






介绍
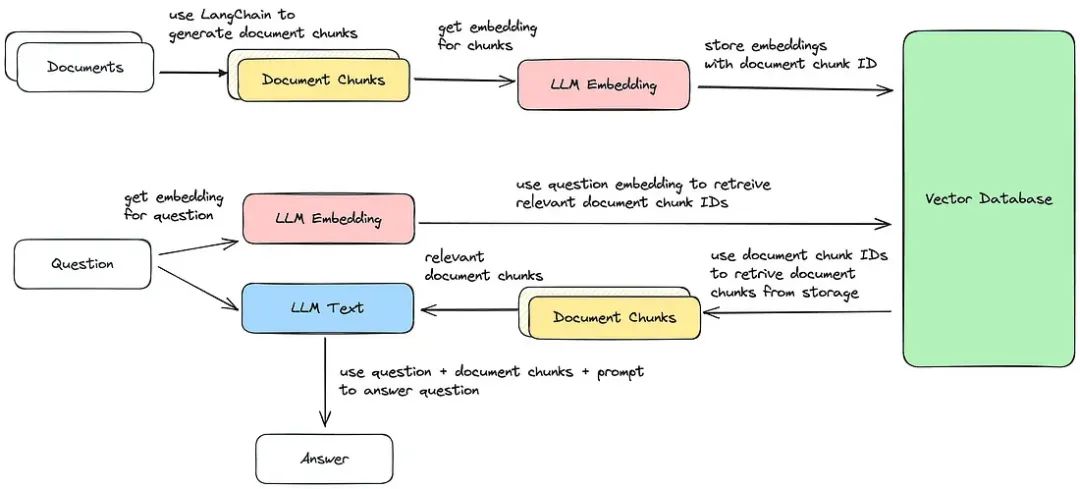
本文将探讨如何利用语言模型和文本分块构建一个问答系统。我们将使用PyPDF2、langchain、Hugging Face和FAISS等工具从PDF中提取文本,将其处理成可管理的块,创建嵌入并利用这些嵌入进行高效的基于检索的问答。
什么是LLM?
LLM代表“语言模型”,它是一类用于自然语言处理(NLP)任务的人工智能模型。语言模型被设计用于理解和生成人类语言文本。它们具有预测句子中下一个词、完成文本提示以及执行各种与语言相关的任务的能力。
LLM通常在大量文本数据的大型语料库上进行预训练,以学习语言模式、语法和语义。一些知名的LLM包括OpenAI的GPT(生成式预训练变换器)模型和Hugging Face的Transformers模型。LLM具有广泛的应用,包括文本生成、翻译、摘要和问答。
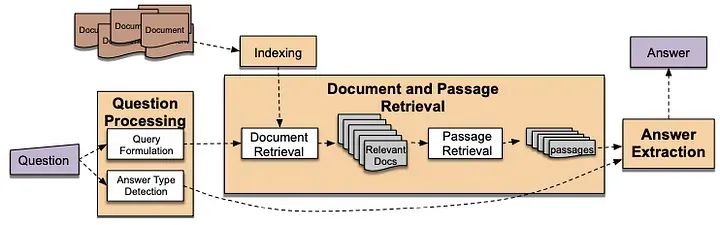
什么是问答系统,以及如何构建它?
