









发表期刊:2013-ICLR
单位:google
摘要:word2vec主要包括两种模型,分别是skip-gram和CBOW,skip-gram使用中心词来预测周围词,CBOW使用周围词来预测中心词。还介绍了两种加速softmax计算的方法,分别是层次softmax和负采样,softmax的核心思想是将将多分类转化为多层的二分类;负采样的核心思想是将多分类问题转化为二分类问题(判断是正样本还是负样本)。最后还介绍了重采样的技术:降低高频词的训练次数,提高低频词的训练次数,从而达到加速训练的目的
语言模型(判断一个句子是否是句子的模型)应用场景:输入法打出一串字排名靠前的选项是目标语句的可能性更高



统计语言模型存在的问题:一些没有在语料库中出现的句子并不意味着现实生活中不可能出现(句子越长,在预料中出现的概率越低)

面临的问题:
1)参数空间过大;(概率和条件概率都是参数)
2)数据稀疏严重;(只有很少的参数不为0,其余都为0)
马尔科夫假设:下一个词出现的概率仅依赖于前面的一个词或几个词
unigram:一个词出现的概率仅和自己本身有关(参数空间为V)
bigram: 一个词出现的概率仅和前面的一个词有关(参数空间为V+V*V)
k-gram:一个词出现的概率仅和前面的k-1个词有关(参数空间为V+V**2+…+V**k)


语言模型评价指标
困惑度:句子概率越大,困惑度越小,语言模型越好(因为测试集给的都是正常的句子)。
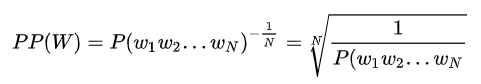
词的表示方式:
独热编码:优点是表示简单,缺点是词越多,向量维度越大,且无法表示词与词之间的关系。
分布式编码:优点是维度得到极大的降低,且可以表示词之间的关系。


SVD分解:抛弃不重要的特征


相关工作:
- 基于全连接网络的语言模型(NNLM)
模型输入为词的index,经过映射成为低维向量,然后将所有的输入层向量拼接到一起,然后输入hidden layer(全连接层),之后再接一个全连接层,softmax作为激活函数得到每个词的概率,词的概率相乘得到句子的概率。
模型优点:不需要标注数据,因此句子确定,下个词也就确定。
可能的改进方向:
- 仅对一部分输出进行梯度传播(有些冠词出现频率很高但对模型作用不大)
- 引入先验知识,如词性等(网络本身能否学习到词性信息)
- 解决一词多义问题
- 改进softmax层加速运算

- 基于RNN的语言模型(RNNLM)
每个时间步预测一个词,在预测第n个词时使用了前n-1个词的信息
Log线性模型:将语言模型的建立看成一个多分类问题,相当于线性分类器加上softmax。(对等式两边同时做log运算,等式右边变为线性函数)
语言模型的核心思想:句子中下一个词的出现和前面的词是有关系的,所以可以使用前面的词来预测下一个词。
本文提出的模型(Word2vec):核心思想是句子中相互靠近的词是有联系的,因此本文的提出的两个模型分别使用周围词预测中心词、使用中心词预测周围词。
Skip-gram
- 使用中心词预测周围词(每个中心词产生2 * window size个训练样本)

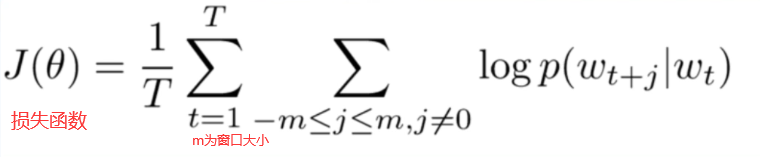
Continuous bag-of-words(CBOW)
- 使用周围词预测中心词(每个中心词产生一个训练样本)
bag-of-words描述的原因:将周围词向量进行sum和avreage,忽略了词的顺序进行预测。

两种降低softmax复杂度的方法
- 层次softmax:核心思想是将softmax转化为多层的sigmoid
- 负采样:核心思想是将多分类问题转化为二分类问题(判断是正样本还是负样本)
- 正样本为中心词和真正的周围词;负样本为中心词和随机采样的词;模型最大化正样本的概率。
Hierarchical softmax
进一步改进:huffman树
"""
构建霍夫曼树
"""
class HuffmanNode:
def __init__(self, word_id, frequency):
self.word_id = word_id # 叶子结点存词对应的id, 中间节点存中间节点id
self.frequency = frequency # 存单词出现频次
self.left_child = None
self.right_child = None
self.father = None
self.Huffman_code = [] # 霍夫曼码(左1右0)根到目标节点的编码
self.path = [] # 根到叶子节点的中间节点id
class HuffmanTree:
def __init__(self, wordid_frequency_dict):
self.word_count = len(wordid_frequency_dict) # 单词数量
self.wordid_code = dict() # 每个词id对应一个code
self.wordid_path = dict() # 每个词id对应一个path
self.root = None
unmerge_node_list = [HuffmanNode(wordid, frequency) for wordid, frequency in
wordid_frequency_dict.items()] # 初始化一个未合并节点list
self.huffman = [HuffmanNode(wordid, frequency) for wordid, frequency in
wordid_frequency_dict.items()] # 初始化一个存储所有的叶子节点和中间节点的list
# 构建huffman tree
self.build_tree(unmerge_node_list)
# 生成huffman code
self.generate_huffman_code_and_path()
