







单层感知器
属于单层前向网络,及除输入层和输出层外,只拥有一层神经元节点。输入数据从输入层向输出层逐层传播,相邻两层的神经元之间相互连接,同一层神经元之间没有连接。

可以说在隐含层上有两个元件,一个是线性组合器,一个是二值阙值元件。
输入是一个N维向量X=[x1 x2 x3 ,…XN],其中的每一个分量都对应与一个权值wi,隐含层的线性组合器可以得到一个值(标量):
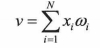
然后在二值阙值元件中得到的V值进行判断,产生二值输出:
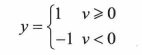
单层感知器的功能就是可以将输入数据分为两类:L1或L2。当y=1时,输入数据为L1,当y=-1,输入数据为L2。
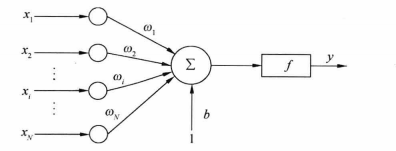
在实际应用中,输入除了有N维向量外,还会有一个外部偏置,值恒为1,权值为b。即1*b;
会输入到线性组合器中,然后在二值阙值元件(使用类似于符号函数)重新判断,式子为:
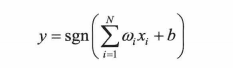
而且可以知道的是上面的式子单独去看是一条直线,斜率为wi;
单层感知器的网路结构发生小小的改变。
以及其二值分类函数
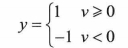
可以从这里看出,判断的临界依据是V=0,那么便能引申出:

这个便是加了偏置后,二值阙值元件的判断依据——模式识别的超平面。
其学习算法过程
从上面的式子中可以知道需要将权值和偏置选择合适,才能将数据完美的分开,但是在实际应用中,是计算机根据训练数据学习来获得正确合适的权值,通常词用纠错学习规则的学习算法。
举例说明:
定义(n+1)*1的输入向量:
x(n)=[1 x1 x2 x3 ......xn]
定义(n+1)*1的权值向量:
W(n)=[b w1 w2 w3 w4....wn] 为什么是(N+1)呢,请看下图
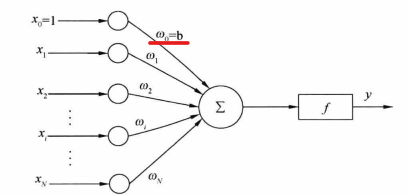
然后就能得到线性组合器的输出值的公式为: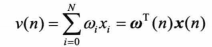
这条式子大多数都是进行矩阵运算,也不需要刻意去使用转置,只要输入分量和权值分量一一对应就行。令该式子为0,便可以得到二分的决策面(区别);
在二值阙值元件中使用的函数是在下文中提及的传递函数Hardlim函数,得到的实际结果便可以与期望结果做比较。
学习算法步骤
①
②
初始化,n=0,将权值向量设置为0,或者是随机值。
③
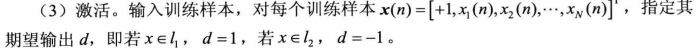
这里的意思是开始进行计算,判断输入的样本是属于哪种类型(L1 L2);
④
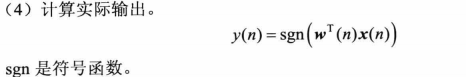
这是第三步的结果。
⑤
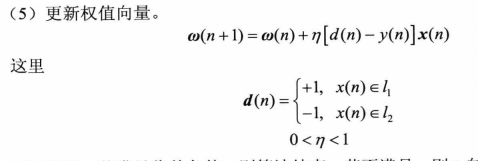
这里的学习速率是一个随机数,具体的内容还没了解;
我觉得这里更新权值可以放在判断是否收敛后再进行。
⑥

继续训练,即继续减少误差。
收敛判断
当权值向量w已经能正确实现分类时,算法就收敛了,此时网络误差为0,字计算时,收敛的条件可以是:
1,误差小于某个预先设定的较小的值,高数里面的收敛的定义;
2,两次迭代之间的权值变化已经很小;
3,设定最大的迭代次数M,迭代M次后算法就停止迭代。

感知器的缺陷

相关函数详解
创建一个感知器
%P是一个R*2矩阵,矩阵的行数R等于感知器网络中输入向量的维数,即输入个数。矩阵的每一行则表示输入向量的取值范围
%net=perceptron(P,T,TF,LF); T表示输出节点的个数 TF是指传递函数,LF是指学习函数。
p=[-1 , 1;-1 ,1];
t=1;
net=newp(p,t,'hardlim','learnp'); %这里完成创建,接下来是训练;
%用于训练的数据样本:每列是一组输入向量
P=[0 0 1 1;
0 2 0 1];
T=[0 1 1 1 ];%输入数据的期望输出
net=train(net,P,T); %训练完后就是测试数据
A=[0 ,0.8]';
A1=sim(net,A)
会得到:

可见创建的感知器网络有两个输入节点,一个输出节点。
训练感知器网络——train
[net, tr]=train(net,P,T,PI,AI]
其中
net是需要训练的网络。
P是R*Q个输入矩阵,每一列是一组输入向量,Q是指需要训练的组数。
T是指网络的期望输出,这个参数是可选的,对于无监督学习,不需要期望输出:T=S*Q,T是指输出节点,Q是指输出的次数。
Pi是指输入延迟,默认为0;
Ai是隐含层和输出层延时,默认为0;
tr是指训练记录,包括训练的的步数和性能
使用感知网络的一个典型流程就是使用newp创建一个感知器网络net,然后用train函数根据训练数据对net进行训练,最后用sim进行仿真
实例
创建一个感知器,用来判断输入数字的符号,非负输出为1,负数输出为0;
p=[-100 100];%输入数据是标量,取值范围是-100 100
t=1;%输出节点设为1;
net=newp(p,t);%创建一个感知器网络;
P=[-5 -4 -3 -2 -1 0 1 2 3 4 5];%输入训练数据;
T=[0 0 0 0 0 1 1 1 1 1 1 ];%输入网络期望输出
net=train(net,P,T);%训练感知器网络;
A=10;
A1=sim(net,A)
B=-10;
A2=sim(net,B)
C=30;
A3=sim(net,C)
感知器的传输函数——hardlim和hardlims

A=hardlim(N,FP);

init——神经网络初始化
net=init(net);

上面的功能是为了初始化神经网络net的权值和阈值,那么我们就来看看创建中的权值:

隐含层只有一个神经元,所以输出为:

然后接着是训练后,感知器网络的权值,看看是否发生了变化:

可以看见再训练后,权值发生了改变。而且训练完成后,权值就不会再改变。
对于偏置权值也是一样的代理,调用的函数是:
net.b{1}:%是指第一个隐含层的偏置。
然后我们对感知网络进行初始化,是权值和偏置都恢复为0;
adapt——神经网络的自适应

沿用之前的训练样本,发现其误差为0;

在使用train函数训练过后,网络误差为0;
但是在使用train函数训练之前,情况是这样的:
P=[-5 -4 -3 -2 -1 0 1 2 3 4 5];%输入训练数据;
T=[0 0 0 0 0 1 1 1 1 1 1 ];%输入网络期望输出
[net,y,ee,pf]=adapt(net,P,T);
ma=mae(ee)
B1=sim(net,-20);%没有进行训练,直接仿真
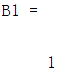
而且会发现,无论仿真的时候输入任何数,得到的结果都是1;然后我们现在就可以发现在输入为负数的情况下,输出不是为0,而是为1.误差为-1;在这里插入代码片

接下来便是使用对感知器网络进行调整;
[net,y,ee,pf]=adapt(net,P,T);
ma=mae(ee);
ite=0;
while ma>0.1
[net,y,ee,pf]=adapt(net,P,T,pf);
ma=mae(ee);
B=sim(net,P);
ite=ite+1;
if ite>=10
break;
end
end
可以得到:依然存在误差,但是结果已经十分接近期望值;(是不是就是说与train函数是一样的意思

于是我就改了一下代码:
while ma>0
[net,y,ee,pf]=adapt(net,P,T,pf);
ma=mae(ee);
B=sim(net,P);
ite=ite+1;
if ite>=10
break;
end
end
可以知道的是,adapt函数与train函数是一样的。
mae——平均绝对误差性能函数
perf=mae(e); e为误差向量构成的矩阵或细胞数组
还有一个点需要注意的是:绝对值计算
平均绝对误差:
mae=|e|\N;
均方误差:
mse=(e^2)\n
误差平方和:
sse=e^2;
实例
最后用一个实例来加深对单层感知器的理解,首先我们知道的是该网络最大的功能就是二分类;

这幅图中给出几个点,我们设计一个单层感知器来将他分成两类点;
分类如下:

这是一个线性可分问题,输入向量为2维向量(X,Y);在二维空间中们可以用一条直线将其正确的分开;

同时也知道输入向量维数为2维,输出维数为去,因此创建的感知器网络的结构如下图:

现在我们知道的量有输入向量,输出量,所以我们可以得到:
根据前面出现的定义与公式:

把偏置也作为输入向量,b变量乘以1。
n=0.2; %学习率
w=[0,0,0]; %权值和偏置初始化 [b, w11, w12]
P=[-9 1 -12 -4 0 5;
15 -8 4 5 11 9];
d=[0 1 0 0 0 1]; %期望输出
p=[ones(1,6);P];
max=20; %训练次数最大为20次;
%训练
i=0;
while 1
v=w*p; %线性组合器
y=hardlim(v); %计算实际输出
e=(d-y); %计算误差
ee(i+1)=mae(e) %计算绝对值误差
if(ee(i+1)<0.001)
x=ee(i+1) %最后的绝对值误差
y=i+1 %迭代计算的次数
break;
end
%更新权值和偏置
w=w+n*(d-y)*p';
i=i+1; %进行下次计算
if(i>=max)
break;
end
end
w1=w(1) %训练后的偏置
w2=w(2) %训练后的权值1
w3=w(3) %训练的权值2
%显示
figure;
subplot(2,1,1);
plot([-9 -12 -4 0],[15 4 5 11],'o');
hold on ;
plot([1,5],[-8,9],'*');
axis([-13 6 -10 16]);
legend('第一类','第二类');
x=-13:2:6;
%wi*xi+b=0;
y=x*(-w(2)/w(3))-w(1)/w(3); %计算并显示二分类的线 这里输入的是训练后的权值和偏置
plot(x,y);
hold off;
在训练后可以得到以下结果:


我们也可以用
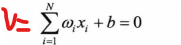
这条式子来验证以下上面的权值是否正确:
找出线上任意一点:(1,1.914)和权值(b=-0.4 w1=7 w2=-3.4) 得到的结果近似于0,这样我们可以更加来了解这个单层感知器。















 6386
6386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









