







在人工智能声音编辑领域,一项突破性技术正悄然改变游戏规则。字节跳动的Data-Speech团队最近推出了VoiceShop,这是一款能够让用户在完全保留原始说话者音色的基础上,任意修改语音的年龄、性别、口音和说话风格的先进框架。这项技术的问世,不仅为声音编辑带来了前所未有的灵活性和控制力,还预示着个性化语音合成和语音转换技术的全新时代。
方法
VoiceShop的核心在于其创新的声音编辑方法。以往的技术往往需要针对每个任务训练专门的模型,这不仅限制了模型的通用性,还增加了对特定领域专业知识的需求。VoiceShop通过一个条件扩散骨干模型,配合可选的归一化流和序列到序列的说话者属性编辑模块,解决了这些问题。这一框架的优势在于它的模块化设计,允许在推理过程中根据任务需求组合或移除不同的组件,而无需对模型进行额外的微调。
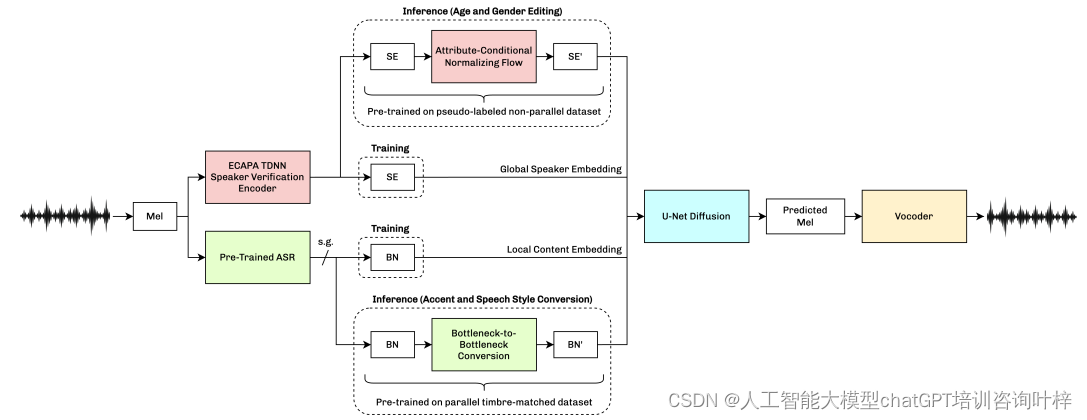
VoiceShop的架构建立在分析-合成方法之上,这是一种在语音处理领域广泛采用的技术。这种方法将语音处理分为两个主要阶段:首先是分析阶段,其次是合成阶段。
在分析阶段,VoiceShop使用自动语音识别(ASR)或音素识别(APR)模型来提取语音信号的时间变化特征。这些特征被称为中间特征图,它们提供了对语音内容的深入理解,包括语音中的音素、韵律和其他声音属性。这些特征图是语音信号的抽象表示,它们捕捉了语音的精髓,同时忽略了一些不必要的细节。
VoiceShop的创新之处在于其属性编辑模块,这些模块在推理期间对源说话者的声音进行精细的调整。这些模块是独立训练的,并且可以针对不同的属性进行定制,如年龄、性别、口音和说话风格。这意味着用户可以单独或组合地编辑这些属性,以达到所需的语音效果。
例如,如果用户想要将一个年轻男性的声音转换成一个年长女性的声音,VoiceShop可以分别对年龄和性别属性进行编辑,而不影响声音的其他特征。这种精细的控制是通过训练单独的模块来实现的,这些模块专注于特定的语音属性,如使用连续归一化流(CNF)模型来处理年龄和性别的编辑,或使用基于序列到序列的模型来处理口音和说话风格的转换。
