






文章目录
前言
AI模型在落地部署到应用的过程中,面临着低延迟(Latency)、高吞吐(Throughpout)、高效率(Efficiency)挑战的。模型压缩算法可以将一个庞大而复杂的模型转化为一个精简的小模型,从而减少对硬件的存储、带宽和计算需求,以达到加速模型推理和落地的目的。近年来主流的模型压缩方法包括:数值量化(Data Quantization,也叫模型量化),模型稀疏化(Model sparsification,也叫模型剪枝 Model Pruning),知识蒸馏(Knowledge Distillation), 轻量化网络设计(Lightweight Network Design)和 张量分解(Tensor Decomposition)。
模型剪枝旨在通过减少神经网络中不必要的参数和连接,来优化模型的效率和性能。剪枝可以很好地衡量模型轻量化程度与精度的关系,是替换轻量化结构完全没办法比的,大部分轻量化模块都是由时间换空间,而且精度还会下降得比较多,但是剪枝可以很好地避免这个问题。
一、结构化剪枝
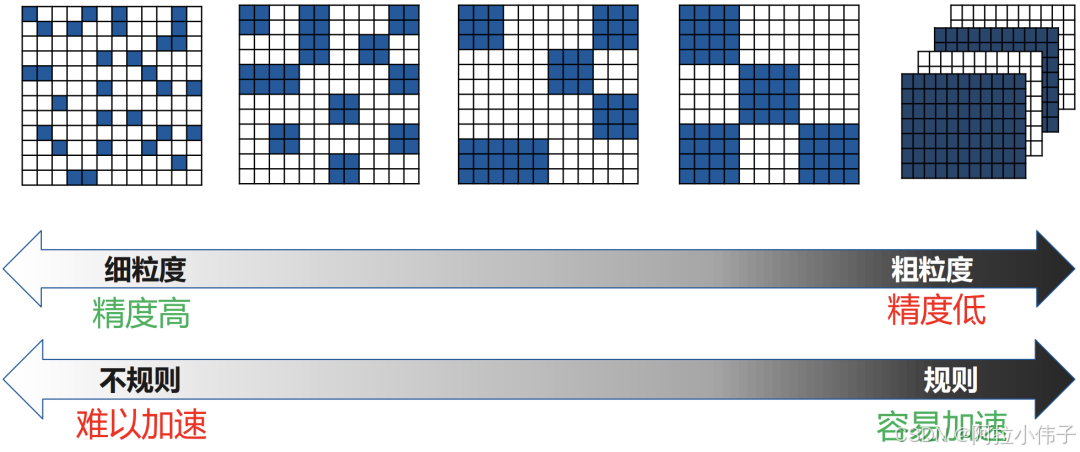
早期提出的连接权重稀疏化方法是非结构化稀疏(即细粒度稀疏,也叫非结构化剪枝),其直接将模型大小压缩10倍以上,理论上也可以减少10倍的计算量。但是,细粒度的剪枝带来的计算特征上的“不规则”,对计算设备中的数据访问和大规模并行计算非常不友好。
“结构化剪枝”的基本修剪单元是卷积核或权重矩阵的一个或多个Channel。由于结构化剪枝没有改变权重矩阵本身的稀疏程度,现有的计算平台和框架都可以实现很好的支持。这种引入了“规则”的结构化约束的稀疏模式通常被称为结构化稀疏(Structured Sparsity),在很多文献中也被称之为粗粒度稀疏(Coarse-grained Sparsity)或块稀疏(Block Sparsity),结构化和非结构化稀疏针对的都是权重参数。
结构化剪枝又可进一步细分:可以是 channel/filter-wise,也可以是 shape-wise 等。
1.Channel/Filter 剪枝
channel 剪枝的工作是最多的,filter (channel) pruning (FP) 属于粗粒度剪枝(或者叫结构化剪枝 Structured Pruning),基于 FP 的方法修剪的是过滤器或者卷积层中的通道,而不是对个别权重,其原始的卷积结构不改变,利于加速。
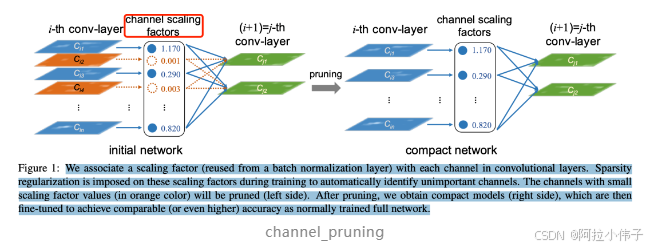
BN会按通道对输入特征进行归一化,使得不同的特征处于比较接近的范围内。论文Learning Efficient Convolutional Networks through Network Slimming 认为 conv-layer 的每个channel 的重要程度可以和 bn 层关联起来,如果某个 channel 后的 bn 层中对应的 scaling factor 足够小,就说明该 channel 的重要程度低,可以被忽略。如下图中橙色的两个通道被剪枝。
BN 层的计算公式如下:
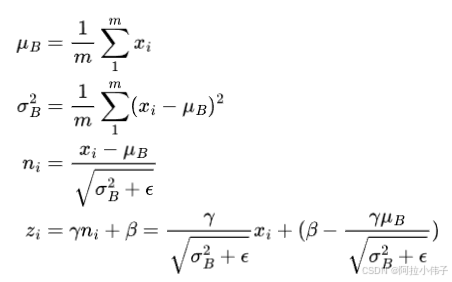
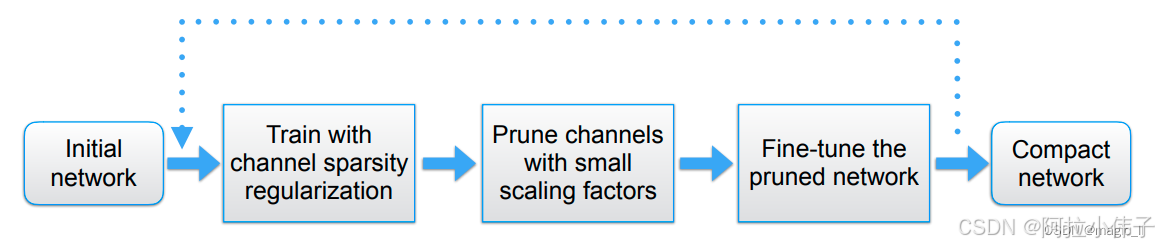
其中,bn 层中的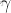 参数被作为 channel-level 剪枝 所需的缩放因子(scaling factor)。在slimming论文中,作者对scale参数施加了一个额外的L1正则化项来稀疏化一部分通道。整个流程如下所示:稀疏训练–>剪枝–>微调
参数被作为 channel-level 剪枝 所需的缩放因子(scaling factor)。在slimming论文中,作者对scale参数施加了一个额外的L1正则化项来稀疏化一部分通道。整个流程如下所示:稀疏训练–>剪枝–>微调
2.阶段级别剪枝
一个阶段中的残差结构块是紧密联系在一起的,如下图所示。

当一个阶段的输出特征发生变化时(一些特征被抛弃),其对应的每个残差结构的输入特征和输出特征都要发生相应的变化,所以整个阶段中,每个残差结构的第一个卷积层的输入通道数,以及最后一个卷积层的输出通道数都要发生相同的变化。由于这样的影响只限定在当前的阶段,不会影响之前和之后的阶段,因此我们称这个剪枝过程为阶段级别的剪枝(stage-level pruning)。
3.结构化剪枝与非结构化剪枝比较
1、非结构化稀疏具有更高的模型压缩率和准确性,在通用硬件上的加速效果不好。因为其计算特征上的“不规则”,导致需要特定硬件支持才能实现加速效果。
