







在多媒体内容创作领域,文本到音频的生成技术正变得越来越重要。随着AI技术的发展,我们有能力快速生成接近人类创作水平的音频内容。然而,目前的文本到音频生成模型大多依赖于大规模数据集训练复杂的扩散模型。这些模型虽然在音频质量上取得了一定的成就,但往往无法精确捕捉输入文本中的概念及其顺序。这导致了生成的音频内容可能与用户的预期存在偏差。本文将介绍一项新技术——Tango 2,它通过直接偏好优化(Direct Preference Optimization, DPO)来改善这一问题。
Tango 2的核心创新在于其使用了一个合成的偏好数据集,该数据集通过大型语言模型(Large Language Models, LLMs)和对抗性过滤技术生成。这些数据集包括了多样的音频描述(提示)以及相应的优选(赢家)和不优选(输家)音频样本。通过这种方式,Tango 2能够在有限数据的情况下,更有效地学习如何生成与文本提示语义对齐的音频。
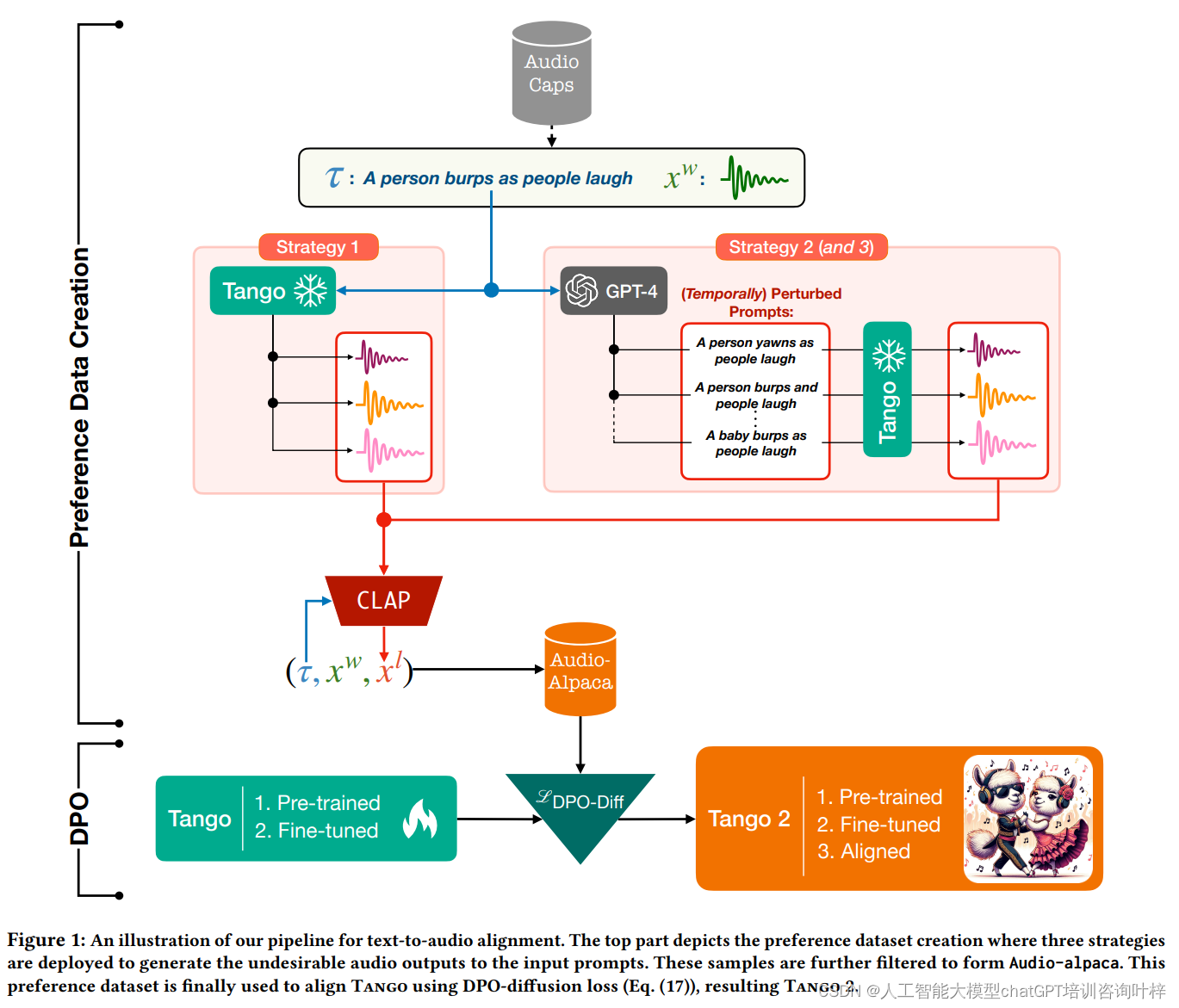
方法论
该方法论主要分为两个关键步骤:构建一个偏好数据集Audio-alpaca,以及通过直接偏好优化(DPO)对模型进行微调。以下是这两个步骤的详细描述:
创建Audio-alpaca数据集
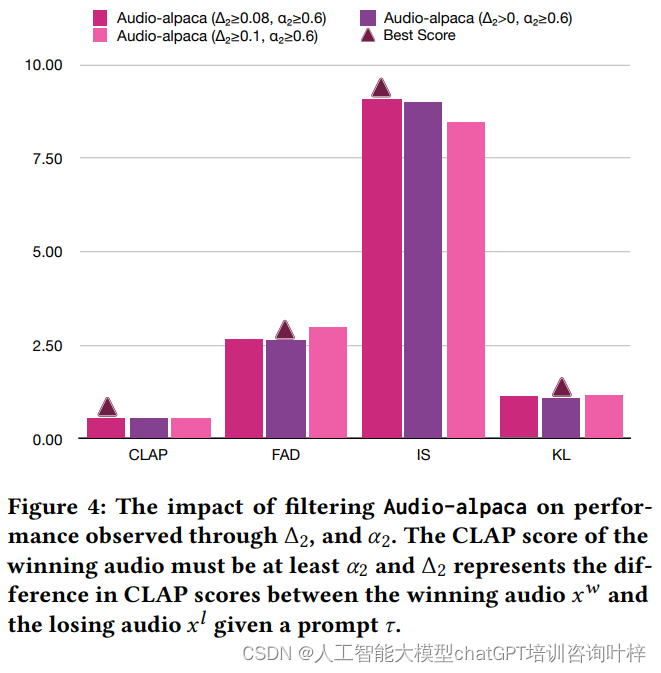
构建Audio-alpaca数据集是Tango 2方法论的第一步,它涉及生成与文本提示相对应的音频样本,并区分出优选(赢家)和不优选(输家)的样本。这一过程采用了三种策略:
-
