







人工智能咨询培训老师叶梓 转载标明出处
在人工智能领域,大模型(LLM)的泛化能力一直是研究的重点。最新的研究通过直接偏好优化(DPO)技术,显著提升了LLM在视频指令跟随等任务中的表现。然而,提供信息丰富的反馈以检测生成响应中的幻觉现象,仍然是一个重大挑战。
本文针对这一问题,提出了一种创新的解决方案,即通过直接偏好优化(DPO)技术对视频大型多模态模型(LMM)进行优化。本方法利用详细的视频字幕作为视频内容的代理,这不仅为语言模型提供了丰富的上下文信息,而且极大地增强了模型对视频问答(QA)预测的评分能力。这种方法的优势在于:
成本效益:相比于传统的基于人类偏好数据的收集方法,该方法大幅降低了成本,同时保持了高效的反馈系统。
可扩展性:通过使用语言模型生成的详细字幕,该方法能够处理更大规模的视频数据,而不受人类评估的局限。
鲁棒性:新框架在评估生成响应的事实上准确性方面表现出色,尤其是在检测幻觉现象方面,显著提高了模型的鲁棒性。
性能提升:实验结果表明,应用DPO方法后,视频LMM在视频QA任务上的性能得到了显著提升,确立了新的最先进性能基准。
方法
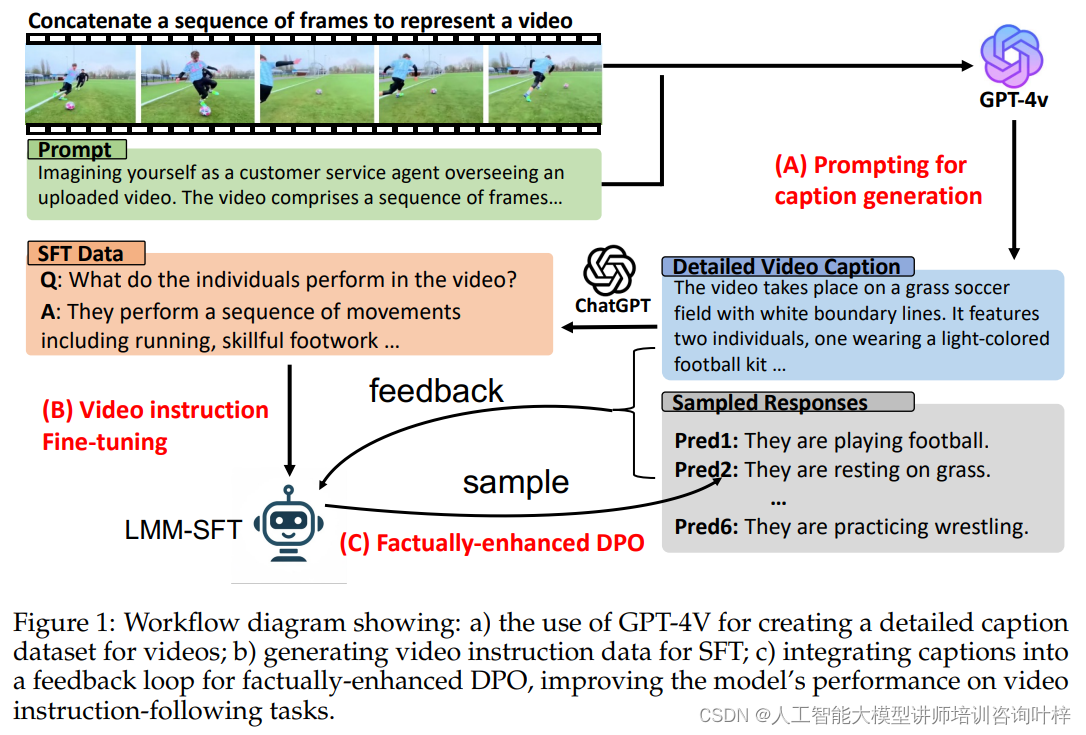
图1展示了研究者们提出的工作流程图,其中包括以下几个关键步骤:a) 使用GPT-4V创建详细的视频字幕数据集、b) 为SFT生成视频指令数据、c) 将字幕集成到反馈循环中以增强DPO
