






本文分享实践中对LLM+RAG实现知识问答系统的相关调研和思考。不足之处,还望批评指正。
LLM的知识库问答有3种实现路径:RAG 或 微调,或两者结合。而RAG和微调都各有利弊,比如说:
- RAG:低成本易部署,适用于知识会更新的场景,但知识内容多的情况下,检索成本会变高。
- 微调:算力成本高,微调效果不稳定,训练不好容易出现幻觉,不适用于知识频繁更新场景,但调好后,LLM回复速度很可观。
在实践RAG+Langchain开源知识问答项目时,我发现有以下难点(待改进点):
(1) 对文本切片基本采用的是:固定长度分割文本,且分割窗口之间留一定重叠内容,以避免损失上下文语义信息。虽然简单便捷,但缺点也很明显,比如在以下场景:
如果文本分片长度限制过小,一级标题下的段落二和三就会丢失一级标题这个关键信息,同理,如果对系统构成做提问,可能RAG只检索出组件1,因为组件2和3因分片长度限制没归到同一文本块内。但放大文本分片长度又容易给LLM带来冗余噪声信息,影响模型回答(特别是部分开源LLM对上下文长度支持和语义理解相对较弱)。
(2) 单纯RAG+LLM做知识问答,当出现知识内容较多,检索成本就很高,因为要遍历所有文本块。
(3) 用户用关键字提问,RAG检索不到相关文本,往往需要补全问题信息。
(4) 有些知识内容是多模态的,如pdf内带有图表,ppt等。如何将多模态知识加入知识库并做知识问答?
难点1&2&3
先回答第一个难点:如何做好文本切片?我查了些网络上的解决方案,答案是:语义切分。公开网络上的语义切分主要有以下2类方法[3]:
(1) 篇章分析:利用NLP的篇章分析(discourse parsing)工具,提取出段落之间的主要关系,把所有包含主从关系的段落合并成一段。这样对文章切分完之后保证每一一个文本分块在说同一件事情。
(2) BERT判断段落相似度:BERT等模型(如BERT-base-Chinese)在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值t,从前往后依次判断相邻两个段落的相似度分数是否大于t,如果大于则合并,否则断开。其实,本质上就是段落分割,最近试了阿里语音实验室的SeqModel模型,还可以,有兴趣的伙伴可以用modelscope直接调用。
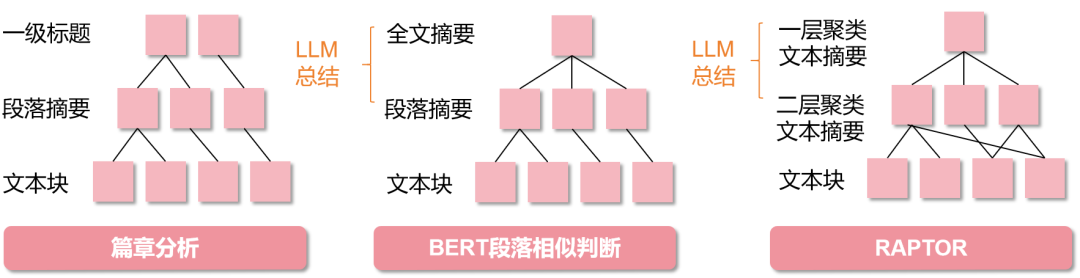
那切完后,又会存在难点(1)中大块切片的噪声问题 和 难点(2)中检索成本高的问题,;为此,我们可以利用层次检索或称树形检索的方式去做,对应方式如下图所示:
图片