2、结构化稀疏虽然牺牲了模型压缩率或准确率,但在通用硬件上的加速效果好,所以其被广泛应用。因为结构化稀疏使得权值矩阵更规则更加结构化,更利于硬件加速。
二、Yolov8 剪枝实战
1.约束训练(constrained training)
在BN层添加L1正则化,具体步骤:在./ultralytics/engine/trainer.py中添加以下内容:
# Backward
self.scaler.scale(self.loss).backward()
# prune_step1 start
# 对BN层进行L1正则化,约束训练时启用,正常训练时注释掉
l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)
for k, m in self.model.named_modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data))
m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data))
# prune_step1 end
# Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= self.accumulate:
self.optimizer_step()
last_opt_step = ni
启动训练务必设置amp=False,关闭混合精度训练,否则无法得到结果
2.剪枝(prune)
对上一步约束训练得到的模型t进行剪枝处理。在/yolov8/下新建文件prune_yolov8.py,具体内容如下:
import sys
import torch
from ultralytics import YOLO
from ultralytics.nn.modules import Bottleneck, Conv, C2f, SPPF, Detect
# 加载约束训练后的模型
yolo = YOLO("constrained_mode.pt")
model = yolo.model
# 遍历模型的所有层,如果某一层是 torch.nn.BatchNorm2d 类型,则提取其权重和偏置的绝对值,分别存入 ws 和 bs 列表,并打印出最大值和最小值
# 剪枝后,确保BN层的大部分bias足够小(接近于0),否则重新进行稀疏训练
ws = []
bs = []
RED = "\033[91m"
RESET = "\033[0m"
for name, m in model.named_modules():
if isinstance(m, torch.nn.BatchNorm2d):
w = m.weight.abs().detach()
b = m.bias.abs().detach()
ws.append(w)
bs.append(b)
print('bn name: {}, weight max: {:.10f}, weight min: {}{:.10f}{}, bias max: {:.10f}, bias min: {}{:.10f}{}'.format(
name, w.max().item(), RED, w.min().item(), RESET, b.max().item(), RED, b.min().item(), RESET))
# 将所有收集到的权重拼接成一个张量,并通过排序选择位于 factor(这里是0.8)位置的权重作为剪枝的阈值。这意味着保留权重值最大的80%
# 具体,对 ws 张量进行降序排序,并返回排序后的值和排序的索引,[0] 选择了排序后的值,从排序后的值中选择一个值作为阈值
factor = 0.8 # 保持率 0.8
ws = torch.cat(ws)
threshold = torch.sort(ws, descending=True)[0][int(len(ws) * factor)]
print('threshold: {:.10f}'.format(threshold))
# conv1的输出作为conv2的输入
# 对conv1的输出通道进行剪枝(在滤波器的维度进行剪枝),
# 同时conv2的输入通道要相应的剪枝(在卷积核的通道维度进行剪枝)
def prune_conv(conv1: Conv, conv2: Conv):
gamma = conv1.bn.weight.data.detach()
beta = conv1.bn.bias.data.detach()
keep_idxs = []
local_threshold = threshold