问答系统是一种自然语言处理(NLP)系统,旨在回答用户用自然语言提出的问题。这些系统以问题作为输入,并输出相关且信息丰富的答案。问答系统广泛应用于各个领域,包括搜索引擎、客户支持聊天机器人、虚拟助手和信息检索。
构建问答系统是一个结构化的过程,涉及几个基本步骤。最初,数据收集涉及收集包含与潜在用户查询相关的文本文档或文章的广泛数据集。在此之后,数据预处理至关重要,包括清理、标记化和以适于深度分析的方式结构化文本数据。
随后的步骤涉及文本索引,其中创建索引或数据库以便根据用户查询高效检索相关文档。采用TF-IDF或词嵌入等技术进行有效的索引。在建立强大的数据基础后,开发一个问题处理组件来分析用户问题,包括标记化、语义分析和理解问题意图。
然后实施一个检索组件来搜索索引文档,提取与用户查询相关的最相关的段落或文档。在成功检索后,采用命名实体识别或信息提取等答案提取技术,精确提取检索到的文档中的答案。
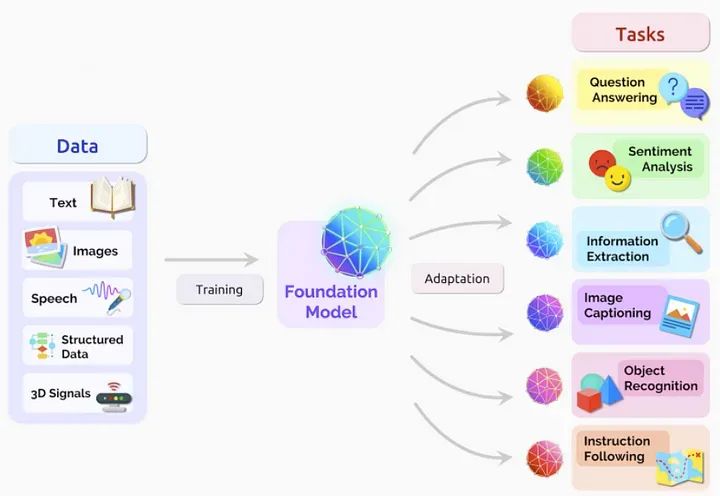
获取的答案然后通过答案呈现组件以可读和可理解的格式呈现给用户。随后,创建用户界面或应用程序,实现无缝交互,使用户能够输入问题并获得准确的回答。持续的评估和用户反馈收集对该过程至关重要,有助于系统性能评估和改进,以提高准确性和相关性。
此外,集成机器学习模型,如GPT等语言模型,是一个可选但非常有益的步骤,增强系统理解和有效生成自然语言响应的能力。最终,完全开发的问答系统被部署供实际使用,满足各种用户查询和需求。
设置环境
在这一初始步骤中,我们正在配置我们的Python环境并安装项目所需的基本库。使用google.colab库来方便地将Google Drive挂载到Colab环境中。这使得可以轻松访问存储在Google Drive上的文件。随后,我们使用pip,Python的包安装程序,来安装所需的Python包,其中包括PdfReader、langchain、PyPDF2、InstructorEmbedding、sentence_transformers和faiss等。
然后,我们导入将在整个项目中使用的关键库。PyPDF2库从PDF中提取文本,使我们能够处理所需的文本数据。此外,我们从langchain库导入各种组件,如CharacterTextSplitter、OpenAIEmbeddings、HuggingFaceInstructEmbeddings、FAISS、ChatOpenAI、ConversationBufferMemory、ConversationalRetrievalChain、RetrievalQA、HuggingFaceHub和PromptTemplate。这些组件将在处理文本和实现问答功能中发挥重要作用。
from google.colab import drive
drive.mount('./content/')
cd '/content/'
!pip install PdfReader
!pip install langchain
!pip install PyPDF2
!pip install InstructorEmbedding
!pip install sentence_transformers
!pip install faiss
!pip install faiss-gpu
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.chains import RetrievalQA
from langchain.llms import HuggingFaceHub
import os
from langchain.prompts.prompt import PromptTemplate从PDF中提取文本
接下来,我们继续从PDF文档中提取文本。定义了get_pdf_text函数来处理此任务。它通过pdf_docs指定的PDF列表进行迭代,使用PyPDF2的PdfReader组件逐页读取PDF内容。对于每一页,提取文本内容并将其连接成一个字符串,然后将其作为输出返回。我们提供PDF文件的路径并调用此函数,从PDF中提取所需的文本。
def get_pdf_text(pdf_docs):
text = ""
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
# Path to the PDF file
path_to_pdf = ['./content/MyDrive/data_set/new_diseases_data.pdf']
# Extract text from PDF
raw_text = get_pdf_text(path_to_pdf)创建检索型语言模型链
在这一部分,我们定义了一个名为retrieval_qa_chain的函数,该函数利用语言模型(LLM)创建了一个基于检索的问答链。让我们逐步分解这个函数的组件和功能。
def retrieval_qa_chain(db, return_source_documents):
llm = HuggingFaceHub(repo_id="tiiuae/falcon-7b-instruct", model_kwargs={"temperature": 0.6, "max_length": 500, "max_new_tokens": 700})
qa_chain = RetrievalQA.from_chain_type(llm=llm,
