







 本文详细介绍了作者遇到的Zookeeper、Clickhouse和Dolphinscheduler在实际运行中遇到的故障情况,包括故障描述、原因分析和具体的解决步骤。针对Zookeeper,问题在于系统盘负载过高影响服务;Clickhouse因内存耗尽导致无法启动;Dolphinscheduler的调度任务失败与Zookeeper服务异常有关。通过调整配置、清理缓存和重启服务等措施,成功恢复了系统正常运行。
本文详细介绍了作者遇到的Zookeeper、Clickhouse和Dolphinscheduler在实际运行中遇到的故障情况,包括故障描述、原因分析和具体的解决步骤。针对Zookeeper,问题在于系统盘负载过高影响服务;Clickhouse因内存耗尽导致无法启动;Dolphinscheduler的调度任务失败与Zookeeper服务异常有关。通过调整配置、清理缓存和重启服务等措施,成功恢复了系统正常运行。
前言:今天这篇文章我主要讲一下我以前遇到的【Zookeeper故障】以及解决方案,供大家后续遇到类似问题是方便排查问题!
Zookeeper故障说明以及解决方案
一、故障情况描述
- CDH Zookeeper报警:
Maximum Request Latency - Clickhouse数据库
node1、node2节点无法启动 - Dolphinscheduler调度任务实例运行失败
二、Zookeeper故障原因及处理步骤
1、现象
- 发生故障时最大请求延迟超过设定阈值,CDH健康值检查异常触发告警
2、观察
- 观察
Zookeeper日志中出现“ZooKeeperServer not running” / “fsync-ing the write ahead log in SyncThread:2 took 1415ms which will adversely effect operation latency”
3、定位
- 初步定位为UAT环境
Zookeeper数据目录配置在系统根目录中,系统其他进程读写系统盘负载过高会影响到Zookeeper服务。
Zookeeper服务返回响应前,会将事务日志写入存储介质,事务日志写入介质慢会导致响应时间超时, 触发Maximum Request Latency报警和集群通信异常。
4、处理步骤
- 临时重启
Zookeeper服务恢复集群 - 在低峰期将
Zookeeper数据目录跟系统盘分离,更改数据目录到/apps数据盘
三、Clickhouse数据库故障原因及处理步骤
1、现象
- uat环境部分节点
clickhouse-server服务无法正常启动,初步判断为Zookeeper集群异常影响
2、观察
- 重启
Zookeeper集群后再次重启clickhouse服务故障依旧存在,观察/apps/dolphinscheduler/dolphinscheduler/logs/clickhouse-server.err.log日志出现大量删除表数据操作。
删除操作将系统内存耗尽,进程异常退出
3、处理步骤
- 手动删除
/apps/clickhouse/data/data/tdm_dc_local/user_member目录缓存文件后再次启动clickhouse-server服务恢复正常 - 为避免问题再次复现,已将系统
min_free_kbytes(内存垃圾回收阀值)调整为1G
四、Dolphinscheduler调度故障原因及处理步骤
1、现象
- 任务实例运行失败 (Web界面无日志输出)
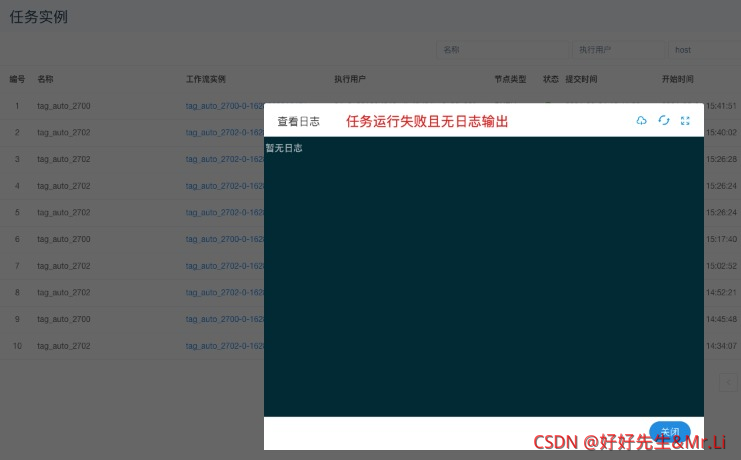
2、观察
- 观察
/apps/dolphinscheduler/dolphinscheduler/logs/dolphinscheduler-worker.log日志出现“Name node is in safe mode”(zookeeper服务异常导致HDFS进入安全模式)

3、处理步骤
- 等待
zookeeper服务恢复正常后重启CDH集群NameNode节点,再次重启dolphinscheduler服务恢复正常
五、疑问解答与加群交流学习




















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