# 逐步降低阈值来确保在剪枝过程中至少保留 8 个通道(如果小于8 Nvidia GPU 会导致利用率很低,影响性能)
# 防止过度剪枝:如果直接使用初始阈值,可能会导致保留的通道数太少,这可能严重影响模型的能力,导致性能下降
# 因此,逐步降低阈值可以保证在剪枝过程中至少保留一定数量的通道,从而在减少计算量的同时,尽量维持模型的表达能力
# 设定通道数下限:设定一个保底的通道数(比如8个)确保模型不会因为剪枝导致过度简化,从而仍然能够保留一些重要的特征
while len(keep_idxs) < 8:
# 取按照阈值过滤得到要保留的通道索引
keep_idxs = torch.where(gamma.abs() >= local_threshold)[0]
local_threshold = local_threshold * 0.5
n = len(keep_idxs)
print(n / len(gamma) * 100) # 输出保留通道相对于原始通道数的百分比
# 根据保留的通道索引 keep_idxs 更新,只保留剪枝后的通道
conv1.bn.weight.data = gamma[keep_idxs] # 更新 BN 层的权重
conv1.bn.bias.data = beta[keep_idxs] # 更新 BN 层的偏置
conv1.bn.running_var.data = conv1.bn.running_var.data[keep_idxs] # 更新 BN 层的方差估计值
conv1.bn.running_mean.data = conv1.bn.running_mean.data[keep_idxs] # 更新 BN 层的均值估计值
conv1.bn.num_features = n # 更新 BN 层的通道数
conv1.conv.weight.data = conv1.conv.weight.data[keep_idxs] # 更新卷积层的权重
conv1.conv.out_channels = n # 更新卷积层的输出通道数
if conv1.conv.bias is not None: # 如果存在,更新卷积层的偏置
conv1.conv.bias.data = conv1.conv.bias.data[keep_idxs]
# 更新与conv1层连接的后续卷积层conv2的 in_channels 和相应的权重,
# 使得模型的各层结构保持一致,避免因为剪枝导致通道数不匹配的问题
if not isinstance(conv2, list):
conv2 = [conv2]
for item in conv2:
if item is not None:
if isinstance(item, Conv):
conv = item.conv
else:
conv = item
# 将卷积层 conv 的输入通道数更新为 n,即之前在 conv1 剪枝后保留的通道数
# 这是因为 conv2 的输入来自于 conv1 的输出,而 conv1 的输出通道数已经被剪枝,
# 因此需要同步更新 conv2 的输入通道数
conv.in_channels = n
conv.weight.data = conv.weight.data[:, keep_idxs] # 同步更新对应的保留通道,注意是在输入通道维度(卷积核的通道维度)进行剪枝
def prune(m1, m2):
if isinstance(m1, C2f): # C2f as a top conv
m1 = m1.cv2
if not isinstance(m2, list): # m2 is just one module
m2 = [m2]
for i, item in enumerate(m2):
if isinstance(item, C2f) or isinstance(item, SPPF):
m2[i] = item.cv1
prune_conv(m1, m2)
### 1. 剪枝c2f 中的Bottleneck
for name, m in model.named_modules():
if isinstance(m, Bottleneck):
prune_conv(m.cv1, m.cv2)
### 2. 指定剪枝不同模块之间的卷积核
seq = model.model
for i in range(3, 9):
if i in [6, 4, 9]: continue
prune(seq[i], seq[i+1])
### 3. 对检测头进行剪枝
detect:Detect = seq[-1]
last_inputs = [seq[15], seq[18], seq[21]]