研究者们首先采用了GPT-4V模型来生成详细的视频字幕。这个过程包括从WebVid、VIDAL和ActivityNet等数据集中选取视频,并从中均匀提取十帧作为视频内容的代表。这些帧序列被用作GPT-4V模型的输入,以生成与视频内容相匹配的连贯字幕。研究者们精心设计了提示(prompt),以确保字幕能够全面反映视频内容,包括时间动态、世界知识、物体属性、空间关系等要素。
接下来,研究者们利用从详细视频字幕中生成的视频指令数据进行监督式微调(SFT)。他们从ActivityNet、WebVid和VIDAL数据集中随机抽取一定数量的字幕,并使用ChatGPT基于这些详细视频字幕生成问题-答案对。这一步骤确保了指令数据与视频内容的事实一致性,并且为模型的微调提供了丰富的训练材料。

最后,研究者们提出了一种成本效益高的方法,通过DPO使用语言模型的反馈作为奖励。这种方法避免了直接使用GPT-4V进行奖励蒸馏的高成本和低效率。研究者们首先从SFT阶段的指令对中随机选择一部分,然后使用SFT模型生成多个响应。接着,他们利用ChatGPT处理包括问题、真实答案、模型预测和详细描述的输入,生成包括自然语言解释和数值奖励分数的输出。这个分数反映了预测答案的事实对齐程度和整体质量。
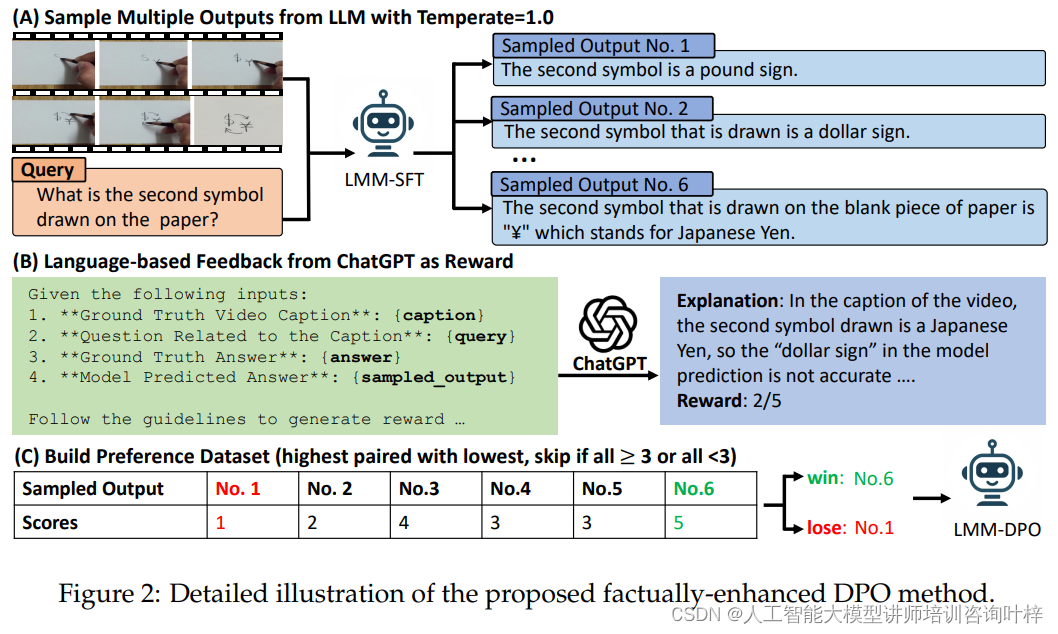
图2提供了所提出的基于事实增强的直接偏好优化(DPO)方法的详细说明。这个流程图包括以下几个关键组成部分:
-
多模型输出采样:使用大型语言模型(LLM)以一定温度参数(例如1.0)采样多个输出响应,这些响应是针对给定的视频和问题对生成的。
-
