







在当今信息爆炸的时代,人们每天都要处理海量的数据和信息。在这样的背景下,基于知识库的问答系统(KBQA)成为了一个重要的研究领域,它旨在使计算机能够理解自然语言提出的问题,并从结构化的知识库中检索出准确的答案。然而,KBQA面临着一系列挑战,尤其是如何将复杂的自然语言问题转化为可在知识库上执行的查询,以及如何在资源受限的情况下实现高效的问答。
传统的KBQA方法,如基于信息检索(IR)的方法和基于语义解析(SP)的方法,虽然在某些场景下取得了一定的成果,但它们通常需要大量的标注数据来训练模型,这不仅成本高昂,而且限制了方法的可扩展性和适应性。并且这些方法在处理复杂的多跳问题时也常常力不从心。随着大型语言模型(LLMs)的出现,研究者们开始探索利用这些模型的少样本学习能力和推理能力来提升KBQA系统的性能。但是,如何充分利用LLMs的潜力,尤其是在低资源情境下,仍然是一个开放的问题。
本文针对上述挑战,提出了一种名为Interactive-KBQA的新型框架。该框架通过设计一种多轮交互式的方法,将LLMs的推理能力与知识库交互工具结合起来,以实现对复杂问题的深入理解和精确回答。Interactive-KBQA通过直接与知识库进行交互,生成逻辑形式和SPARQL查询,从而克服了传统方法的局限,并在低资源情况下展现出卓越的性能。通过对交互过程的精心设计,Interactive-KBQA不仅提高了答案的准确性,还增强了模型的可解释性和适应性,为KBQA领域的研究和应用开辟了新的道路。
方法
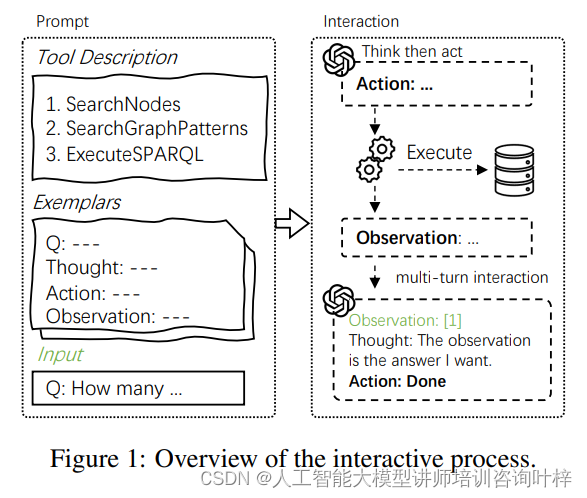
在Interactive-KBQA框架中,交互过程是实现知识库问答(KBQA)任务的核心机制。首先,用户提出一个问题,例如询问“有多少篮球运动员身高超过2米?”。这个问题将作为输入进入系统。LLM作为代理,首先需要进行“思考”(Thought),在这一阶段,LLM分析问题的语义,并决定需要执行的动作。例如,它可能需要搜索特定的实体或关系,或者构造一个SPARQL查询来从知识库中检索信息。
接下来是“行动”(Action)阶段,LLM根据思考的结果执行相应的操作。这可能包括调用SearchNodes工具来查找与问题相关的知识库节点,使用SearchGraphPatterns工具来识别关键的图模式谓词,或者执行一个SPARQL查询来直接从知识库中获取答案。