从同一提示生成多个音频样本:研究者们首先从AudioCaps数据集的训练部分中选取多样化的文本提示。利用一个句子嵌入模型对所有提示进行向量嵌入,并使用K-Means聚类方法选取特定数量的样本作为种子提示集。然后,使用预训练的Tango模型,对这些种子提示进行不同去噪步骤的音频生成,从而得到一组音频样本。
-
从经过语言模型GPT-4微调的提示生成音频样本:在这一步中,研究者利用GPT-4语言模型对选定的文本提示进行语义或概念上的微调,生成五个不同的变体。这些变体旨在保持与原始音频剪辑的紧密关联,同时引入一些描述上的不准确性。接着,使用Tango模型基于这些变体生成音频样本。
-
从时间顺序被打乱的提示生成音频样本:为了捕捉文本提示中事件的序列和同时性,研究者特别寻找包含特定关键词(如“before”、“after”、“then”)的提示。对于这些提示,GPT-4被用来生成一组时间顺序被改变的变体,例如改变原文中事件的顺序或引入新事件。然后,使用与第二步相同的方法生成音频样本。

使用DPO进行模型对齐
在生成了偏好数据集之后,下一步是对Tango模型进行微调,使其更好地符合人类的偏好。这一过程采用了直接偏好优化(DPO)技术:
-
利用扩散DPO损失函数:研究者定义了一个基于扩散模型的DPO损失函数,该函数不仅考虑了优选输出,也考虑了不优选的输出。通过这种方式,模型能够在训练过程中学习如何区分并生成更受偏好的音频样本。
-
对Tango模型进行微调:使用AdamW优化器和线性学习率调度器,在Audio-alpaca数据集上对Tango模型进行微调。微调过程包括一个监督式微调阶段和随后的DPO阶段,以确保模型在生成音频时能够更精确地反映文本提示的意图和结构。
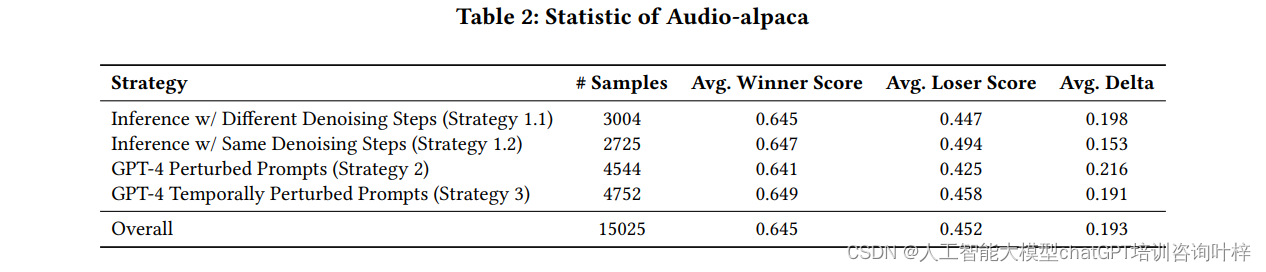
