






接上一篇
P12-P13
BEiT
n
在
BE
i
T
的论文中,作者
提出了一种名为遮盖图像建模(
MIM
)的预训练任务
:
图
像
有 2
两
种表示的形式:image patches
和
visual tokens
。
n
在预训练的过程中,它们分别被作为模型的输入和输出
。
n
BEIT
的结构包含
2
部分,分别是:
BEIT Encoder
和
dVAE
:
n
BEIT Encoder
类似于
Transformer Encoder
,是对输入的
image patches
进行编码的过程;
n
dVAE
类似于
VAE
,也是对输入的
image patches
进行编码的过程。
n
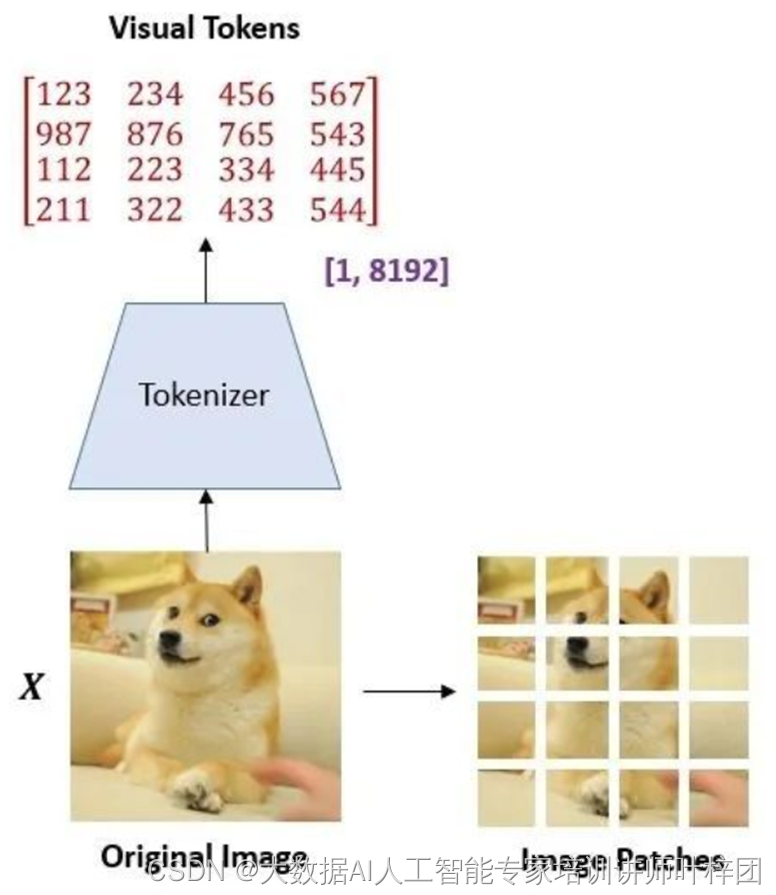
每个visual token是一个介于1~8192之间的数
VAE
n
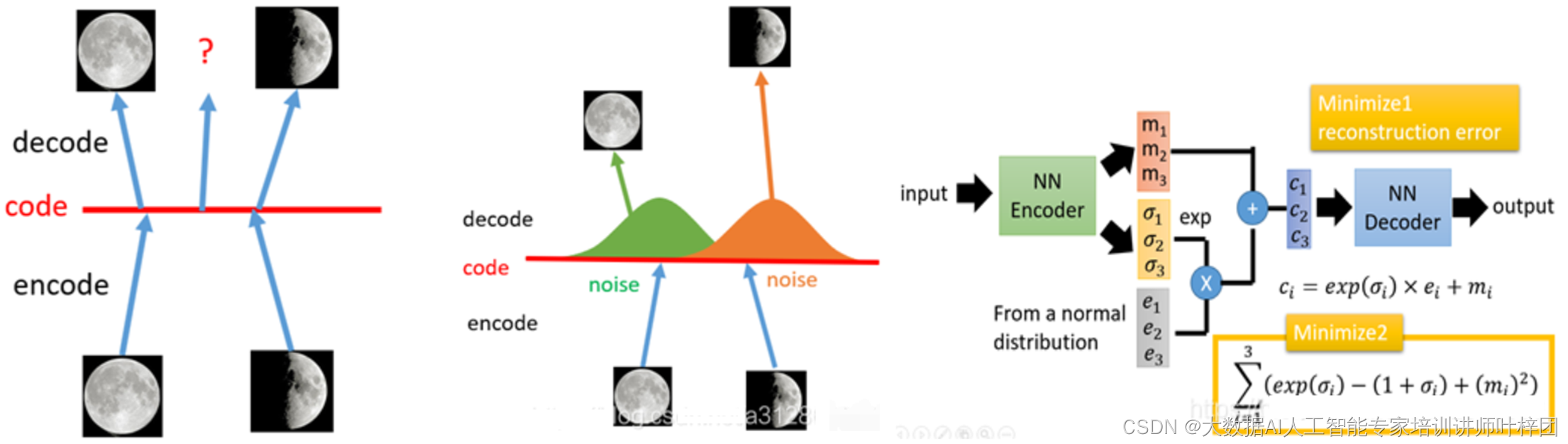
在
code
空间的两张图片的编码中间处取一点,然后将这一点交给解码器,希望新的生成图片是一张清晰的图片,但实际的结果是生成图片是模糊且无法辨认的乱码图。
n
给编码器增添一些噪音,可以有效覆盖失真区域。
















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