chain_type='stuff',
retriever=db,
return_source_documents=return_source_documents,
)
return qa_chainretrieval_qa_chain函数旨在使用Hugging Face模型库的预训练语言模型(LLM)创建基于检索的问答链。该函数接受两个参数:db(一个检索数据库)和return_source_documents(一个布尔值,指示是否返回源文档以及答案)。
设置环境变量和准备数据
在代码的这一部分,我们设置环境变量并准备数据以进行进一步处理。
os.environ["HUGGINGFACEHUB_API_TOKEN"] = ""设置Hugging Face Hub API令牌
`os.environ`是Python模块,允许访问系统的环境变量。
我们设置了一个名为“HUGGINGFACEHUB_API_TOKEN”的环境变量,并为其分配了一个特定的令牌。这个令牌可能是用于身份验证或访问Hugging Face Hub资源的。
path_to_pdf = ['./content/MyDrive/data_set/new_diseases_data.pdf']指定PDF路径
`path_to_pdf`是一个包含PDF文件路径的列表。
在这种情况下,它指向指定目录中名为“new_diseases_data.pdf”的PDF文件。
raw_text = get_pdf_text(path_to_pdf)从PDF中提取文本
我们调用`get_pdf_text`函数从指定的PDF文件中提取文本。
提取的文本存储在变量`raw_text`中。
# get the text chunks
text_chunks = get_text_chunks(raw_text)对文本进行分块
我们调用`get_text_chunks`函数将提取的原始文本分割成较小的、可管理的块。
这些块存储在变量`text_chunks`中。
# create vector store
vectorstore = get_vectorstore(text_chunks)创建向量存储
我们调用`get_vectorstore`函数从文本块中创建向量存储。
这涉及将文本块嵌入以创建可用于各种NLP任务的数值表示(向量)。
创建具有相似性搜索的数据库
在代码的这一部分,我们使用向量存储创建了一个用于相似性搜索的数据库。
db = vectorstore.as_retriever(search_kwargs={'k': 3})创建数据库
我们使用`vectorstore`(它是我们文本块的向量存储)来创建一个用于相似性搜索的检索数据库。
`as_retriever`函数用于将向量存储转换为检索数据库,允许我们执行相似性搜索。
搜索参数
`search_kwargs={‘k’: 3}`指定了相似性搜索的搜索参数。在这种情况下,它搜索每个查询向量的前3个最相似的向量。
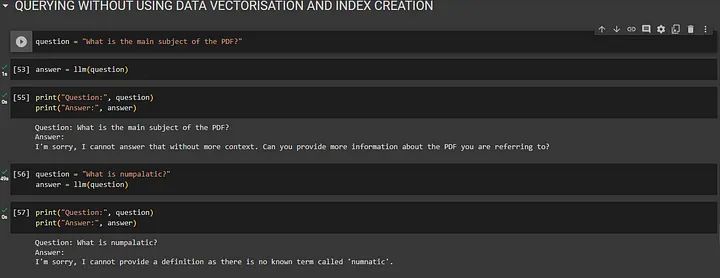
当您在不使用向量数据库的情况下提出问题时,系统会尽力根据自己对单词和句子的理解来回答。但有时,它可能不完全理解您的问题,可能会给出错误或不清楚的答案。
 向量和索引概念下的系统响应
向量和索引概念下的系统响应
## QUERYING WITHOUT USING DATA VECTORISATION AND INDEX CREATION
question = "What is the main subject of the PDF?"
answer = llm(question)
print("Question:", question)
print("Answer:", answer)
question = "What is numpalatic?"
answer = llm(question)
print("Question:", question)
print("Answer:", answer)
question = "What is Nampdicta?"
answer = llm(question)
print("Question:", question)
print("Answer:", answer)Question: What is the main subject of the PDF? Answer: I'm sorry, I cannot answer that without more context. Can you provide more information about the PDF you are referring to?
Question: What is numpalatic? Answer: I'm sorry, I cannot provide a definition as there is no known term called 'numnatic'.
Question: What is Nampdicta? Answer: Nampdicta is a command-line tool for generating and processing NAMD output files, designed to be easy to use for scientists who need to generate large numbers of output files at a time.