在推理期间,即模型完成训练并准备应用于实际语音信号时,VoiceShop的属性编辑模块发挥了关键作用。这些模块接收分析阶段提取的中间特征图作为输入,并根据用户指定的编辑任务对这些特征进行调整。例如,如果任务是改变说话者的年龄,那么年龄编辑模块将被激活,而其他模块则保持不变。
这种模块化的设计不仅提高了VoiceShop的灵活性,还允许研究人员和开发者根据特定的需求来定制声音编辑过程。用户可以根据自己的需求选择性地激活或关闭某些编辑模块,从而实现高度个性化的声音输出。
VoiceShop方法概述的核心在于其分析-合成框架与属性编辑模块的结合。这种结合提供了一种强大的工具,可以对语音信号进行细致的分析,然后通过定制的编辑模块来调整特定的属性,最后通过合成阶段重新组合这些特征,生成新的语音输出。这种方法的灵活性和可定制性是VoiceShop区别于其他语音编辑技术的关键特点,它为语音编辑和合成开辟了新的可能性,并为未来的研究和应用奠定了基础。
大规模预训练
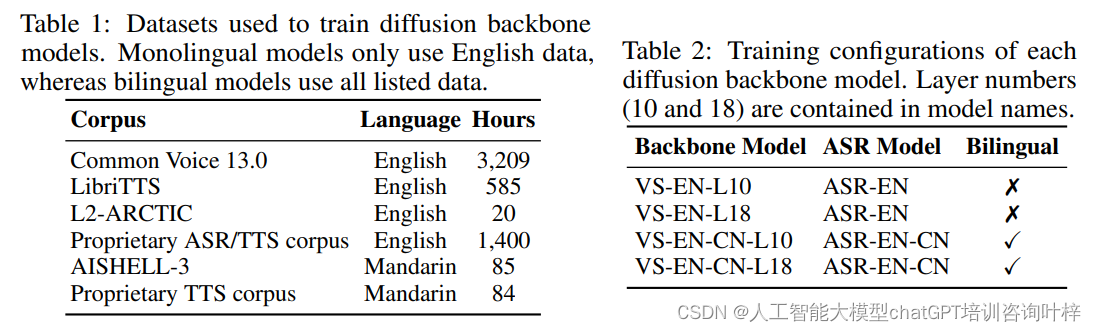
VoiceShop的性能在很大程度上依赖于其预训练模型的质量。论文中详细描述了三个关键的预训练模型:基于conformer的ASR模型、条件扩散骨干模型和声码器。这些模型是VoiceShop框架的核心组成部分,并且它们需要在来自多个说话者的大量多样化语音数据上进行训练。
基于conformer的ASR模型负责将语音转换为文本,这对于理解语音内容和提取特征至关重要。条件扩散骨干模型则是用来预测mel频谱图,这是从语音信号到可编辑特征的桥梁。最后,声码器负责将这些特征转换回语音信号,生成最终的输出。
为了确保这些模型能够学习到丰富和泛化的特征,它们在大规模预训练阶段被训练在各种录音条件下的语音数据上。这包括不同的说话者、口音、背景噪音和录音质量等。通过这种方式,模型能够捕捉到语音信号的多样性,并在零样本的情况下进行有效的推理和声音转换。
VoiceShop方法概述展示了一个全面、多层次的声音编辑框架。从自动语音识别模型的特征提取,到独立的属性编辑模块,再到大规模的预训练过程,每一步都旨在提高最终语音输出的质量和自然度。这种综合的方法不仅推动了声音编辑技术的发展,也为未来的研究和应用提供了新的可能性。