使用GPT-4V生成详细字幕数据集:GPT-4V模型接收视频帧序列作为输入,并生成详细的字幕,这些字幕捕捉了视频中的关键信息和事件。
-
生成SFT视频指令数据:利用详细的视频字幕,通过类似的方法生成视频指令数据,这些数据随后用于监督式微调(SFT)。
-
基于语言模型反馈的DPO:在DPO阶段,使用ChatGPT处理包括问题、真实答案、模型预测和详细字幕的输入。ChatGPT根据这些信息生成自然语言解释和奖励分数,这些解释和分数作为模型预测的事实对齐和质量的度量。
-
构建偏好数据集:根据ChatGPT提供的分数,选择高分数的响应作为正面例子,低分数的响应作为负面例子,构建用于DPO训练的偏好数据集。
-
DPO目标定义:定义DPO的目标函数,该函数使用偏好数据集中的正面和负面例子来优化策略模型,使其生成更受偏好的响应。
-
评估和奖励分配:评估者使用图15中的提示对模型预测的答案进行评估,考虑相关性、准确性、清晰度和完整性,并给出一个1到5的分数。
-
DPO训练:使用上述生成的奖励数据,通过DPO方法训练策略模型,使其学习生成更准确、相关且高质量的答案。
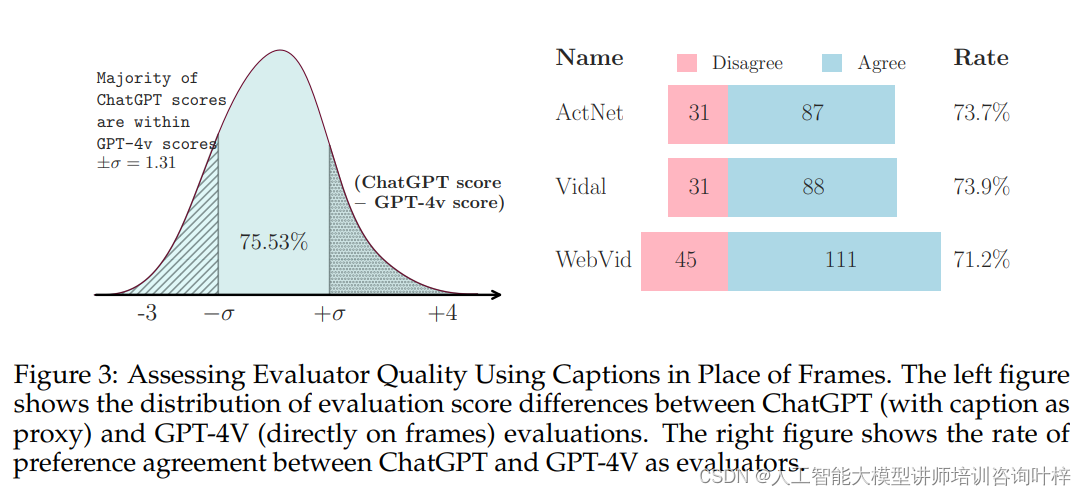
为了评估所提出的奖励分配方法的有效性,进行了与GPT-4V的比较分析。他们将这种方法与GPT-4V直接基于视频帧的评估系统进行了对比。研究团队从不同的视频数据集中抽取了样本,并为每个样本生成了问题和模型预测答案。使用GPT-4V对这些答案进行评分,结果显示,基于字幕的评估与GPT-4V的评分存在中等程度的正相关性,表明通过字幕代理的评估方法能够可靠地反映视频内容的理解。