colasts = [seq[16], seq[19], None]
for last_input, colast, cv2, cv3 in zip(last_inputs, colasts, detect.cv2, detect.cv3):
prune(last_input, [colast, cv2[0], cv3[0]])
prune(cv2[0], cv2[1])
prune(cv2[1], cv2[2])
prune(cv3[0], cv3[1])
prune(cv3[1], cv3[2])
# ***step4,一定要设置所有参数为需要训练。因为加载后的model他会给弄成false。导致报错
# pipeline:
# 1. 为模型的BN增加L1约束,lambda用1e-2左右
# 2. 剪枝模型,比如用全局阈值
# 3. finetune,一定要注意,此时需要去掉L1约束。最终final的版本一定是去掉的
for name, p in yolo.model.named_parameters():
p.requires_grad = True
torch.save(yolo.ckpt, "prune.pt")
yolo.export(format="onnx", simplify=True)
print("done")
剪枝后的模型转onnx之后可以看到onnx文件的大小比剪枝前变小了。
3.回调训练(finetune)
首先,将先前在./ultralytics/engine/trainer.py中添加的L1正则化部分注释掉,
# Backward
self.scaler.scale(self.loss).backward()
# prune_step1 start
# 对BN层进行L1正则化,约束训练时启用,正常训练时注释掉
# l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)
# for k, m in self.model.named_modules():
# if isinstance(m, nn.BatchNorm2d):
# m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data))
# m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data))
# prune_step1 end
# Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= self.accumulate:
self.optimizer_step()
last_opt_step = ni
加载剪枝后的模型作为训练时的网络结构。在 ultralytics/yolo/engine/model.py 中修改内容:656行左右的 self.trainer.model 是从yaml中加载的模型( 未剪枝前的) 和其它的配置信息,以及从pt文件中加载的权重( 剪枝后的)。所以只需将该变量中的网络结构更新为剪枝后的网络结构即可,增加代码可解决问题。
否则训练出来的模型参数不会发生变化。
self.trainer.model.model = self.model.model
self.trainer = (trainer or self._smart_load("trainer"))(overrides=args, _callbacks=self.callbacks)
if not args.get("resume"): # manually set model only if not resuming
self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)
self.trainer.model.model = self.model.model # 新增 prune need
self.model = self.trainer.model
启动回调训练。
三、总结
本实战主要用的是L1正则化方法做的剪枝,其他方法还包括:L2、Random、GroupSlim、GroupNorm、LAMP、GroupSL、GroupReg、GroupHessian、GroupTaylor等。剪枝后模型精度不佳还可以用剪枝前后的模型做知识蒸馏的尝试。
深度神经网络的权值稀疏应该在模型有效性和计算高效性之间做权衡。
学习路漫漫。。。

















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









