







Mask R-CNN论文阅读笔记
三个重要概念的区别
物体检测,语义分割,实例分割三者之间的区别
物体检测(object detection)的目标是确定每个物体的类别,并用bounding box标记出每个物体的位置。
语义分割(semantic segmentation)的目标是像素级别的确定每个物体的分类及位置,但不区分同一类别的不同个体。
实例分割(instance segmentation)的目标是在语义分割的基础上进一步区分不同的实例。

论文提出背景
物体检测和语义分割的快速发展受益于强有力的基础架构的提出,比如物体检测的Faster R-CNN,语义分割的FCN,但FCN通常执行每像素多类分类(per-pixel multi-class categorization),分割和分类同时进行,基于我们的实验,FCN对于目标分割效果不佳。但这些方法都没有区分不同的实例,这就是Mask R-CNN提出的原因。
主要贡献
1.在Faster R-CNN原有的基础上拓展了一个新的分支来在每个ROI上像素级别地预测分割masks,该分支与原有的classification 、bounding box regression并行进行。
2.对于Fast/Faster R-CNN缺失的像素级别的输入与输出的对齐,本文提出了 RoIAlign 方法解决这一问题,忠实得保留了精确的空间位置。
3.发现将掩码和类别预测解耦至关重要:独立地为每个类别预测一个二进制掩码,类别之间没有竞争,并且依靠网络的ROI分类分支来预测类别。相比之下,FCNs通常以像素为单位进行多类分类,将分割和分类结合在一起,基于实验发现对于实例分割效果很差。
相关工作
Instance segmentation实例分割
- 早期方法 [13, 15, 16, 9] :bottom-up segments(???不理解)
- DeepMask [33] and following works [34, 8] :先提出分割建议,再利用Fast-RCNN进行分类
以上方法分割早于分类,速度慢且不准确
- Dai et al. [10] :提出了一种多阶段级联的方法,从bounding box 建议中预测分割建议,最后做分类
- Li et al. [26]提出FCIS将分割建议与物体检测系统融合,核心思想是训练一个对位置敏感的卷积网络,同时预测分类,boxes位置和mask。该方法速度得到提升,但对于重叠实例表现较差
- 对每个像素进行多分类 [23, 4, 3, 29]:试图将相同类别的像素分割成不同的实例
- Mask R-CNN:分割与bounding box回归和分类平行进行
损失函数
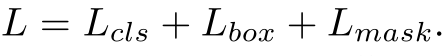
- 第一项的第二项的定义与Fast R-CNN相同
- Mask输出为K×(m×m)维,对每个像素应用sigmoid(判断是前景还是背景),损失函数为average binary cross-entropy loss.仅在真实标签为K的ROI区域上计算mask损失(还没有搞清楚,暂时理解是下图)
- 之前利用将FCN应用于像素级softmax和多重交叉熵损失的语义分割在实例分割任务上会造成类间竞争

原文如下,理解了修改
we rely on the dedicated classification branch to predict the class label used to select the output mask. This decouples mask and class prediction.
我们依靠专用分类分支来预测用于选择输出掩码的类别标签。这分离了掩码和类预测。
 (产生k个m*m的预测??
(产生k个m*m的预测??
做到像素对齐的原因
Mask 对输入对象的空间布局进行了编码,提取mask的空间结构可以通过卷积提供的像素到像素的对应关系来进行处理。(分类和box 偏移通过全连接层被压缩为短的输出向量,因此损失了空间信息)
具体来说,用FCN对每个ROI区域预测m×m的mask,这允许mask分支中的每个层保持显式的m×m对象空间布局,而不会将其折叠为缺乏空间维度的矢量表示。
ROIPool实现步骤
- 量化(取整):首先将ROI浮点数量化为特征映射的离散粒度(granularity)
- 将量化后的ROI细分到已经被量化的spatial bin(**bin怎么量化???**比如15×15的一张图要分成4个bin(2×2)则15÷2就会四舍五入)
- 池化:对每个bin进行池化操作(通常是max pooling)
量化导致了ROI与提取的特征之间无法对齐,虽然这不会对分类结果产生影响,因为分类对小幅度的变换具有一定的鲁棒性,但对于预测像素精度的mask会产生很大的负面影响。
ROIAlign实现细节
为了处理上述问题,本文作者提出了ROIAlign层,移除了ROIPool的量化操作(boundaries和bin)
 (下图步骤还没搞清楚
(下图步骤还没搞清楚

具体实现: 使用双线性插值来计算每个ROI bin中四个规则采样位置的输入特征的精确值,并聚合结果(max/average pooling)

Feature Pyramid network(FPN)[27]提取特征更有效,了解一下!!
网络结构
Faster R-CNN结构
 Mask R-CNN整体结构
Mask R-CNN整体结构

头部网络结构

特征金字塔网络


- (a)先生成多个尺度的图片,在分别提取特征形成特征图,最后分别做预测
- (b)对原始图片多次提取特征,在最后一个特征图上做预测(SPPnet/Fast/Faster采用 )
- (c)对原始图片多次提取特征,每个特征图都进行预测(SSD采用)
- (d)将顶层特征图通过上采样的方式生成底层特征图,再分别预测
 卷积过程中,特征图尺寸不改变的层称为一个stage,将每个stage最后一个特征图输出形成特征金字塔
卷积过程中,特征图尺寸不改变的层称为一个stage,将每个stage最后一个特征图输出形成特征金字塔
训练细节
- 超参数设置遵循Fast/Faster R-CNN中的设置
- IOU>0.5为正例,mask损失仅在正例上计算
- mask的目标是ROI与其相关联的标签mask的交集
测试细节
- 提出区域建议:C4架构的网络建议数为300,FPN为1000
- 在区域建议上运行边框预测
- 非极大值抑制
- 在置信度前100个建议区域运行mask 分支
测试时并未采用训练时的三个分支平行进行,加快了测试速度,提升了准确率(因为使用了更少、更准确的ROI)
掩码分支可以预测每个ROI的K个mask,但是我们只使用第k个mask,其中k是分类分支预测的类别。然后,将m×m浮点数mask输出的大小调整为ROI大小(??),并以0.5的阈值将其二值化
实验结果分析
a)底层网络
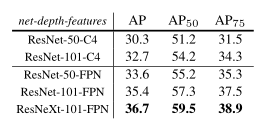
- 更好的底层网络带来了预期的收益
- 更深的网络做的更好
- FPN优于C4
AP50表示average precision > 0.5的概率
















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