每个行动的执行都会产生“观察”(Observation)结果,这些结果反馈给LLM,为下一步的思考提供信息。例如,如果LLM执行了SearchNodes,它可能会观察到一系列与问题相关的实体列表。
随后,LLM再次进入“思考”阶段,根据新的观察结果调整其行动策略。这个过程是迭代的,LLM在每一轮中都会进行思考和行动,直到问题得到满意的解答。
为了引导LLM正确地进行思考和行动,研究者设计了一组示例(Exemplars),这些示例展示了如何将问题分解为子查询,并指导LLM如何使用不同的工具与知识库进行交互。
研究者还构建了“提示”(Prompt),这是一种包含工具描述、工具使用和交互格式的指导性文本,用于辅助LLM理解任务和执行交互。
当LLM执行“完成”(Done)动作时,最终的观察结果将作为问题的答案输出。整个过程是一个多轮的对话式交互,LLM通过连续的思考和行动,逐步深入理解问题并构建出正确的答案。
该研究首先定义了KBQA任务,即将自然语言问题转化为可在知识库上执行的SPARQL查询。知识库被形式化为一个包含实体、关系和类别的结构,研究的目标是生成一个与问题相对应的SPARQL表达式,这一过程可以视为条件概率模型 p(S∣Q,K) 的求解。
Interactive-KBQA框架将LLMs视为代理,知识库视为环境,通过直接与知识库的交互来引导LLMs进行语义解析和SPARQL生成。这种方法允许系统以对话的形式,逐步构建对问题的理解和回答。
为了实现与知识库的有效交互,研究者设计了三种工具:SearchNodes用于基于表面名称搜索实体;SearchGraphPatterns用于识别和排名与问题语义相关的图模式谓词;ExecuteSPARQL用于执行任意SPARQL查询。这些工具共同构成了交互逻辑的基础。
LLMs通过提示文本和交互历史生成动作。提示文本包括工具描述、使用说明和交互格式,而交互历史记录了整个对话过程中的思考、动作和观察结果。LLMs需要根据这些信息,决定下一步的行动,直至问题得到解答。
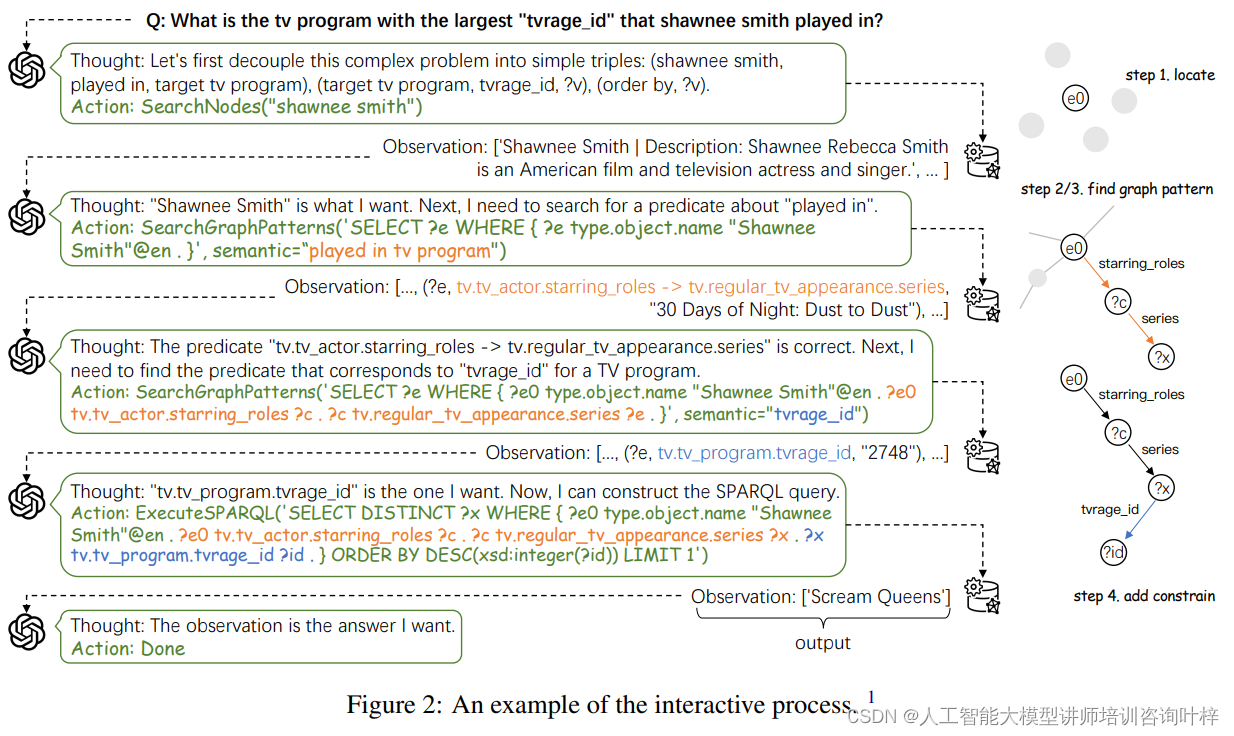
研究者通过为不同类型复杂问题设计交互模式和标注高质量的示例,指导LLMs进行推理。这种方法允许系统处理多跳问题、涉及复杂结构的问题,以及需要特定推理步骤的问题。