def merge_node(self, node1, node2):
sum_frequency = node1.frequency + node2.frequency
mid_node_id = len(self.huffman) # 中间节点的value存中间节点id
father_node = HuffmanNode(mid_node_id, sum_frequency) # 初始化父亲节点
if node1.frequency >= node2.frequency: # 出现频率大的词放左边
father_node.left_child = node1
father_node.right_child = node2
else:
father_node.left_child = node2
father_node.right_child = node1
self.huffman.append(father_node)
return father_node
def build_tree(self, node_list): # 传入未合并节点
while len(node_list) > 1:
i1 = 0 # 假设出现频次最小的节点
i2 = 1 # 假设出现频次第二小的节点
if node_list[i2].frequency < node_list[i1].frequency: # 如果假设不成立,交换i1和i2
[i1, i2] = [i2, i1]
for i in range(2, len(node_list)): # 遍历更新i1和i2
if node_list[i].frequency < node_list[i2].frequency:
i2 = i
if node_list[i2].frequency < node_list[i1].frequency:
[i1, i2] = [i2, i1]
father_node = self.merge_node(node_list[i1], node_list[i2]) # 合并最小的两个节点
if i1 < i2:
node_list.pop(i2) # 删节点,先删索引大的节点,删完之后索引小的节点索引不变
node_list.pop(i1)
elif i1 > i2:
node_list.pop(i1)
node_list.pop(i2)
else:
raise RuntimeError('i1 should not be equal to i2')
node_list.insert(0, father_node) # 插入新节点
self.root = node_list[0]
def generate_huffman_code_and_path(self):
stack = [self.root] # 根节点入栈
while len(stack) > 0:
node = stack.pop() # 出栈
# 顺着左子树走
while node.left_child or node.right_child:
code = node.Huffman_code
path = node.path
node.left_child.Huffman_code = code + [1] # 左孩子的code 增加[1]
node.right_child.Huffman_code = code + [0]
node.left_child.path = path + [node.word_id] # 增加id
node.right_child.path = path + [node.word_id]
stack.append(node.right_child) # 把没走过的右子树加入栈
node = node.left_child # 从左孩子继续遍历
word_id = node.word_id # 每个退出循环的结点都是叶节点,这些节点存储了单词
word_code = node.Huffman_code
word_path = node.path
self.huffman[word_id].Huffman_code = word_code
self.huffman[word_id].path = word_path
# 把节点计算得到的霍夫曼码、路径 写入词典的数值中
self.wordid_code[word_id] = word_code
self.wordid_path[word_id] = word_path
def get_all_pos_and_neg_path(self):
# 获取所有词的正向节点id和负向节点id数组(没看懂)
positive = [] # 所有词的正向路径数组
negative = [] # 所有词的负向路径数组
for word_id in range(self.word_count):
pos_id = [] # 存放一个词 路径中的正向节点id
neg_id = [] # 存放一个词 路径中的负向节点id
for i, code in enumerate(self.huffman[word_id].Huffman_code):
if code == 1:
pos_id.append(self.huffman[word_id].path[i])
else:
neg_id.append(self.huffman[word_id].path[i])
positive.append(pos_id)
negative.append(neg_id)
return positive, negative
def test():
word_frequency = {0: 4, 1: 6, 2: 3, 3: 2, 4: 2}
print(word_frequency)
tree = HuffmanTree(word_frequency)
print(tree.wordid_code)
