数,时间步伐,特征]
2,对于output,我们在Word2Vec里学过,用one-hot做output的预测可以给我们更好的效果,相对于直接预测一个准确的y数值的话。
想要的预测是从前100预测下一个字符,这个字符在0-61个字符中的某个,以实数形式预测y,在做误差学习偏差值太大(0-61这么大),于是将y的lable进行one-hot转化,从而最终预测的不是y这个值,而是将y变成62维的向量,每个向量点代表它是这个字符的可能性,最大的那个就是最终输出
n_patterns = len(x)
n_vocab = len(chars)
#把x变成LSTM需要的样子
x = numpy.reshape(x,(n_patterns,aeq_lengrh,i))
#简单norml到0-1之间
x = x/float(n_vocab)
#output变成one-hot
y = np_utils.to_categorical(y)
print(x[11])
print(y[11])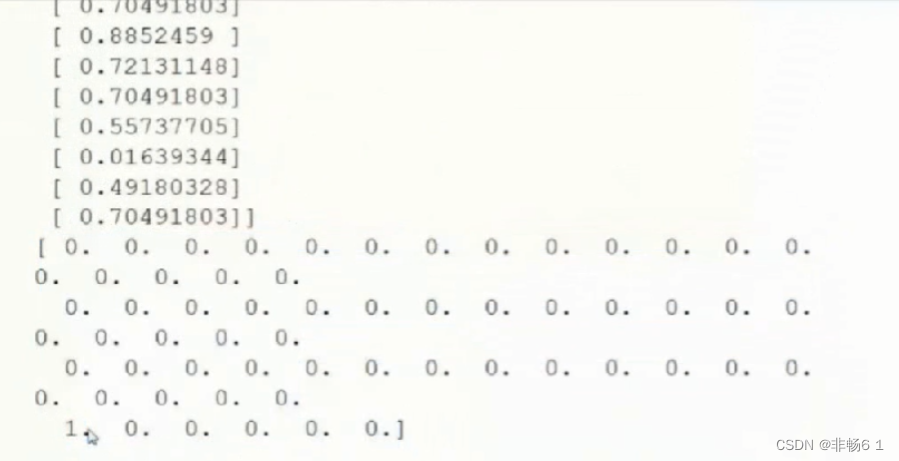
第三步,模型构造
LSTM构建
model= Sequential()
#128维
model.add(LSTM(128,input shape=(x.shape[1],x.shape[2])))
#防止over-fitting ,20%的神经元不作为考虑值
model.add(Dropout(0.2))
#加一层普通神经网络,LSTM最后计算完归拢,是整个学习曲线更加顺畅
model.add(Dense(y.shape[1], activation='softmax'))model.compile(loss='categorical crossentropy',optimizer-'adam')跑模型
model.fit(x,y,nb_epoch=10,batch_size=32)这个是非常简单的模型,只有128维的LSTM和62维的输出
第四步,模型评分
看看训练出来的LSTM模型效果
#把x转LSTM形式
def predict next(input array) :
x = numpy.reshape(input_array,(1, seq length,1))
x=x / float(n vocab)
y = model.predict(x)
return v
#把string变成一一对应的index
def string to index(raw input):
res=[]
for c in raw input[(len(raw input)-seq length):]:
res,append(char_to_int[c])
return res
#y变成一一对应的char
def y_to_char(y) :
largest_index = y.argmax()
c = int_to_char[largest index]
return c
或将这三个函数整合
def generate_article(init, rounds-500):
in_string = init.lower()
for i_in_range(rounds):
n = y_to_char(predict_next(string_to_index(in_string)))
in_string += n
return in_string生成文章
init = 'Professor Michael S. Hart is the originator of the Project'
article = generate article(init)
print(article)用单词做级
第一步,导入库
import os
import numpyas np
import nltk
from keras .models import Sequential
from keras .layersimport Dense
from keras .layers import Dropout
from keras,layers import LSTM
from keras.callbacksimport ModelCheckpoint
from keras.utils import np utils
from gensim.models.word2vec import Word2Vec文本读入
raw_text =''
for file in os.listdir("../input/"):
if file.endswith(".txt"):
raw_text += open("../input/"+file, errors='ignore').read() +'\n\n'
# raw_text = open('../input/Winston Churchil.txt').read()
raw_text = raw_text.lower()
sentensor = nltk.data.load('tokenizers/punkt/english.pickle')
sents = sentensor.tokenize(raw text)
corpus =[]
for sen in sents:
corpus.append(nltk.word tokenize(sen))
print(len(corpus))
print(corpus[:3])
w2v乱炖:给出单词的位置坐标
w2v_model = Word2Vec(corpus,size=128,window=5,min count=5,workers=4)w2v model['office']
接下来,还是以之前的方式来处理我们的training data,把源数据变成一个长长的x,好让LSTM学会predict下一个单词:
raw_input = (item for sublist in corpus for item in sublist]
len(raw input)raw_input[12]text_stream = []
vocab = w2v model.vocab
for word in raw input:
if word in vocab:
text_stream.append(word)
len(text_stream)我们这里的文本预测就是,给了前面的单词以后,下一个单词是谁?
比如,hello from the other, 给出 side
第二步,构建训练测试集
把raw_text变成用来训练的x,y
x是前置单词们,y是后一单词
seq length=10
x-[]
y=[]
for i in range(0,len(text stream) - seg length):
given = text stream[i:i + seq length]
predict = text stream[i + seq length]
x.append(np.array([w2v model[word] for word in given])) #每个单词对应得词向量放出来
Y.append(w2v model[predict])看看数据集长相
print(x[10])
print(y[10])每一维都变成128维字符