为了克服现有LLMs在输出错误时难以纠正的问题,以及现有KBQA数据集缺乏详细推理步骤的局限,研究者提出了一种人机协作注释策略。通过手动标注包含详细推理过程的样本,并使用这些样本对开源LLMs进行微调,研究者提高了模型在低资源环境下的性能。
实验
研究者们选取了多个广泛使用的KBQA数据集,包括WebQuestionsSP、ComplexWebQuestions、KQA Pro和MetaQA,这些数据集覆盖了基于Freebase、Wikidata和特定领域知识库的问题。为了构建测试数据集,研究者们采用均匀采样方法从每个数据集中抽取样本,并手动标注部分样本以形成低资源数据集,从而评估模型在资源受限情况下的性能。
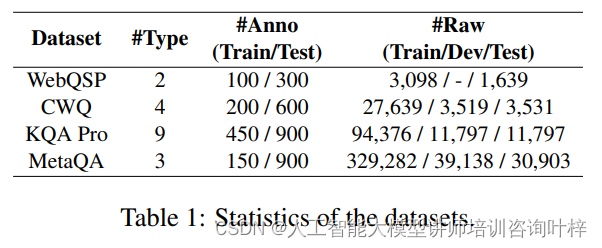
为了全面评估Interactive-KBQA的性能,研究者们选择了多种先前最优的基线模型,这些模型包括了基于语义解析的方法和基于提示的方法。采用了F1分数、Random Hits@1和Exact Match等评估指标来衡量模型的性能。对于KQA Pro数据集,还特别报告了准确率指标。
实验结果显示,Interactive-KBQA在CWQ和MetaQA数据集上的性能超越了基线模型,特别是在处理比较性和最高级问题类型时,取得了显著的性能提升。此外,在低资源情境下,通过微调开源LLMs,Interactive-KBQA在特定问题类型上的性能甚至超过了GPT-4 Turbo。
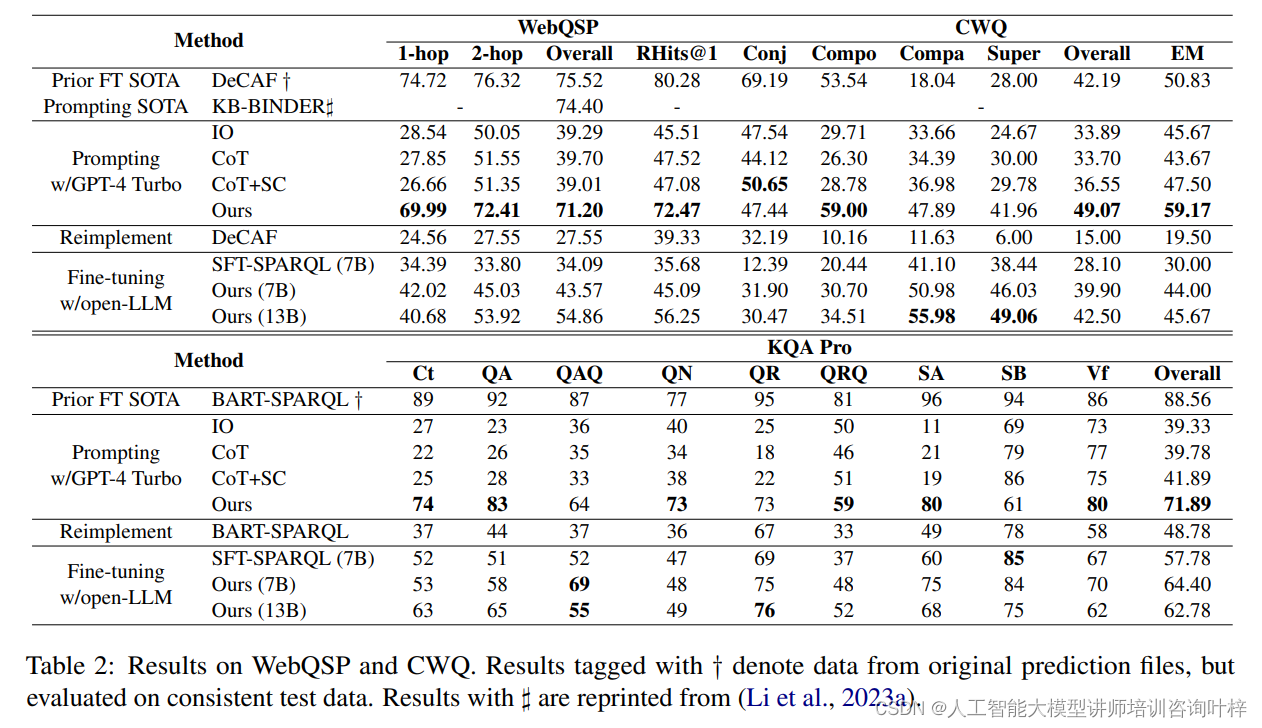
表2中,对于WebQSP数据集,尽管Interactive-KBQA在1-hop和2-hop问题上的表现略低于使用完整数据训练的先前最优方法,但在整体性能上显示出了竞争力。特别是在CWQ数据集上。
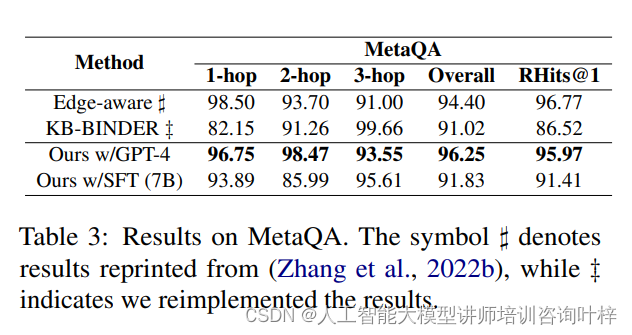
表3显示,Interactive-KBQA在所有问题类型上均优于基线模型,包括连接(Conjunction)、组合(Composition)、比较(Comparative)和最高级(Superlative)问题。特别是在比较性和最高级问题类型上,Interactive-KBQA实现了显著的性能提升,分别提高了29.85%和13.96%。