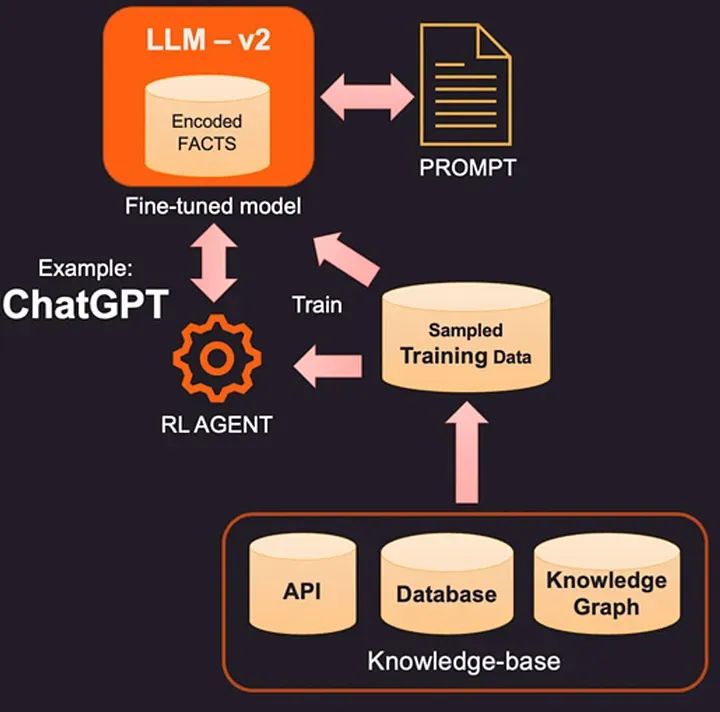
 然而,当我们使用从PDF(文档)创建的向量数据库时,它有助于系统更好地理解问题。这就像有一个了解文档的有用向导(向量数据库)。这个向导可以引导系统到文档的正确部分,这些部分可能包含答案。因此,当您使用向量数据库提问时,系统可以提供更准确和有用的答案,因为它有这个‘向导’帮助它在文档的上下文中理解您的问题。
然而,当我们使用从PDF(文档)创建的向量数据库时,它有助于系统更好地理解问题。这就像有一个了解文档的有用向导(向量数据库)。这个向导可以引导系统到文档的正确部分,这些部分可能包含答案。因此,当您使用向量数据库提问时,系统可以提供更准确和有用的答案,因为它有这个‘向导’帮助它在文档的上下文中理解您的问题。
初始化问答机器人
在这一部分,我们初始化一个问答机器人,使用基于检索的问答链进行配置,然后向机器人提问以获取答案。
bot = retrieval_qa_chain(db, True)初始化机器人
我们使用`retrieval_qa_chain`函数创建一个机器人实例,传入检索数据库(db)并将return_source_documents设置为True。这样配置机器人将返回源文档以及答案。
query = "what is Nampdicta?"
sol = bot(query)向机器人提问
我们定义一个问题/查询。
我们使用机器人实例向系统提问,询问定义的问题。
得到的答案存储在`sol`中。
print(sol['result'])打印答案
我们打印从语言模型(LLM)获得的答案,作为对查询的响应。
print("These are the text chunks matched with LLM:")
print(sol['source_documents'])打印匹配的文本块
我们打印由语言模型(LLM)匹配的文本块,作为对查询的响应。
# normal falcon without context
llm = HuggingFaceHub(repo_id="tiiuae/falcon-7b-instruct", model_kwargs={"temperature":0.7,"max_length":500,"max_new_tokens":700})
llm(query)
创建语言模型(LLM)实例
我们使用HuggingFaceHub创建一个没有上下文的语言模型(LLM)实例。
该实例使用与用于机器人的不同的温度和长度配置。
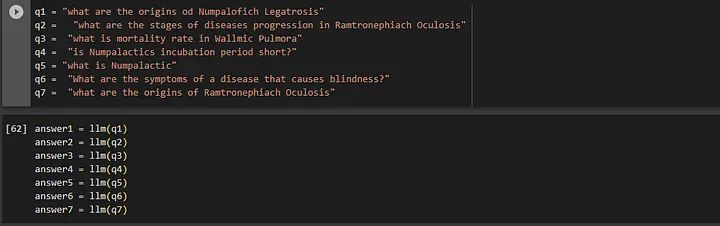
ques = ['what are the origins of Numpalofich Legatrosis', ...]定义多个问题
我们定义一个要向机器人提问的问题列表。
sol = bot(ques[0])
print(ques[0])
print(sol['result'])提问并打印结果
我们向机器人询问列表中的第一个问题(ques[0])。
我们打印问题和从机器人获得的答案。
完整代码:
from google.colab import drive
drive.mount('./content/')
cd '/content/'
## installing required modules
!pip install PdfReader
!pip install langchain
!pip install PyPDF2
!pip install InstructorEmbedding
!pip install sentence_transformers
!pip install faiss
!pip install faiss-gpu
## import required libraries
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.chains import RetrievalQA
from langchain.llms import HuggingFaceHub
import os
from langchain.prompts.prompt import PromptTemplate
## extracting text from pdf files
def get_pdf_text(pdf_docs):
text = ""
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
## creating overlapping text chunks
def get_text_chunks(text):
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
## creating embeddings for chunks of text
def get_vectorstore(text_chunks):
#embeddings = OpenAIEmbeddings()
embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-xl")
vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
return vectorstore
## ceating a retrival llm chain
def retrieval_qa_chain(db,return_source_documents):