print(tree.wordid_path)
for i in range(len(word_frequency)):
print(tree.huffman[i].path)
print(tree.get_all_pos_and_neg_path())
if __name__ == '__main__':
test()
层次softmax的构建:
skip-gram的构建
n(w,j)在词w的路径上的第j个节点(图中黄色箭头)
CBOW的构建:
负采样:核心思想是将多分类问题转化为二分类问题(判断是正样本还是负样本)
skip-gram:
采样方法:
CBOW:
加速训练方法:
重采样:把高频词从训练集中删除一些,提高低频词的训练次数。
实验及结果:

通过表2的实验发现,随着表示维度和数据集的增大,模型的表现越来越好。
从表3的结果来看,语义任务的完成结果并没有多好,还需要进一步研究
Skip-gram完成了在语义任务上的最好表现,而语法任务是改进后的NNLM表现最好,原因在于使用softmax之后,可供训练的数据集更大(比之前的使用的最大的数据集还大了大约10倍)。
skip-gram训练时间比CBOW长,但效果更好
从训练时间和模型表现上都能看出本文提出的模型更好(疑问:CBOW和Skip-gram不也是全连接层吗?)
(疑问:这个任务及作者提出的方法究竟是怎么做的?)
层次softmax与负采样的比较:从表中可以看出负采样所需训练时间更短,且得到的效果更好,下表展示了使用重采样的结果,大大加速了模型的训练。
超参数的选择:
本文贡献:



Wikipedia英文语料,包含wikipedia里面的所有文章,可以在https://dumps.wikimedia.org/enwiki/latest/ 上下载
论文中介绍的词对推理语料,包含五个语义类和九个语法类。其中有8869个语义对样本和10675个语法对样本。可以在http://www.fit.vutbr.cz/~imikolov/rnnlm/word-test.v1.txt 上下载。
skip-gram + NGE代码的实现
数据预处理
import numpy as np
from collections import deque
# deque为队列,用来读取数据
class InputData:
def __init__(self, input_file_name, min_count):
self.input_file_name = input_file_name
self.index = 0
self.input_file = open(self.input_file_name, "r", encoding="utf-8")
self.min_count = min_count
self.wordid_frequency_dict = dict() # 记录词id的频率,key为id,value为出现次数,用于重采样
self.word_count = 0
self.word_count_sum = 0 # 词的数量
self.sentence_count = 0 # 句子的数量
self.id2word_dict = dict() # 构建 id2word的字典, key为id,value为词
self.word2id_dict = dict() # 构建 word2id的字典
self._init_dict() # 初始化dic,构建word2id,id2word,id2fre,
self.sample_table = []
self._init_sample_table() # 获得负样本采样表
self.get_wordId_list() # 将词的列表转化为id的列表
self.word_pairs_queue = deque()
# 结果展示
print('Word Count is:', self.word_count)
print('Word Count Sum is', self.word_count_sum)
print('Sentence Count is:', self.sentence_count)
def _init_dict(self):
word_freq = dict() # key为word, value为出现的次数
for line in self.input_file:
line = line.strip().split() # strip 去除首尾的空格,split()使用空格进行分词
self.word_count_sum += len(line) # 词的个数等于各行词数相加
self.sentence_count += 1 # 每遍历一行,句子数+1
for i, word in enumerate(line):
if i % 1000000 == 0:
print(i, len(line)) # 进度显示
if word_freq.get(word) == None:
word_freq[word] = 1 # 如果当前词不在统计的字典中, 设词频为1
else:
word_freq[word] += 1 # 出现一次,词频+1
for i, word in enumerate(word_freq): # 遍历字典中的每个对象 key-value对
if i % 100000 == 0:
print(i, len(word_freq))
if word_freq[word] < self.min_count:
self.word_count_sum -= word_freq[word] # 如果词出现次数小于min_count,舍弃
continue
self.word2id_dict[word] = len(self.word2id_dict) # 构建 word2id,一个一个添加词,因此可以使用字典长度作为id
self.id2word_dict[len(self.id2word_dict)] = word # 构建 id2word