像篇章分析获取的文本块是具有层次的依存关系的,则可以如上图左1所示。检索时,从上至下检索,检索过程中配合剪枝(即,只选择每层topk相似度的节点往下检索)。而BERT段落相似判断,由于没有依存关系,所以需要适用LLM做总结获取摘要。而2024年斯坦福大学提出的RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)[5] 是对固定长度分割后的文本块embedding做语义聚类后,将各类内文本用LLM总结出摘要,生成摘要embedding作为树的节点。
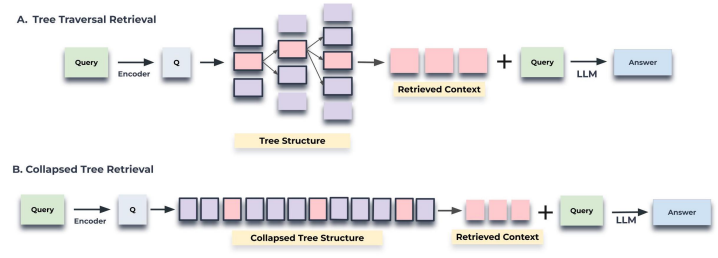
在以上3种层次结构中,由于语义切分后的一个文本块(即一个段落)可能会很多字,所以还是会采用固定长度分割下文本块,好处是检索时能抓住细节的同时避免引入段落内其他冗余文本(再啰嗦一句,很多开源开源LLM对上下文长度支持和语义理解相对较弱)。如果说你不担心检索成本问题(比如你采用并行检索),那你将层次结构压平后检索也更好。
图片
至此难点(1)和(2)都解决了,我们来看看难点(3):用户用关键字提问,RAG检索不到相关文本,往往需要补全问题信息。针对此难点,公开资料也有一些解决方案:
(1) 引入追问机制 [1]:在Prompt中加入“如果无法从背景知识回答用户的问题,则根据背景知识内容,对用户进行追问,问题限制在3个以内”。这个机制并没有什么技术含量,主要依靠大模型的能力。不过大大改善了用户体验,用户在多轮引导中逐步明确了自己的问题,从而能够得到合适的答案。
增加追问机制,也仅是让用户去完善自己的问题,比如针对“用户给出的查询条件不足”,有时关键词提问,就会出现检索失败,但对关键词补充成语句,就能增加检索的成功性。(不过如果多轮引导后还是回答不出来,感觉对用户体验也有很大的影响,因此结合猜你所想给出已知的高频QA推荐,应该能一定程度减轻用户观感差的风险)
(2) 关键信息抽取 [3]:利用NLP的句法分析、NER、依存分析、语义角色标注、关键词提取等去抽取关键信息,将抽取到的关键信息加入到前面层次检索的顶部就行。先检索关键信息,然后在检索对应关键信息下的内容。缺点也很明显,如果用户对原始文本的提问涉及到的信息没被提前抽取到位,那就检索不到了。
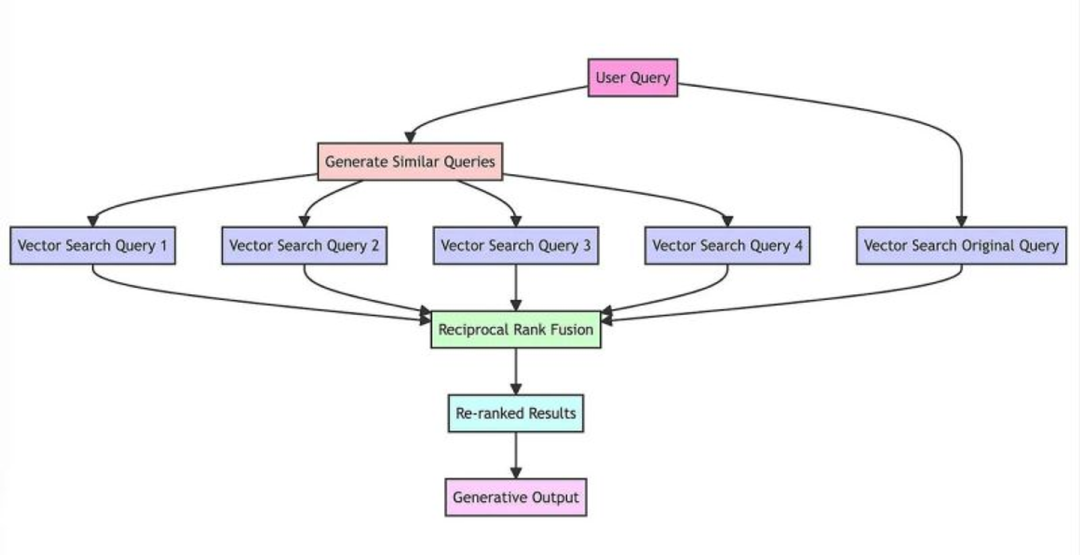
(3) RAG-Fusion [2]: 让LLM去优化用户query,改写输入query,丰富搜索信息后,都分别喂入LLM,获取到回复后,使用倒数排序融合 (Reciprocal rank fusion, RRF) 得到统一得分,重排取TOP k检索结果。RRF本质是取检索结果在所在召回路内的排名倒数,然后相加后作为得分,用于衡量一个文档是不是在N路召回中都排在前面。RAG-Fusion的缺点是费时,因为要提问多次。
图片
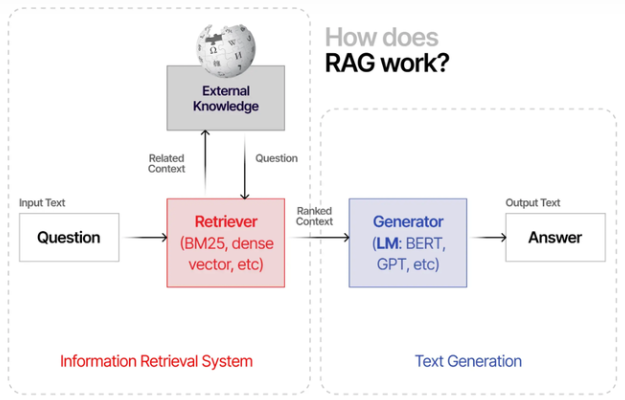
