







文章目录
前言
在上期博客中,我们实现了对YOLOv10模型的结构化通道剪枝,本篇文章将介绍如何对增加了MCA注意力机制的YOLOv8模型进行通道剪枝,并详细解读每个参数和模块的作用。
上期博客地址:YOLOv10结构化通道剪枝【附代码】
视频效果
魔改YOLOv8 在参数量下降51.3%的情况下涨点1%【附代码】
文章概述
本篇博客将详细介绍如何对yolov8注意力机制模型进行通道剪枝,具体步骤包括参数解析、剪枝代码讲解、fine-tune训练,最后将对比剪枝前后模型在KITTI数据集上的表现,包括MAP、参数量和FPS等指标,以验证剪枝效果
必要环境
-
配置yolov10环境 可参考往期博客(v8和v10环境配置方法可通用)
地址:搭建YOLOv10环境 训练+推理+模型评估
-
安装torch-pruning 0.2.7版本,安装命令如下
pip install torch-pruning==0.2.7 -
MCA注意力机制论文地址
地址:Multidimensional collaborative attention in deep convolutional neural networks for image recognition
一、训练自己的模型
1、 训练命令
python 1_yolov8_train.py --mode train_ch --yaml_path yolov8n.yaml --epoch 200 --batch 32 --model_path ''
运行效果:
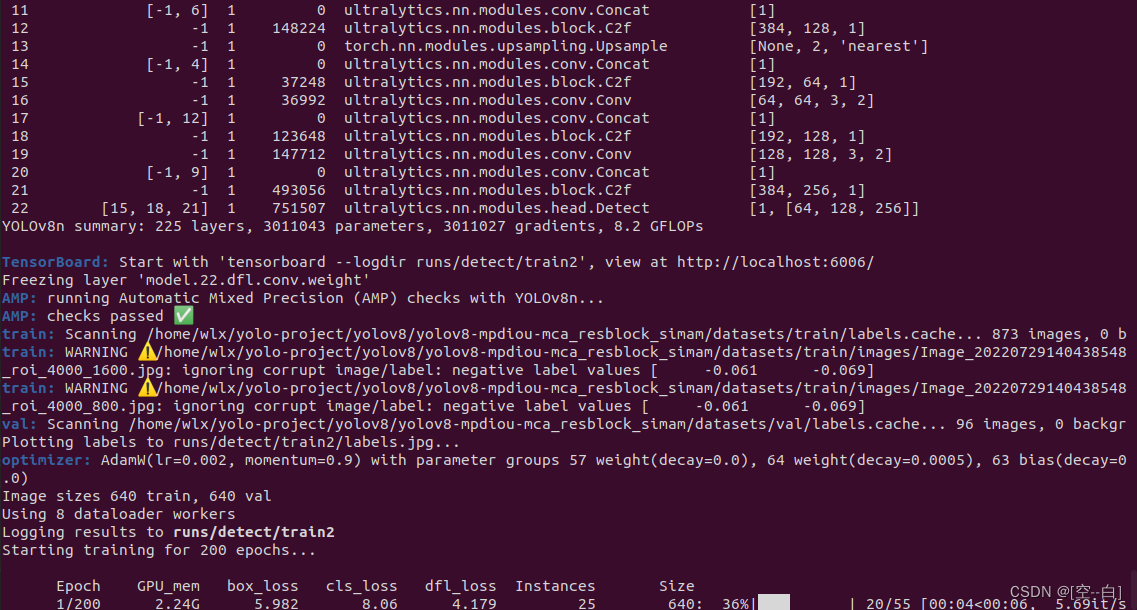
可以看到正常训练时会打印模型在yaml文件中定义的网络结构
2、 训练参数解析
# 解析命令行参数
parser = argparse.ArgumentParser(description='Train or validate YOLO model.')
parser.add_argument('--mode', type=str, default='val', choices=['train_ori', 'train_ch', 'val'],
help='Mode of operation.')
parser.add_argument('--yaml_path', type=str, default='yolov8n.yaml', help='Path to YAML file.')
parser.add_argument('--model_path', type=str, default=r'runs/kitti_ori/weights/best.pt', help='Path to model file.')
parser.add_argument('--data_path', type=str, default='./data.yaml', help='Path to data file.')