llm = HuggingFaceHub(repo_id="tiiuae/falcon-7b-instruct", model_kwargs={"temperature":0.6,"max_length":500, "max_new_tokens":700})
qa_chain = RetrievalQA.from_chain_type(llm=llm,
chain_type='stuff',
retriever=db,
return_source_documents=return_source_documents,
)
return qa_chain
## DATA VECTORIZATION AND INDEX CREATION
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "<REPLACE WITH YOUR API TOKEN>"
path_to_pdf = ['./content/MyDrive/data_set/new_diseases_data.pdf']
raw_text = get_pdf_text(path_to_pdf)
# get the text chunks
text_chunks = get_text_chunks(raw_text)
# create vector store
vectorstore = get_vectorstore(text_chunks)
## creating a db with similarity search and obtaining top 3 most matched vectors of all the vectors present in vector index
db = vectorstore.as_retriever(search_kwargs={'k': 3})
## passing database to bot as input and initializing the bot
bot = retrieval_qa_chain(db,True)
## passing query to llm
query = "what is Nampdicta?"
sol=bot(query)
## answer giveb by llm
print(sol['result'])
these are the text chunks matched with llm
print(sol['source_documents'])
# normal falcon without context
llm = HuggingFaceHub(repo_id="tiiuae/falcon-7b-instruct", model_kwargs={"temperature":0.7,"max_length":500, "max_new_tokens":700})
llm(query)
ques=['what are the origins od Numpalofich Legatrosis',
'what are the stages of diseases progression in Ramtronephiach Oculosis',
'what is mortality rate in Wallmic Pulmora',
'is Numpalactics incubation period short?',
' what is Numpalactic',
' What are the symptoms of a disease that causes blindness?',
'what are the origins of Ramtronephiach Oculosis']
sol=bot(ques[0])
print(ques[0])
print(sol['result'])
sol=bot(ques[1])
print(ques[1])
print(sol['result'])
sol=bot(ques[2])
print(ques[2])
print(sol['result'])
sol=bot(ques[3])
print(ques[3])
print(sol['result'])
sol=bot(ques[4])
print(ques[4])
print(sol['result'])
sol=bot(ques[5])
print(ques[5])
print(sol['result'])
sol=bot(ques[6])
print(ques[6])
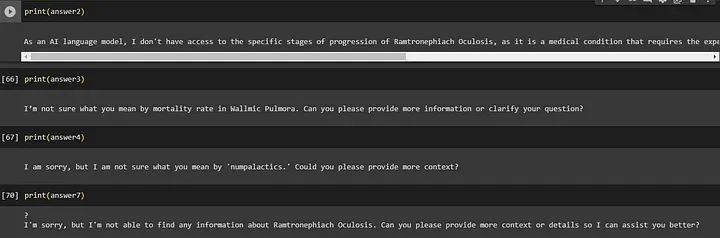
print(sol['result'])输出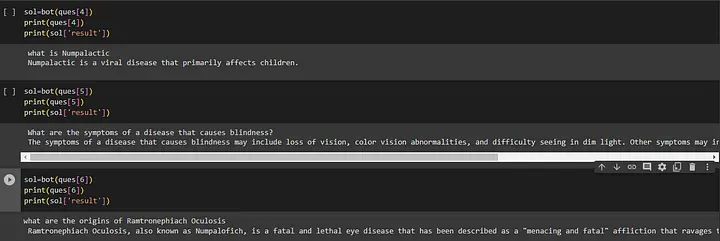
总结
总的来说,这段代码脚本涵盖了一系列任务的流程,从提取PDF文本开始,进行预处理和分块文本,生成嵌入,建立基于检索的问答系统,向系统提问以获取答案,以及有效处理多个问题以提供各自的答案。这个流程实现了对给定文本语料库的有效信息检索和问答。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除















 4321
4321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