print(len(x))
print(len(y))
print(len(x[12]))
print(len(x[12][0]))
print(len(y[12]))
x = np.reshape(x,(-1, seg length,128)
y = np.reshape(Y,(-1,128))
接下来我们做两件事:
1,我们已经有了一个input的数字表达(w2v),我们要把它变成LSTM需要的数组格式:[样本数,时间步伐,特征]
2,对于output,我们直接用128维的输出
第三步,建模
LSTM模型构造
model = Sequential()
model.add(LSTM(256,dropout W-0.2,dropout U-0.2,input shape=(seqlength,128)))
model.add(Dropout(0.2))
model.add(Dense(128,activation-'sigmoid'))
model.compile(loss-'mse',optimizer-'adam')run模型
model.fit(x,y,nb epoch=50,batch size=4096)第四步,模型效果
def predict next(input array):
x=np.reshape(input array,(-1,seq length,128))
y = model.predict(x)
return y
def string to index(raw input):
raw input = raw input.lower()
input stream = nltk.word tokenize(raw input)
res=[]
for word in input stream[(len(input stream)-seq length):]:
res.append(w2v model[word])
return res
def y to word(y):
word = w2v model.most similar(positive=y, topn=1)
return worddef generate article(init, rounds-30):
in string = init.lower()
for i in range(rounds):
n = y to word(predict next(string to index(in string)))
in string+=+n[0]10]
return in stringinit = 'Lanquage Models allow us to measure how likely a sentences,which is an important for Machine'
article = generate article(init)
print(article)深度学习在图片中得应用
对图⽚的特征计算/创造/统计也会更加直观,包括:SIFT, HOG, LBP, Haar
基本就是把图⽚中的 颜⾊,形状,深浅,等等信息各种组合
图片必用算法——CNN

什么是卷积?
两个方程相遇造出一个新方程

 通过类似滤镜得东西,将图片变成不同样式得图片,通过不同样式图片,看到更多特征,将特征进一步分类i
通过类似滤镜得东西,将图片变成不同样式得图片,通过不同样式图片,看到更多特征,将特征进一步分类i

i
pooling

两种Pooling⽅式:

综合成⼀个模型:

对⽐特征提取+神经⽹络

案例
图片搜索器
用一张图片来搜索跟它相似得图片
分四步:
1、生成图片特征
2、Index数据库
3、比较相似度
4、搜索走起~
跟之前课上讲过的高维数据数据一样,图片搜索器也就是把图片变成了一个个特征向量,然后我们通过比较特征向量的相似度,来判断该返回哪一个值。
图片特征
OpenCV可以读入图片,并得到色彩直方图,用它作为特征数据
定义一个类HistogramGeneralor(色彩直方图数据生成器)
import numpy as np
import cv2
class HistogramGenerator:
def init (self,bins):
# bin指的是RGB中每个颜色有多少色城(有点像0-255的分块)
self.bins = bins
def generate(self, image) :
# calcHist就是calculate Histogram的意恩
# 签名如下: cv2.calcHist(images,channels,mask,histSize,ranges!,histl,accumulatelj)
hist = cv2.calcHist([image],[0,1,2].
None,self.bins,[0,256,0,256,0,256])
#平滑一下曲线
hist = cv2.normalize(hist, hist)
#因为我们有三个颜色,上面一步完变成一个3D的数组了。
#3D搞起运算来太麻烦,我们直接fltten成1D数组
return hist.flatten()读入图片
import os
import random
文件夹
DIR -../input/train/
#狗图片
image dogs=[DIR+i for i in os.listdir(DIR) if'dog'in i]
image cats=[DIR+i foriin os.listdir(DIR) if'cat'in i]
#各取前20个
images = image dogs[:20] + image cats[:20]
#洗牌
random.shuffle(images)Index图片特征
简单说就是把所有的图片库都跑一遍,generate出他们的色彩直方图
#把那个生成器先init了
#我选个小一点的色域。你们可以弄到足够大 -->[255,255,255]
hist generator = HistogramGenerator([8,8,8])
index=[]
for image in images:
#读入图片
image data = cv2.imread(image)
#特征值
feature = hist generator.generate(image data)
#存进我们的index dict中
index[image] = feature相似度
我们可以用各种方法来算两个向量的相似度(cos,squared distance 等等)
这次我们用个卡方距离:

def similarity(x,y,eps = 1e-10):
sim=0.5*np.sum([((a- b)**2) /(a+b+eps)
for (a,b) in zip(x,y)])
return sim搜索器
输入是我们的图片路径,输出是排好的相似图片
import numpy as np
def search(search dir):
#把我们要输出的结果放起来
results = {}
#读入图片
image data = cv2.imread(search dir)
# 特征值
search feature = hist generator.generate(image data)
#搜索嘛,就得全部数据库都跑一遍
for (k, features) in index.items():
sim = similarity(features, search feature)
#记录结果
results[k]=sim
# 按照相似度高低排个序
results = sorted(l(v, k) for (k,v) in results.items()])print(results)
以上图片搜索算法太out,基于人为制造特征
案例:猫狗辨别
标准的ConvNet做图片分类
导入库
import os, cv2,random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
import seaborn as sns
%matplotlib inline
from keras.models import Sequential
from keras.layers import Input, Dropout, Flatten, Convolution2D,MaxPooling2D,Dense,Activation
from keras.optimizers import RMSprop
from keras.callbacks import ModelCheckpoint, Callback,EarlyStopping
from keras.utils import np utils
准备数据
我们先把所有的数据load进来因为时间关系,就不train所有的数据集了。。太慢。我把猫和狗里面各拿出100个来跑一个:
TRAIN DIR =../input/train/'
TEST DIR =../input/test/'
#把猫和狗分开读入
#想全部读入的话,就把那个if去掉
#记得把label也存好(0/1)
train dogs = [{TRAIN DIR+1}for i 1n os.listdir(TRAIN DIR) if dog in i]
train cats = [(TRAIN DIR+i,0) for i in os.listdir(TRAIN DIR) if 'cat in i]
#训练集还是得全盘放进来的
#这个testset就随使放个label
test_images = [(TEST DIR+i,-1) for i in os.listdir(TEST DIR)]
#合成一个数据集(取个100个玩玩)
train images = train dogs[:100] + train cats[:100]
#把数据散好
random.shuffle(train images)
#取个10个玩玩
test images= test images[:10]
我们需要用到OpenCV去读入图片 (IMREAD())
为了图片标准统一,我们把所有的图片resize进64*64的方格
ROWS=64
COLS=64
def read image(tuple set):
file path = tuple set[0]
label = tuple set[1]
imq = cv2.imread(file path,Cv2.IMREAD COLOR)
#你这里的参数,可以是彩色或者灰度(GRAYSCALE)
return cv2.resize(img, (ROWS,COLS),interpolation-cV2.INTER CUBIC), label
# 这里,可以选择压缩图片的方式,zoom (cv2.INTER CUBIC6CV2.INTER LINEAR)还是shrink (cv2.INTER AREA)预处理图片:,把图片数据变成我们便于用的numpy数组
CHANNELS =3
# 代表RGB三个颜色频道
def prep data(images) :
no_images = len(images)
data = np.adarray((no_images,.CHANNELS,ROWS,COLS),dtype=np.uint8
labels =[]
for i, image file in enumerate(images):
image,label = read image(image file)
data[i] = image.T
labels.append(label)
return data, labels好的,这下我们可以一步刷完所有的train和test集了这个我们有个木有用的y_shit,记得扔一边儿去
x+train,y_train = prep_data(train_images)
y_test,y_shit = prep_data(test_images)查看shape
print(x train.shape)
print(x test.shape)CNN模型构造
VGG_CNN,16->32->64->128->256,每一层都是一个Convlusion_Network
optimizer=RMSprop(lr=le-4)
objective = 'binary_crossentropy'
#建造模型
model= Sequential()
model.add(Convolution2D(32,3,3,border mode='same',input shape(3,ROWS,COLS), activation='relu'))
model.add(Convolution2D(32,3,3,border mode='same',activation=elu'))
model.add(MaxPooling2D (ool size=(2,2)))
model.add(Convolution2D(64,3,3,border mode='same',activation=elu'))
model.add(Convolution2D(64,3,3,border mode='same',activation=elu'))
model.add(MaxPooling2D(pool size=(2,2)))
model.add(Convolution2D(128,3,3,border mode='same',activation='relu'))
model.add(Convolution2D(128,3,3,border mode='same',activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(256,3,3,border mode='same', activation='relu'))
model.add(ConvolutioR2D(256,3,3,border mode='same', activation='relu'))
model.add(MaxPooling2D(pool size=(2,2)))
model.add(Flatten())
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss=objective, optimizer=optimizer,metrics=['accuracy'])训练与预测
这里,做图片处理,很容易overfitting,我们可以用keras自带的earlyStopping来检测validation data (取20%数据)。
nb epoch = 10
batch size = 10
## 每个epoch之后,存下loss,便于画出图
class LossHistory(Callback):
def on train begin(self, logs=[l) :
self.losses = []
self.val_losses = []
def on epoch end(self, batch, logs-{l):
self.losses.append(logs .get('loss'))
self.val losses .append(logs.get('val loss'))
early stopping = EarlyStopping(monitor-'val loss',patience=3, verbose=1,mode='auto')
#跑模型
history = LossHistory()
model.fit(x train, ytrain, batch size-batch size, nb epoch=nb epoch,
validation split=0.2,verbose=0,shuffle=True, callbacks=[history,early_stopping])
predictions = model.predict(x test, verbose=0)将loss打印出来
loss = history.losses
val_loss = history.val losses
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('VGG-16 Loss Trend')
plt.plot(loss,"blue', label='Training Loss')
plt.plot(val loss,'green',label-'Validation Loss')
plt.xticks(range(0,nb epoch)[0::2])plt.legend()
plt.show()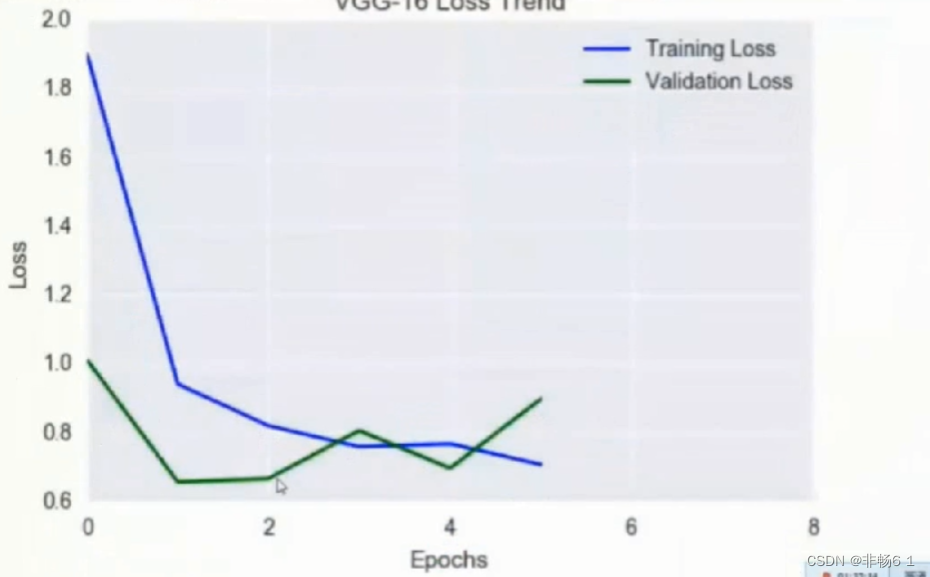















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