任务特定的语音编辑模块
VoiceShop的灵活性和强大功能在很大程度上归功于它的任务特定语音编辑模块。这些模块的设计宗旨是实现对特定说话者属性的精细控制,同时保留其他属性不变。为了达到这一目标,论文中提出了两种创新的编辑模块:基于归一化流的模块和瓶颈到瓶颈(BN2BN)模型。
基于归一化流的模块
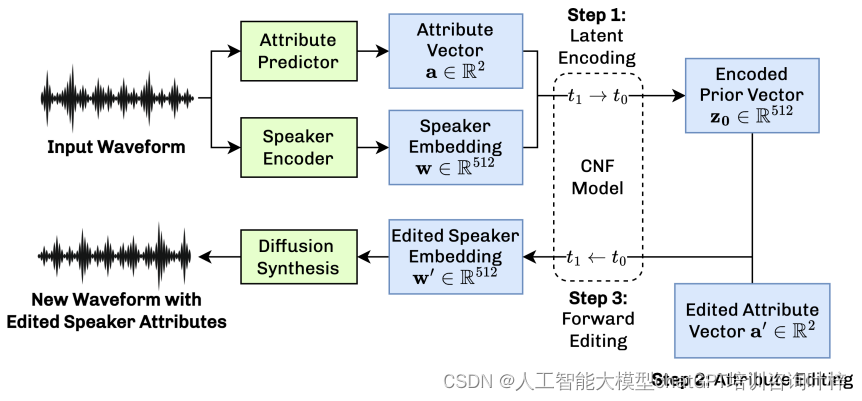
这个模块的灵感来源于图像编辑领域的StyleFlow,它利用连续的归一化流(CNF)来操作说话者嵌入的潜在空间。说话者嵌入是描述说话者特定属性(如年龄和性别)的高维向量,而CNF允许在这个空间内进行条件性的重采样,从而实现对特定属性的精确编辑。
具体来说,CNF通过一个神经常微分方程(ODE)来建模两个分布之间的双向映射。这个过程涉及到一个虚拟的时间变量和一个参数化的神经网络,该网络生成与输入具有相同维度的输出。通过改变变量规则,可以计算对数密度的变化,从而训练CNF以最大化数据的似然性。
在VoiceShop中,CNF模型被训练为在给定说话者属性(如年龄和性别)的条件下,将目标分布的说话者嵌入映射到先验分布。这样,通过CNF,可以实现对特定属性的控制生成和编辑,同时不影响其他属性。
瓶颈到瓶颈(BN2BN)模型
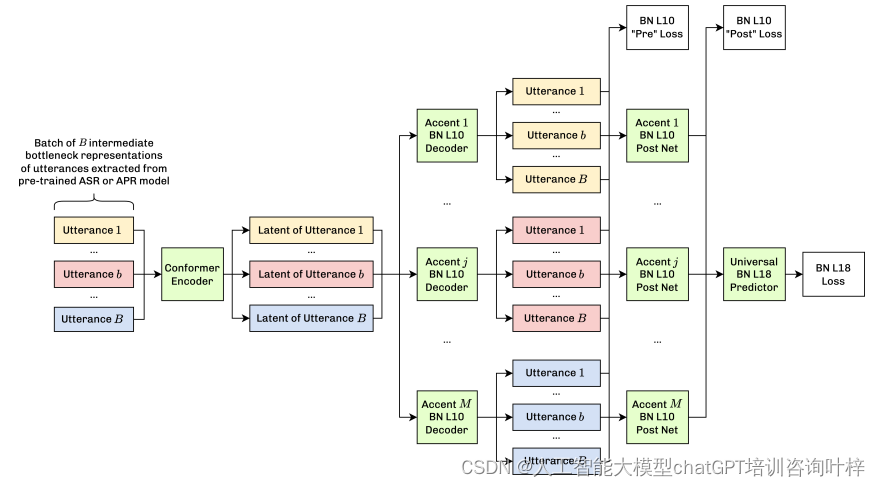
BN2BN模型是VoiceShop中的另一个关键组件,它专门用于实现多对多的口音和说话风格转换。这个模型采用了基于编码器-解码器的序列到序列建模方法,并采用了多解码器架构。
在BN2BN模型中,输入语音首先被编码成时间变化的“瓶颈”内容特征,然后这些特征被映射到任意数量的目标口音或说话风格。这种方法有效地将口音转换任务简化为机器翻译问题。
BN2BN模型的训练过程涉及到将非平行语料库增强为平行的多说话者、多口音“音色匹配”数据集。这是通过利用文本到语音(TTS)和声音转换(VC)建模来实现的,仅需要最少的文本语料库。
实验与分析
为了展示VoiceShop在各种合成相关任务上的多功能性,论文中进行了一系列的实验,并详细指定了使用的每种模型配置。这些实验包括零样本声音转换、身份保留的多对多口音转换、零样本说话风格转换以及零样本结合多属性编辑。
