







LangChain + LLM 方案的局限性:LLM意图识别准确性较低,交互链路长导致时间开销大;Embedding 不适合多词条聚合匹配等。
背景
在探索如何利用大型语言模型(LLM)构建知识问答系统的过程中,我们确定了两个核心步骤:
- 将用户提出的问题和知识库中的信息转换成嵌入向量(Embeddings),然后利用向量相似度技术来检索最相关的知识条目。
- 利用LLM来识别用户问题的意图,并对检索到的原始答案进行加工和整合,以提供更加精准和有用的回答。
然而,这种方法在实际应用中遇到了一些挑战:
- 上层应用与模型基础的紧耦合导致灵活性受限。每当需要更换或升级语言模型时,上层的应用逻辑也必须进行大量的调整。在LLM技术迅速发展的今天,由于成本、许可、技术热点和性能等多方面的考量,模型的变更几乎是不可避免的。
- 处理环节的不完善和高开发成本也是一个问题。例如,嵌入向量的存储和搜索、LLM的提示词生成、以及数据链路的处理(包括导入、分片和加工)等,如果这些环节都需要从头开发,将耗费大量的时间和资源。
- 缺乏标准化工具和组件也是一大挑战。为了能够根据不同场景灵活地组装和调整系统,我们需要的是一个像“乐高”一样的标准化组件库。
局限性分析
问题简介
多知识点聚合处理场景下,Embedding-Search 召回精度较低的问题。典型应用范式是:
- 一个仓库有 N 条记录,每个记录有 M 个属性;
- 用户希望对 x 条记录的y 个属性进行查询、对比、统计等处理。
这种场景在游戏攻略问答中很常见,以体育游戏 NBA2K Online2 为例:
# 多知识点——简单查询
Q: 皮蓬、英格利什和布兰德的身高、体重各是多少?
# 多知识点——筛选过滤
Q: 皮蓬、英格利什和布兰德谁的第一位置是 PF?
# 多知识点——求最值
Q: 皮蓬、英格利什和布兰德谁的金徽章数最多?
Embedding 缺陷
原始的 Embedding Search在面对多知识点聚合处理时,存在几个问题:
- 本地知识建立索引时,通常对单个知识点进行 Embedding;通畅不会为不同知识点的排列组合分别制作索引,所有组合都建立索引的开销是巨大的。
- 原始问题直接 Embedding ,和单条知识点的向量相似度比较低。为了避免召回结果有遗漏,就需要降低相似度评分下限(vector similarity score threshold),同时提高召回结果数量上限(top k)。这会产生不好的副效应:
- 召回结果,有效信息密度大幅降低;score threshold 过高或 top k 过低,会导致某些有效知识点无法命中;反之则很多无效知识点或噪声会被引入。且由于总 token 数量的限制,导致本地知识点被截断,遗漏相似度较低但有效的知识点。
- 召回结果的膨胀,增加了和 LLM 交互的 token 开销和 LLM 处理的时间复杂度。
- 给 LLM 的分析处理带来额外噪声,影响最终答案的正确性。
方案分析
想要更加精准的回答问题,需要从两个层面入手:
1. 问题理解—准确识别用户意图
为了准确理解用户的意图,问答系统需要能够:
- 解析用户问题:系统需要通过分析用户的提问来识别他们的意图。
- 制定计划:根据识别的意图,系统需要拆分问题为多个步骤,并为每个步骤选择合适的工具或方法。
- 多轮交互:使用Agents和Chains等工具,系统可以通过多轮对话来逐步明确用户的需求。
在LangChain框架中,Agents 可以帮助系统规划并执行这些步骤。例如,Plan-and-Execute Agents可以用来制定动作计划,而Action Agents则负责执行这些动作。
- HyDE。Precise Zero-Shot Dense Retrieval without Relevance Labels 是面向 Zero-Shot场景下的稠密检索。它使用基础模型在训练过程中已经掌握的相关语料,面向用户问题,生成虚构的文档。这些文档的作用,不是输出最终结果,而是通过LLM(大型语言模型)对问题的理解能力,生成与之相关的内容。这相当于自动化生成相关性标签,避免外部输入。生成虚构文档后,再使用无监督检索器进行Embedding;然后将生成的向量在本地知识库中进行相似性检索,寻找最终结果。
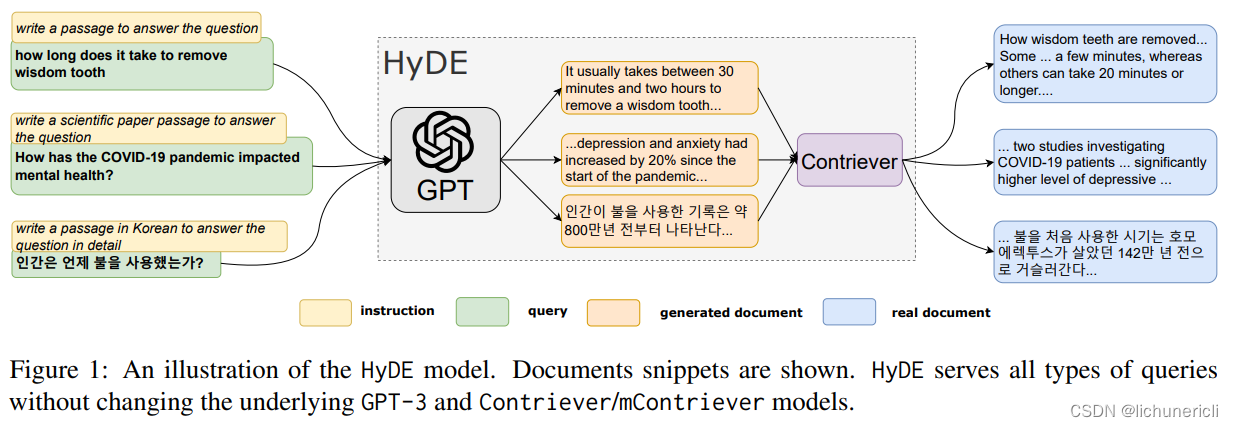
HyDE 要求与用户问题相关的知识,已经存在于 LLM 基础模型中。但专业领域知识,可能本来就是未联网、未公开的;LLM 生成的虚构文档,可能包含很多噪音,所以效果不一定很明显;另外生成文档的额外交互,进一步增加了时间开销。目前,LangChain 提供了 HyDE Chain,LlamaIndex 也提供了类似的能力;面对中文可能需要自定义 Prompt Template。
- 意图识别。通过 命名实体识别 和 槽位填充 实现。概括来说就是:
- 在为用户提供服务的预设场景下,细分用户各种意图的类别,定制对应的语义槽,每个槽位可以视为在语义层面体现意图的基本单位。
- 通过深度学习、统计学习,甚至 LLM ,理解用户问题提取语义槽中需要的内容。在基于大语言模型构建知识问答系统一文中给过例子:通过 System Role 告知LLM 需要提取槽位信息,让 LLM通过多轮对话引导用户给出所有槽位信息。还是以游戏攻略为例,玩家咨询球员的打法,那么必须提供:球员姓名,年代(比如2020/2022 年),比赛模式。对应的语义槽可以定义为:
"球员打法" : {
"球员名称" : ____,
"年代" : ____,
"比赛模式 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