(4) 混合搜索:这是目前看来,我觉得一种值得尝试的低成本高收益方案。将字面相似的传统搜索算法(Best Matching 25, BM25)与向量相似性检索相结合,实现混合搜索[6]。可以加权融合分数、取各自topk检索后并集或RRF+Rerank。
图片
难点4
有些知识内容是多模态的,如pdf内带有图表,ppt等。如何将多模态知识加入知识库并做知识问答?在[1]中,给出了一个方案:单独部署一个多模态模型,通过prompt来对文档中的图片进行关键信息提取,形成一段摘要描述,作为文档图片的索引。缺点是比较考验多模态模型对图片描述程度,比如描述不够细致,导致缺乏与用户query相关的细节信息。其实,可以将图片、表格、ppt都看作图片,然后分别用多模态模型和OCR模型,分别抽取摘要描述和源数据中的数据和文本要素,整理后,作为源数据的知识分片。可以参考下[7] [8]。
参考资料
[1] 对于大模型RAG技术的一些思考 - 队长的文章 - 知乎:https://zhuanlan.zhihu.com/p/670432927
[2] 大语言模型(LLM)之更好的搜索增强生成(RAG)方案——RAG-Fusion - 王鹏的文章 - 知乎:https://zhuanlan.zhihu.com/p/673508315
[3] 基于LLM+向量库的文档对话痛点及解决方案 - Walker的文章 - 知乎:https://zhuanlan.zhihu.com/p/651179780
[4] ChatPDF | LLM文档对话 | pdf解析关键问题 - Walker的文章 - 知乎:https://zhuanlan.zhihu.com/p/65297567
[5] Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., & Manning, C. D. (2024). RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. arXiv preprint arXiv:2401.18059.
[6] RAG提效利器——BM25检索算法原理和Python实现 - 王鹏的文章 - 知乎:https://zhuanlan.zhihu.com/p/670322092
[7] 斯坦福 | 提出PDFTriage,解决结构化文档的问题,提升「文档问答」准确率 - NLP自然语言处理的文章 - 知乎:https://zhuanlan.zhihu.com/p/657316158
[8] ChatPDF | LLM文档对话 | pdf解析关键问题 - Walker的文章 - 知乎:https://zhuanlan.zhihu.com/p/652975673















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