通过这两个步骤,Tango 2能够有效地提升文本到音频生成任务的性能,生成的音频不仅在声学质量上更为自然和多样化,而且在语义上与输入的文本提示更为一致。这一方法论的提出,为未来文本到音频生成技术的发展奠定了新的基石,并为其他多模态内容生成任务提供了新的思路。
实验
数据集和训练细节
实验开始于使用Audio-alpaca数据集对Tango模型进行微调。该数据集包含了15,025对偏好样本,每对样本包括一个文本提示、一个优选音频和一个不优选音频。这些样本被用来训练模型以识别并生成与文本提示语义更匹配的音频输出。微调过程使用了AdamW优化器,设置的学习率为9.6e-7,同时采用线性学习率调度器。DPO损失函数中的β参数设置为2000,以平衡生成过程中的信号与噪声。微调在一个由两个A100 GPU组成的系统上执行,整个微调过程大约耗时3.5小时。
基线比较
为了展示Tango 2的性能,研究者将其与几个强大的基线模型进行了比较,包括AudioLDM、AudioLDM2和Tango。这些模型代表了文本到音频生成领域的最新技术。特别是,AudioLDM2是一个多模态框架,能够处理任意到音频的生成任务。
评估指标
评估过程涉及客观和主观两组指标。客观指标包括Frechet Audio Distance (FAD)、KL散度、Inception Score (IS)和CLAP分数,这些指标用于衡量生成音频的质量和与文本提示的语义对齐程度。主观指标则关注整体音频质量(OVL)和与文本输入的相关性(REL),通过人工评估来完成。
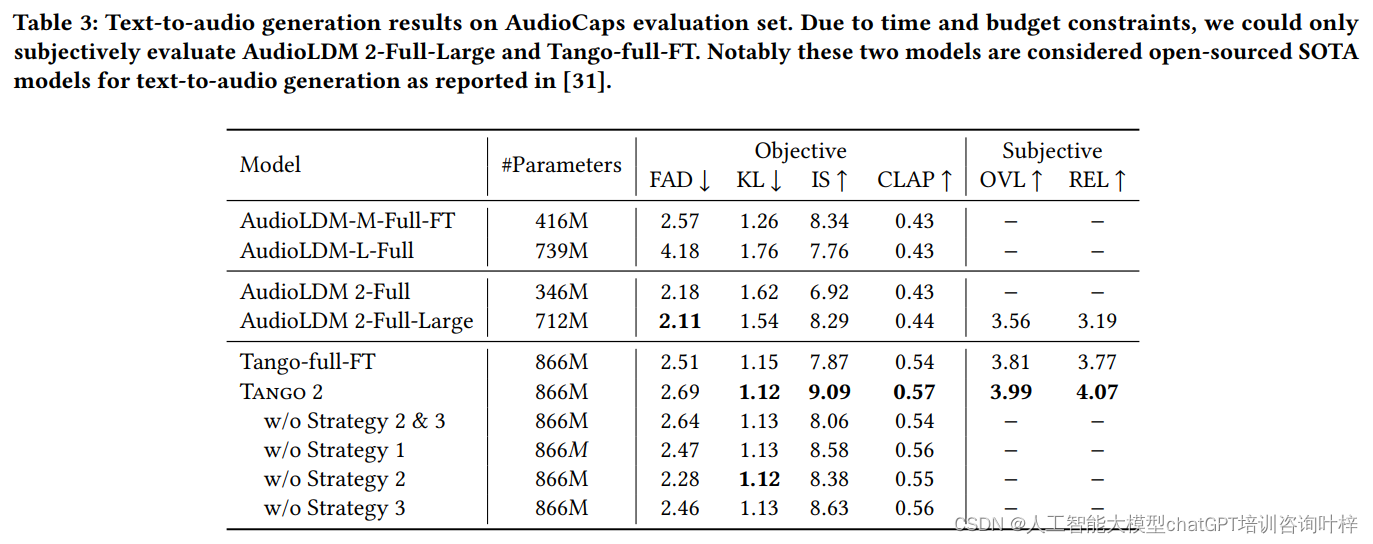
主要结果