self.wordid_frequency_dict[len(self.word2id_dict) - 1] = word_freq[word] # 构建 id2frequency
self.word_count = len(self.word2id_dict) # (去重?应该是去除低频词吧)后词的数量
def _init_sample_table(self): # 获得负样本采样表
sample_table_size = 1e8 # 采样表大小
pow_frequency = np.array(list(self.wordid_frequency_dict.values())) ** 0.75 # 采样公式
word_pow_sum = sum(pow_frequency) # 求和获得归一化参数 Z
ratio_array = pow_frequency / word_pow_sum # 得到采样频率
word_count_list = np.round(ratio_array * sample_table_size) # round 四舍五入函数
# ratio_array size=[num_word,]; 相乘得到采样表中每个词的出现次数
for word_index, word_freq in enumerate(word_count_list):
self.sample_table += [word_index] * int(word_freq)
# 按采样频率估计的次数将词放入词表,比如词表大小是10,apple出现的频率为0.2,则词表中放2个apple
self.sample_table = np.array(self.sample_table)
np.random.shuffle(self.sample_table)
def get_wordId_list(self): # 将词的列表转化为id的列表
# self.input_file = open(self.input_file_name, encoding="utf-8") # 与初始化中的重复
sentence = self.input_file.readline()
wordId_list = [] # 一句话中的所有word 对应的 id
sentence = sentence.strip().split(' ')
for i, word in enumerate(sentence):
if i % 1000000 == 0:
print(i, len(sentence))
try: # 如果try中代码出现异常,跳过
word_id = self.word2id_dict[word]
wordId_list.append(word_id)
except:
continue
self.wordId_list = wordId_list # 将词组成的一句话变成由id组成的一句话, 虚线提示可以将word_list在初始化中定义
def get_batch_pairs(self, batch_size, window_size): # 获取正样本
while len(self.word_pairs_queue) < batch_size: # 当队列中数据个数小于batch_size, 向队列添加数据
for _ in range(1000): # TODO:这个循环的意义?
if self.index == len(self.wordId_list): # 如果index等于字典长度,说明遍历完了,index重置为0
self.index = 0
wordId_w = self.wordId_list[self.index] # 获取中心词
for i in range(max(self.index - window_size, 0), # 文章的第一个词没有左边的词,因此从0开始
min(self.index + window_size + 1, len(self.wordId_list))): # 文章最后一个词没有右边的词,因此最大为文章长度
wordId_v = self.wordId_list[i] # 获取周围词
if self.index == i: # 上下文词=中心词 跳过
continue
self.word_pairs_queue.append((wordId_w, wordId_v)) # 加入队列(一个中心词,一个周围词)
self.index += 1
result_pairs = [] # 返回mini-batch大小的正采样对
for _ in range(batch_size):
result_pairs.append(self.word_pairs_queue.popleft()) # 将batch_size个数据(一个中心词,一个周围词)出队列
return result_pairs
def get_negative_sampling(self, positive_pairs, neg_count):
"""
获取负采样 输入正采样对数组 positive_pairs,以及每个正采样对需要的负采样数 neg_count
从采样表抽取负采样词的id(假设数据够大,不考虑负采样=正采样的小概率情况)
:param positive_pairs: 正采样对照组
:param neg_count: 每个正样本需要的负样本数
:return: 负样本列表
"""
neg_v = np.random.choice(self.sample_table, size=(len(positive_pairs), neg_count)).tolist()
return neg_v # 行数为正样本数,列数为负采样个数neg_count
def evaluate_pairs_count(self, window_size): # TODO:哪部分的公式?