parser.add_argument('--epoch', type=int, default=200, help='Number of epochs.')
parser.add_argument('--batch', type=int, default=16, help='Batch size.')
parser.add_argument('--workers', type=int, default=8, help='Number of workers.')
parser.add_argument('--device', type=str, default='0', help='Device to use.')
parser.add_argument('--name', type=str, default='', help='Name data file.')
args = parser.parse_args()
参数详解:
-
–mode: 用于指定操作模式
可选值为train_ori、train_ch和val。train_ori用于训练原始模型,train_ch用于训练改进后的模型(如增加注意力机制或增加检测头),val用于验证模型并计算精度指标 -
–yaml_path: 指定改进网络结构的YAML文件路径
当选择训练改进后的模型时,需要提供相应的网络结构文件路径,如训练带有MCA注意力机制的模型时,此处填写相应的YAML文件路径 -
–model_path: 指定模型文件路径
当mode不等于val时,该参数为预训练模型的路径(如训练8n模型时,此处填写yolov8n.pt路径)
当mode等于val时,该参数为训练好的模型路径,用于计算指标,通常保存在runs目录下 -
–data_path: 指定数据集文件路径
该参数用于提供数据集的路径,对应一个YAML文件 -
–epoch: 指定训练的轮数
默认值为200,表示模型的训练轮次 -
–batch: 指定批次大小
默认值为16,表示每次训练迭代中所处理的样本数量 -
–workers: 指定工作线程数
默认值为8,表示用于数据加载的工作线程数量,windows系统这里改为0 -
–device: 指定使用的设备
默认值为0,表示使用的GPU设备编号 -
–name: 指定保存模型文件夹的名称
二、模型剪枝
1、 对训练好的模型将进行剪枝
运行命令如下
python 3_yolov8_pruning.py --model_path weights/kitti_baseline/weights/best.pt --prune_type l1 --prune_ratio 0.4
运行效果:
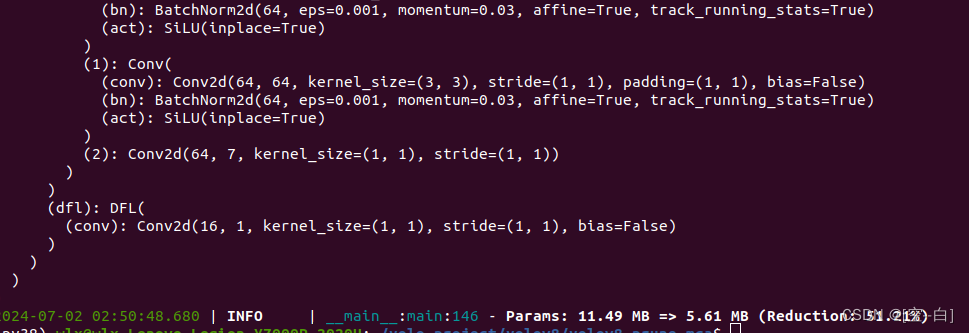
运行成功后会输出剪枝后的网络结构,以及剪枝前后模型的参数量对比
2、 剪枝代码详解
1.解析命令行参数
解析命令行参数的,其方便各位在命令行中指定模型路径、剪枝策略以及剪枝比例等参数
# 解析命令行参数
def parse_args():
parser = argparse.ArgumentParser(description="Prune YOLOv8 model.")
parser.add_argument("--model_path", type=str,
default=r"weights/kitti_baseline/weights/best.pt",
help="Path to the YOLOv8 model.")
parser.add_argument("--prune_type", type=str, default="l2", choices=["l1", "l2", "random"],
help="Pruning strategy to use.")
parser.add_argument("--prune_ratio", type=float, default=0.4, help="Pruning ratio.")