为了全面评估VoiceShop的性能,论文采用了主观和客观的评估指标。主观评估通过平均意见得分(MOS)和比较平均意见得分(CMOS)来进行。在这些研究中,参与者被要求根据预定的指标(如感知说话者相似度、转换强度和自然度)对VoiceShop的性能进行评判。
客观评估则使用了自动说话者验证(ASV)指标,通过计算从预训练的说话者验证模型中提取的固定长度嵌入的余弦相似度来评估说话者之间的相似性。ASV指标的范围在-1到1之间,较高的值表示在说话者验证模型的学习到的潜在空间内相似度更高。
在零样本声音转换的实验中,VoiceShop被用来将一个说话者的声音转换为另一个说话者的声音,而这些说话者在训练期间并未被模型见过。这项任务在单语种和跨语种的设置中都进行了测试,例如将普通话的口音应用到英语内容上。实验结果显示,VoiceShop能够在保持原始语音内容的同时,有效地改变说话者的声音特征。
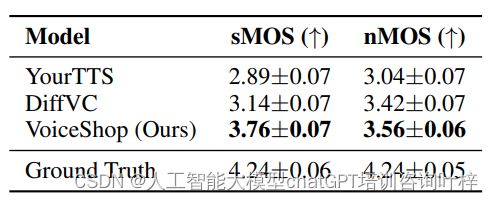
口音和说话风格转换的实验进一步展示了VoiceShop的能力。在这里,研究团队测试了模型在将一种口音或说话风格转换为另一种时的表现。这包括了跨语种的转换,例如将英国口音应用到普通话语音上,即使模型在训练时没有见过这样的转换对。实验结果表明,VoiceShop能够在不牺牲说话者原有音色的情况下,成功地转换口音和说话风格。
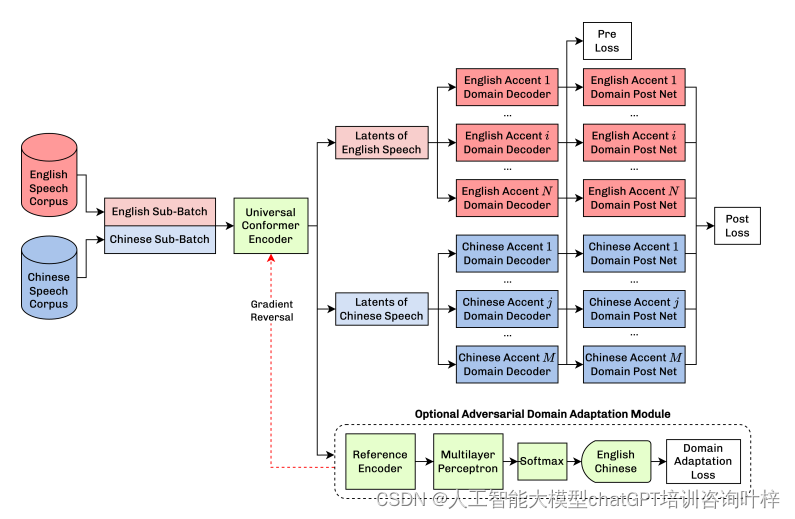
实验展示了VoiceShop在单语种和跨语种口音转换上的能力。在单语种情况下,源和目标口音属于同一语言;而在跨语种情况下,转换涉及不同语言的口音,例如将英国口音应用于普通话语音,即使没有直接的英国口音的普通话录音作为训练数据。
为了实现跨语种口音转换,作者对BN2BN(Bottleneck-to-Bottleneck)模型进行了改进,如图4所示。模型增加了一个梯度反转模块,以促进语言无关的内容表示,通过设置λ=-1来实现。这种设计允许模型在不同语言间转换口音,同时保持语言内容的忠实度。