# 估计数据中正采样对数,用于设定batch
return self.word_count_sum * (2 * window_size) - self.sentence_count * (
1 + window_size) * window_size
if __name__ == "__main__":
# 测试所有方法
test_data = InputData('../data/text8.txt', min_count=1)
test_data.evaluate_pairs_count(2)
pos_pairs = test_data.get_batch_pairs(10, 2)
print('正采样:')
print(pos_pairs)
pos_word_pairs = []
for pair in pos_pairs:
pos_word_pairs.append((test_data.id2word_dict[pair[0]], test_data.id2word_dict[pair[1]]))
print(pos_word_pairs)
neg_pair = test_data.get_negative_sampling(pos_pairs, 3)
print('负采样:')
print(neg_pair)
neg_word_pair = []
for pair in neg_pair:
neg_word_pair.append(
(test_data.id2word_dict[pair[0]], test_data.id2word_dict[pair[1]], test_data.id2word_dict[pair[2]]))
print(neg_word_pair)
模型构建
import torch
import torch.nn as nn
import torch.nn.functional as F
# skip-gram + 负采样的实现
class SkipGramModel(nn.Module):
def __init__(self,vocab_size,embed_size):
super(SkipGramModel,self).__init__()
self.vocab_size = vocab_size # 词表大小
self.embed_size = embed_size # 词向量维度
self.w_embeddings = nn.Embedding(vocab_size, embed_size) # 初始化中心词向量矩阵
self.v_embeddings = nn.Embedding(vocab_size, embed_size) # 初始化周围词向量矩阵
self._init_emb()
def _init_emb(self):
initrange = 0.5 / self.embed_size
self.w_embeddings.weight.data.uniform_(-initrange, initrange) # 初始化中心词词向量矩阵权重
self.v_embeddings.weight.data.uniform_(-0, 0)
def forward(self, pos_w, pos_v, neg_v):
emb_w = self.w_embeddings(torch.LongTensor(pos_w).cuda()) # 转为tensor 大小 [ mini_batch_size * emb_dimension ]
emb_v = self.v_embeddings(torch.LongTensor(pos_v).cuda())
neg_emb_v = self.v_embeddings(torch.LongTensor(neg_v).cuda()) # 转换后大小[ negative_sampling_number * mini_batch_size * emb_dimension]
score = torch.mul(emb_w, emb_v) # 对应元素相乘
score = torch.sum(score, dim=1) # 在emb_size这个维度求和得到矩阵相乘的效果
score = torch.clamp(score, max=10, min=-10)
score = F.logsigmoid(score)
# 将中心词矩阵增加第2个维度变为 [batch_size * emb_dim * 1] 后与负样本周围词矩阵相乘,结果维度为[batch_size * negative_sampling_number * 1]
neg_score = torch.bmm(neg_emb_v, emb_w.unsqueeze(2))
neg_score = torch.clamp(neg_score, max=10, min=-10)
neg_score = F.logsigmoid(-1 * neg_score)
# L = log sigmoid (Xw.T * θv) + ∑neg(v) [log sigmoid (-Xw.T * θneg(v))]
loss = - torch.sum(score) - torch.sum(neg_score) # 求min
return loss
def save_embedding(self, id2word, file_name):
embedding_1 = self.w_embeddings.weight.data.cpu().numpy() # 保存中心词与周围词向量矩阵
embedding_2 = self.v_embeddings.weight.data.cpu().numpy()
embedding = (embedding_1+embedding_2)/2
fout = open(file_name, 'w')
fout.write('%d %d\n' % (len(id2word), self.embed_size))
for wid, w in id2word.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))
if __name__ == '__main__':
model = SkipGramModel(100, 10)
id2word = dict()
for i in range(100):
id2word[i] = str(i)
pos_w = [0, 0, 1, 1, 1]
pos_v = [1, 2, 0, 2, 3]
neg_v = [[23, 42, 32], [32, 24, 53], [32, 24, 53], [32, 24, 53], [32, 24, 53]]
model.forward(pos_w, pos_v, neg_v)
model.save_embedding(id2word, '../results/test.txt')CBOW+HS代码的实现
数据预处理
import sys
sys.path.append("../CBOW_HS/")
from collections import deque
from huffman_tree import HuffmanTree
class InputData:
def __init__(self, input_file_name, min_count):
self.input_file_name = input_file_name
self.input_file = open(self.input_file_name) # 数据文件