在客观评估中,Tango 2在FAD、KL、IS和CLAP分数上均取得了显著的改进,这表明其生成的音频在自然度、多样性和语义对齐方面都有优势。在主观评估中,Tango 2在整体音频质量和与文本输入的相关性上也获得了更高的评分,这进一步证明了Tango 2在生成自然、语义一致的音频方面的优势。
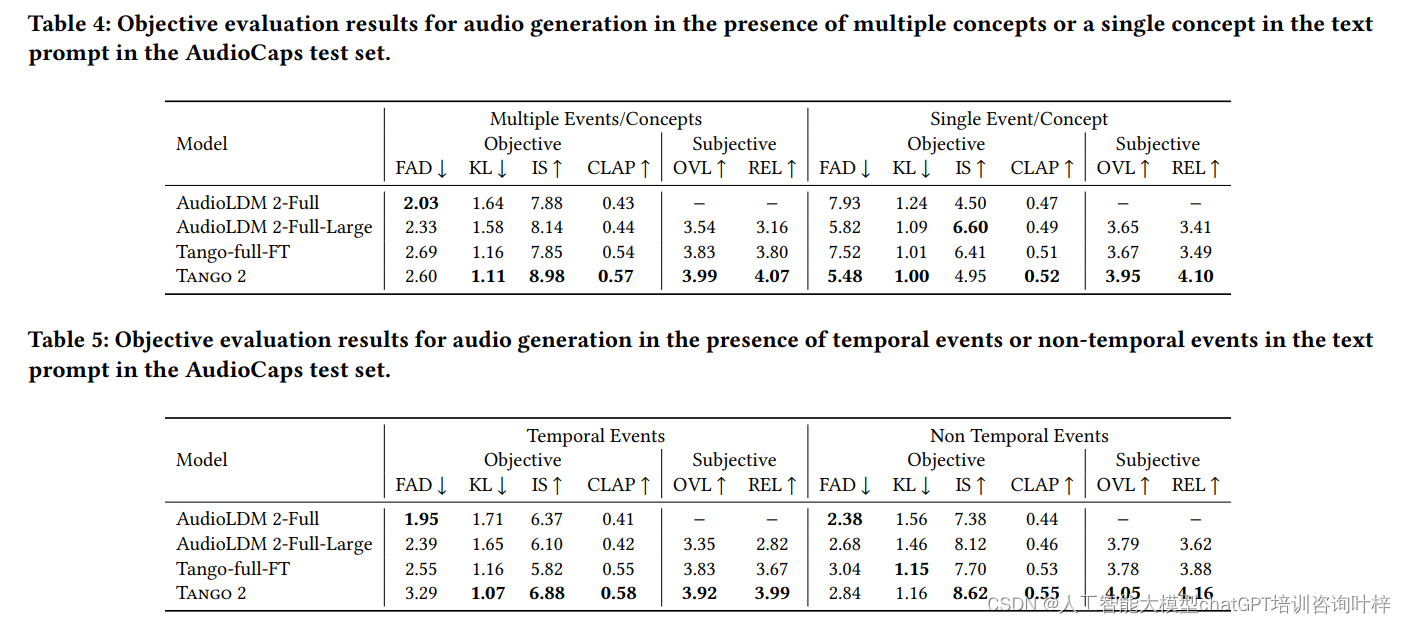
分析
研究者还对Tango 2在处理包含多个概念或事件的文本提示时的性能进行了分析。通过将AudioCaps测试集基于文本提示中的时间标识符划分为多个子集,研究者评估了Tango 2在生成包含时间顺序和不包含时间顺序的事件音频时的表现。结果表明,Tango 2在这两种情况下都取得了优异的成绩。

实验结果证明了Tango 2在文本到音频生成任务中的有效性。通过直接偏好优化和精心设计的Audio-alpaca数据集,Tango 2能够生成与文本提示语义更加一致的音频,同时在音频质量和相关性上都超越了现有的技术。这项工作不仅推动了文本到音频生成技术的发展,也为未来多模态内容生成的研究提供了新的方向。
Tango 2通过直接偏好优化显著提升了文本到音频生成的质量。这项技术不仅提高了音频的自然度和多样性,更重要的是,它增强了生成音频与输入文本之间的语义对齐。随着技术的进一步发展,Tango 2有望成为多媒体内容创作领域的一个强有力的工具。
论文链接:https://arxiv.org/abs/2404.09956
GitHub 地址:https://github.com/declare-lab/tango

















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