args = parser.parse_args()
return args
参数详解:
- –model_path: 指定需要剪枝的模型路径
- –prune_type: 指定剪枝策略,可选方案为 l1, l2, random,默认使用 l1策略
- –prune_ratio: 指定剪枝比例,默认值为0.4,表示对定义的卷积层减掉40%的通道数
2. 定义剪枝函数
用于根据指定的修剪策略和比例对给定的模型进行修剪
def prune_model(model, prune_type, prune_ratio, input_tensor):
strategy = {
'l1': tp.strategy.L1Strategy(),
'l2': tp.strategy.L2Strategy(),
'random': tp.strategy.RandomStrategy()
}.get(prune_type, tp.strategy.RandomStrategy())
dependency_graph = tp.DependencyGraph().build_dependency(model, example_inputs=input_tensor)
included_layers = get_included_layers(model)
original_params = tp.utils.count_params(model)
pruning_plans = [
dependency_graph.get_pruning_plan(m, tp.prune_conv, idxs=strategy(m.weight, amount=prune_ratio))
for m in model.modules() if isinstance(m, nn.Conv2d) and m in included_layers
]
关键步骤详解:
-
策略选择
根据 prune_type 参数, 选择对应的剪枝策略,如果 prune_type 不是预定义的值, 则默认使用随机剪枝策略 -
构建依赖图
使用 tp.DependencyGraph().build_dependency 函数构建模型的依赖关系图, 以便后续进行剪枝操作 -
获取包含的层
使用 get_included_layers 函数获取需要进行剪枝的层, 即模型中的 nn.Conv2d 层 -
计算原始参数数量
使用 tp.utils.count_params 函数计算模型的原始参数数量 -
制定剪枝计划
对于每个需要剪枝的 nn.Conv2d 层, 使用对应的剪枝策略计算剪枝的索引, 并生成剪枝计划
3. 定义剪枝结构
从指定模型中, 找出所有可以进行剪枝操作的层, 并将它们添加到 included_layers 列表中
def get_included_layers(model):
included_layers = []
for layer in model.model:
if isinstance(layer, Conv):
included_layers.append(layer.conv)
...
if isinstance(layer, Detect):
...
return included_layers
关键模块详解:
- model: 指定yolov8模型,函数将遍历这个模型的层来识别可剪枝的部分
- included_layers: 用于存储可以进行剪枝操作的层,函数会将这些层添加到这个列表中
- 定义模型中不同类型的层,函数会根据层的类型采取不同的处理方式,将可剪枝的部分添加到 included_layers 列表中
4. 更新注意力机制
由于torch_pruning中的某些bug,剪枝后会使注意力机制中某些模块的通道数变为负数,为了确保剪枝后的网络能够正确工作,我们需要更新这些层的通道数
def replace_conv_macayer(original_layer, new_in_channels, new_out_channels):
# 获取原始层的参数
original_weight = original_layer.conv.weight.data
original_bias = original_layer.conv.bias.data if original_layer.conv.bias is not None else None
# 创建一个新的卷积层
new_conv_layer = nn.Conv2d(in_channels=new_in_channels, out_channels=new_out_channels,
kernel_size=original_layer...)
# 复制权重
...
return new_conv_layer
关键模块详解:
- original_layer: 原始的卷积层。这是一个包含卷积层的对象,通常是一个网络中的某个层。
- new_in_channels: 新的输入通道数。
- new_out_channels: 新的输出通道数。
- 返回值:最终会返回一个新的卷积层,该层具有更新后的输入和输出通道数,并且尽可能保留了原始层的权重和偏置。
5. 保存更新后的模型
**剪枝操作完成后,我们需要将剪枝后的模型保存,以便后续使用 **
# 保存更新后的模型
def save_pruned_model(model, ckpt, prune_type):
param_dict = {
'model': model,
'ema': ckpt['ema'],
...