self.index = 0
self.min_count = min_count # 要淘汰的低频数据的频度
self.wordId_frequency_dict = dict() # 词id-出现次数 dict
self.word_count = 0 # 单词数(重复的词只算1个)
self.word_count_sum = 0 # 单词总数 (重复的词 次数也累加)
self.sentence_count = 0 # 句子数
self.id2word_dict = dict() # 词id-词 dict
self.word2id_dict = dict() # 词-词id dict
self._init_dict() # 初始化字典
self.get_wordId_list()
self.huffman_tree = HuffmanTree(self.wordId_frequency_dict) # 霍夫曼树
self.huffman_pos_path, self.huffman_neg_path = self.huffman_tree.get_all_pos_and_neg_path()
self.word_pairs_queue = deque()
# 结果展示
print('Word Count is:', self.word_count)
print('Word Count Sum is', self.word_count_sum)
print('Sentence Count is:', self.sentence_count)
print('Tree Node is:', len(self.huffman_tree.huffman))
def _init_dict(self):
word_freq = dict()
# 统计 word_frequency
for line in self.input_file:
line = line.strip().split(' ') # 去首尾空格
self.word_count_sum += len(line)
self.sentence_count += 1
for word in line:
try:
word_freq[word] += 1
except:
word_freq[word] = 1
word_id = 0
# 初始化 word2id_dict,id2word_dict, wordId_frequency_dict字典
for per_word, per_count in word_freq.items():
if per_count < self.min_count: # 去除低频
self.word_count_sum -= per_count
continue
self.id2word_dict[word_id] = per_word
self.word2id_dict[per_word] = word_id
self.wordId_frequency_dict[word_id] = per_count
word_id += 1
self.word_count = len(self.word2id_dict)
# 获取mini-batch大小的 正采样对 (Xw,w) Xw为上下文id数组,w为目标词id。上下文步长为window_size,即2c = 2*window_size
def get_wordId_list(self):
self.input_file = open(self.input_file_name, encoding="utf-8")
sentence = self.input_file.readline()
wordId_list = [] # 一句中的所有word 对应的 id
sentence = sentence.strip().split(' ')
for i, word in enumerate(sentence):
if i % 1000000 == 0:
print(i, len(sentence))
try:
word_id = self.word2id_dict[word]
wordId_list.append(word_id)
except:
continue
self.wordId_list = wordId_list
def get_batch_pairs(self, batch_size, window_size):
while len(self.word_pairs_queue) < batch_size:
for _ in range(1000):
if self.index == len(self.wordId_list):
self.index = 0
wordId_w = self.wordId_list[self.index]
context_ids = []
for i in range(max(self.index - window_size, 0),
min(self.index + window_size + 1, len(self.wordId_list))):
if self.index == i: # 上下文=中心词 跳过
continue
context_ids.append(self.wordId_list[i])
self.word_pairs_queue.append((context_ids, wordId_w))
self.index += 1
result_pairs = [] # 返回mini-batch大小的正采样对
for _ in range(batch_size):
result_pairs.append(self.word_pairs_queue.popleft())
return result_pairs
def get_pairs(self, pos_pairs):
# 得到正负样本
neg_word_pair = []
pos_word_pair = []
for pair in pos_pairs:
pos_word_pair += zip([pair[0]] * len(self.huffman_pos_path[pair[1]]), self.huffman_pos_path[pair[1]])
neg_word_pair += zip([pair[0]] * len(self.huffman_neg_path[pair[1]]), self.huffman_neg_path[pair[1]])
return pos_word_pair, neg_word_pair
# 估计数据中正采样对数,用于设定batch
def evaluate_pairs_count(self, window_size):
return self.word_count_sum * (2 * window_size - 1) - (self.sentence_count - 1) * (1 + window_size) * window_size
# 测试所有方法
def test():
test_data = InputData('../data/text8.txt', 3)
pos_pairs = test_data.get_batch_pairs(10, 2)
print(pos_pairs)
pos_word_pairs = []
for pair in pos_pairs:
pos_word_pairs.append(([test_data.id2word_dict[i] for i in pair[0]], test_data.id2word_dict[pair[1]]))