这些结果表明,Interactive-KBQA在处理复杂问题时的有效性,尤其是在资源受限的情况下,其性能优势更为明显。此外,通过使用少量示例进行微调的开源大型语言模型,Interactive-KBQA在低资源情境下的表现超越了商业化的LLMs,证明了其方法的实用性和可扩展性。
实体链接是KBQA中的一个关键步骤,研究者们评估了Interactive-KBQA在实体链接方面的表现,并引入了提及覆盖率(Mention Cover Rate, MCR)来量化实体链接的难度。实验结果指出,在KQA Pro和MetaQA数据集上,实体链接的表现对整体性能有显著影响。
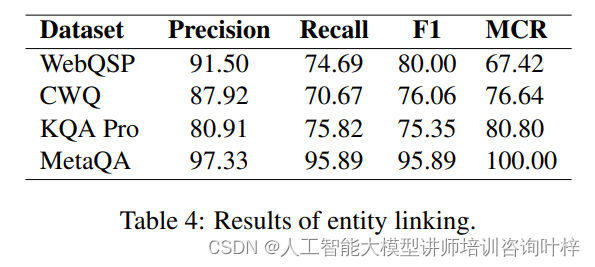
在消融研究中,研究者们通过减少或增加某些组件(如示例数量、不同类型的问题示例),来观察这些变化对模型整体性能的影响。问题类型分类器的作用是根据问题的语义特征将其分类到预定义的问题类型中,从而为LLM提供正确的交互策略和示例。
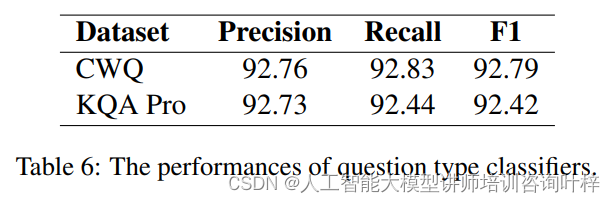
这些数据表明,分类器在识别1-hop问题时表现最佳,而在识别Conjunction类型的问题时表现相对较差。F1分数和准确率的高值表明分类器整体性能较好,但仍有改进空间,尤其是在处理某些特定类型的问题时。
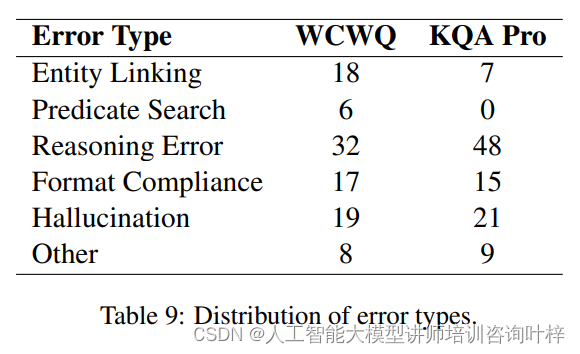
研究者们对Interactive-KBQA在实验中出现的错误类型进行了系统性分析,包括实体链接错误、谓词搜索错误、推理错误、格式合规性错误和幻觉错误等。通过案例研究,研究者们展示了在人类辅助下纠正这些错误的流程,这为进一步优化模型提供了见解。
Interactive-KBQA框架通过结合大型语言模型的推理能力和与知识库的多轮交互,有效地提高了KBQA系统的准确性和可解释性。通过少量示例学习和手动干预,该框架在资源受限的情况下展现出了卓越的性能,为知识库问答领域提供了一种新的研究方向和工具。
论文链接:https://arxiv.org/abs/2402.15131.pdf

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