}
torch.save(param_dict, f'prune_model_{prune_type}.pt')
参数详解:
- model:剪枝后的模型**
- ckpt:模型训练状态和相关参数的字典,需要将必要部分写入到剪枝模型中**
- prune_type:剪枝类型,用于命名保存的模型文件**
6. 主函数
定义主函数,整合上述各个步骤,实现完整的剪枝流程
def main():
args = parse_args()
# 加载模型
yolov8 = YOLO(args.model_path)
# 使模型参数可训练
for para in model.parameters():
para.requires_grad = True
pruned_model, original_params = prune_model(model, args.prune_type, args.prune_ratio, input_tensor)
# 更新模型中的注意力层
update_model_attention_layers(pruned_model)
# 保存更新后的模型
save_pruned_model(pruned_model, ckpt, args.prune_type)
pruned_params = tp.utils.count_params(model)
percentage_reduction = ((original_params - pruned_params) / original_params) * 100
logger.info(
f"Params: {original_params * 4 / 1024 / 1024:.2f} MB => {pruned_params * 4 / 1024 / 1024:.2f} MB (Reduction: {percentage_reduction:.2f}%)")
关键模块解读:
1. parse_args():解析命令行参数。
2. YOLO(args.model_path):加载YOLOv8模型
3. prune_model():执行剪枝操作
4. save_pruned_model():保存剪枝后的模型
5. 计算剪枝前后参数的变化,并打印模型信息和参数减少的百分比
三、剪枝后的训练
运行命令如下
python 4_yolov8-finetune.py --finetune --epochs 200 --batch_size 16
运行效果:
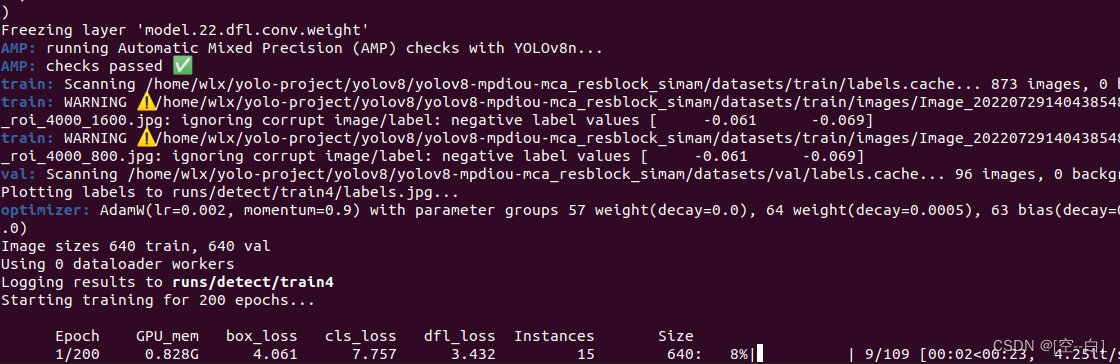
可以看到剪枝后训练不会打印模型在yaml文件中定义的网络结构
四、实验指标对比
如下表:
| 模型 | MAP | P | R | Imgsz | Param |
|---|---|---|---|---|---|
| YOLOv8n原模型 | 86.7 | 96.8 | 74.8 | 640 | 11.47 |
| YOLOv8n+MCA | 88.4 | 95.7 | 78.5 | 640 | 11.47 |
| YOLOv8n+MCA+剪枝 | 87.7 | 97.2 | 76.5 | 640 | 5.59 |
- 由此可见在KITTI验证集上,MCA注意力机制+剪枝可以做到在参数量下降51%的情况下涨点1%
- 验证集是通过留出法将训练集按9:1比例进行划分所得
五、剪枝前后效果对比
剪枝前:

剪枝后:
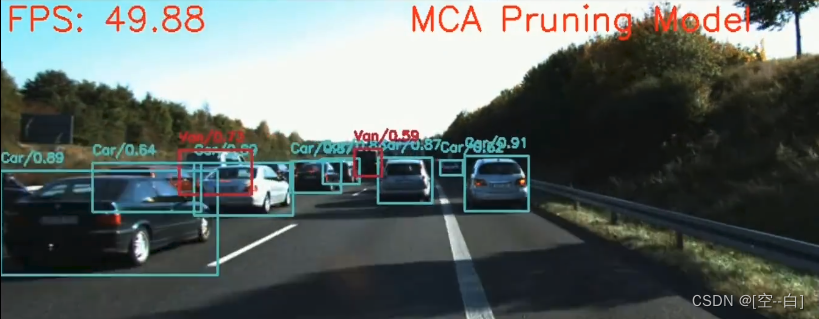
实验设备为RTX2060,如上图所示 剪枝后的模型FPS更高,推理速度更快
总结
本期博客就到这里啦,喜欢的小伙伴们可以点点关注,感谢!
最近经常在b站上更新一些有关目标检测的视频,大家感兴趣可以来看看 https://b23.tv/1upjbcG
学习交流群:995760755


















 2841
2841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