通过主观和客观的评估,实验结果表明VoiceShop在口音强度和说话者相似度方面均表现出色。主观评估通过CMOS测试进行,而客观评估则使用了口音分类器和ASV指标。这些评估显示,VoiceShop在转换口音时,能够保持说话者身份的同时,有效地转换口音特征。
在年龄和性别编辑的实验中,VoiceShop被用来改变语音样本中说话者的年龄和性别属性。这些实验在零样本的条件下进行,意味着模型在训练时没有见过目标年龄或性别的说话者。通过使用基于归一化流的模块,VoiceShop能够对年龄和性别进行细致的调整,同时保持语音的其他属性不变。

通过t-SNE可视化技术,研究者们展示了输入语音和输出语音在特征空间中的分布。输入语音根据其源口音被有效地聚集在一起,而VoiceShop转换后的输出语音则在特征空间中保持了这些聚集结构,按照目标说话风格进行分类。这种聚类表明模型能够捕捉并保留说话风格的特征,即使这些风格在训练数据中未曾出现。
最后,研究团队还展示了VoiceShop在同时编辑多个属性时的能力。这要求模型在单次前向传递中同时改变说话者的口音、年龄和性别。实验结果证明了VoiceShop的模块化设计能够有效地解耦和控制不同的语音属性,允许用户在不影响其他属性的情况下,同时编辑多个属性。
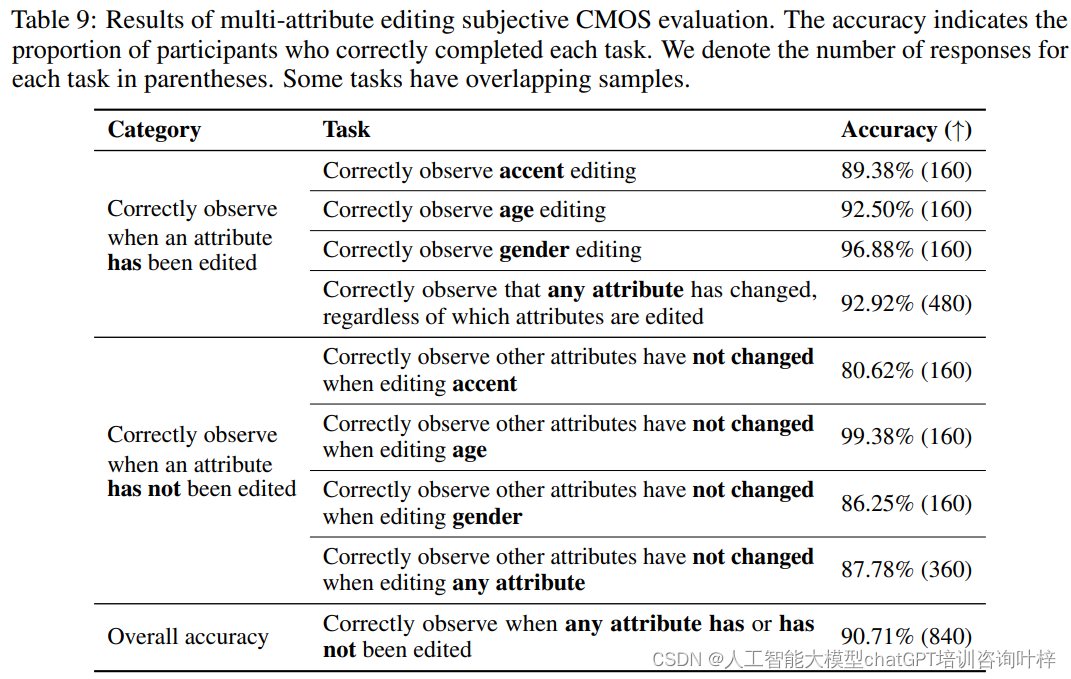
实验结果通过一系列的图表和统计数据进行了展示。这些结果不仅证明了VoiceShop在各种语音编辑任务中的有效性,还揭示了它在保持语音自然度和说话者相似度方面的优势。实验还突出了VoiceShop在处理复杂语音编辑任务时的灵活性和可扩展性。
VoiceShop的推出,不仅是字节跳动在人工智能领域的一次重要创新,更是声音编辑技术的一大步。它不仅提供了一种新的、多功能的声音修改工具,还展示了AI在处理复杂任务时的巨大潜力。随着技术的不断进步,我们可以期待未来在语音合成和编辑领域出现更多创新和应用。
论文链接:https://arxiv.org/abs/2404.06674
项目地址:https://voiceshopai.github.io/



















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