print(pos_word_pairs)
print('')
print(test_data.huffman_pos_path[0])
print(test_data.huffman_neg_path[0])
pos, neg = test_data.get_pairs(pos_pairs)
print(pos)
print(neg)
if __name__ == '__main__':
test()模型构建
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.autograd import Variable
class CBOWModel(nn.Module):
def __init__(self, vocab_size, emb_size):
super(CBOWModel, self).__init__()
self.vocab_size = vocab_size
self.emb_size = emb_size
self.u_embeddings = nn.Embedding(2*self.vocab_size-1, self.emb_size, sparse=True)
self.w_embeddings = nn.Embedding(2*self.vocab_size-1, self.emb_size, sparse=True)
self._init_embedding() # 初始化
def _init_embedding(self):
int_range = 0.5 / self.emb_size
self.u_embeddings.weight.data.uniform_(-int_range, int_range)
self.w_embeddings.weight.data.uniform_(-0, 0)
def compute_context_matrix(self, u):
pos_u_emb = [] # 上下文embedding
for per_Xw in u:
# 上下文矩阵的第一维不同词值不同,如第一个词上下文为c,第二个词上下文为c+1,需要统一化
per_u_emb = self.u_embeddings(torch.LongTensor(per_Xw).cuda()) # 对上下文每个词转embedding
per_u_numpy = per_u_emb.data.cpu().numpy() # 转回numpy,好对其求和
per_u_numpy = np.sum(per_u_numpy, axis=0)
per_u_list = per_u_numpy.tolist() # 为上下文词向量Xw的值
pos_u_emb.append(per_u_list) # 放回数组
pos_u_emb = torch.FloatTensor(pos_u_emb).cuda() # 转为tensor 大小 [ mini_batch_size * emb_size ]
return pos_u_emb
def forward(self, pos_u, pos_w, neg_u, neg_w):
"""
:param pos_u: 正样本的周围词,每个样本的周围词是一个list
:param pos_w: 正样本的中心词
:param neg_u: 负样本的周围词,每个样本的周围词是一个list
:param neg_w: 负样本的中心词
:return:
"""
pos_u_emb = self.compute_context_matrix(pos_u) # batch_size * emb_size
pos_w_emb = self.w_embeddings(torch.LongTensor(pos_w).cuda())
neg_u_emb = self.compute_context_matrix(neg_u)
neg_w_emb = self.w_embeddings(torch.LongTensor(neg_w).cuda())
# 计算梯度上升( 结果 *(-1) 即可变为损失函数 ->可使用torch的梯度下降)
score_1 = torch.mul(pos_u_emb, pos_w_emb) # Xw.T * θu
score_2 = torch.sum(score_1, dim=1) # 点积和
score_3 = F.logsigmoid(score_2) # log (1-sigmoid (Xw.T * θw))
neg_score_1 = torch.mul(neg_u_emb, neg_w_emb) # Xw.T * θw
neg_score_2 = torch.sum(neg_score_1, dim=1) # 点积和
neg_score_3 = F.logsigmoid(-neg_score_2) # ∑neg(w) [log sigmoid (-Xw.T * θneg(w))]
# L = log sigmoid (Xw.T * θw) + logsigmoid (-Xw.T * θw)
loss = torch.sum(score_3) + torch.sum(neg_score_3)
return -1 * loss
# 存储embedding
def save_embedding(self, id2word_dict, file_name):
embedding = self.u_embeddings.weight.data.cpu().numpy()
file_output = open(file_name, 'w')
file_output.write('%d %d\n' % (self.vocab_size, self.emb_size))
for id, word in id2word_dict.items():
e = embedding[id]
e = ' '.join(map(lambda x: str(x), e))
file_output.write('%s %s\n' % (word, e))
def test():
model = CBOWModel(100, 10)
id2word = dict()
for i in range(100):
id2word[i] = str(i)
pos_pairs = [([1, 2, 3], 50), ([0, 1, 2, 3], 70)]
neg_pairs = [([1, 2, 3], 50), ([0, 1, 2, 3], 70)]
pos_u = [pair[0] for pair in pos_pairs]
pos_w = [int(pair[1]) for pair in pos_pairs]
neg_u = [pair[0] for pair in neg_pairs]
neg_w = [int(pair[1]) for pair in neg_pairs]
model.forward(pos_u, pos_w, neg_u, neg_w)
model.save_embedding(id2word, 'test.txt')
if __name__ == '__main__':
test()本文为深度之眼paper论文班的学习笔记,仅供自己学习使用,如有问题欢迎讨论!关于课程可以扫描下图二维码


















 5574
5574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