大多数ChatGPT给出的评分都落在GPT-4V评分的一个标准差范围内,这进一步证明了使用字幕作为代理进行评估的适用性。这项评估不仅支持了研究者们的方法,而且为未来可能的改进提供了有价值的见解,例如通过引入更精细的评分系统或利用更先进的模型来提高评估的准确性。
实验
研究者们采用了Video-LLaVA作为视频LMM的骨干网络。这个模型使用了LanguageBind编码器来处理图像和视频帧输入,并通过一个MLP投影器将视觉嵌入映射到文本空间,最后使用Vicuna作为大型语言模型。在训练过程中,他们首先使用来自ALLaVA的650k图像字幕数据和他们自己蒸馏的900k视频字幕进行字幕预训练。在这个阶段,他们冻结了LanguageBind视觉编码器,并微调了MLP投影器和LLM。接下来,他们使用图像和视频领域的指令数据对模型进行微调,以提高其遵循指令的能力。在DPO训练阶段,他们使用了17k偏好数据进行训练。
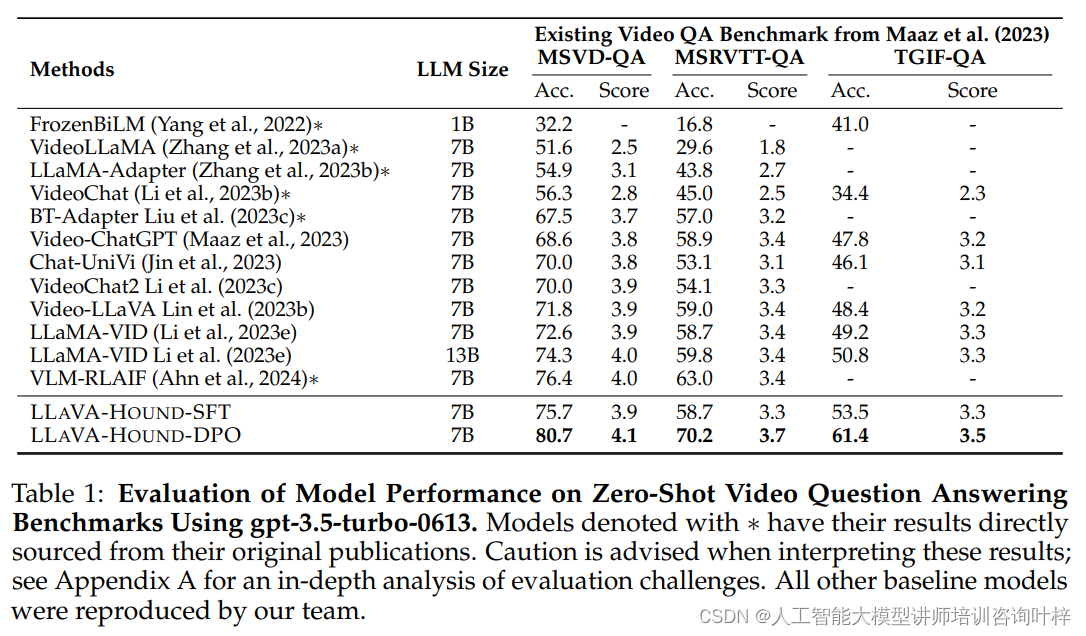
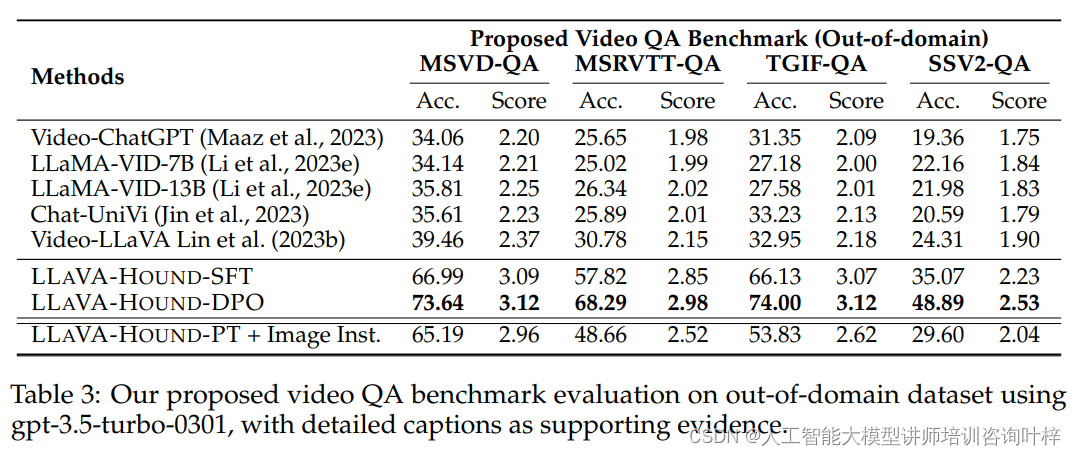
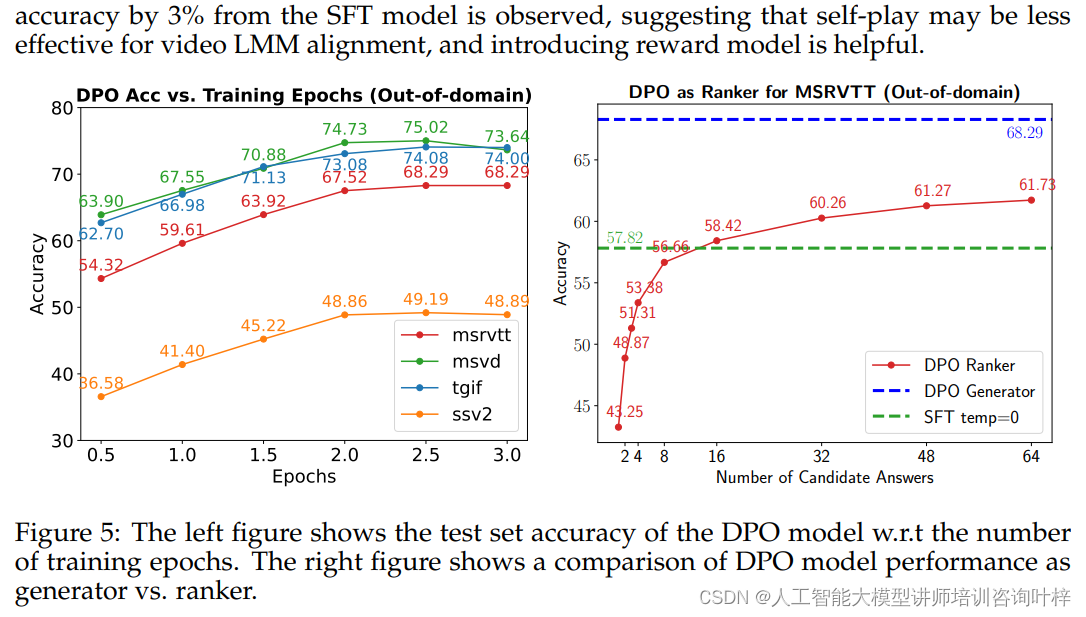
研究者们在MSVD-QA、MSRVTT-QA和TGIF-QA等三个基准数据集上评估了模型的性能。他们使用特定版本的ChatGPT来评估模型预测,并发现不同版本的ChatGPT对评估指标的绝对分数有显著影响,但模型的相对排名相对稳定。他们选择了一个特定的ChatGPT版本进行评估,并在实验中发现,与其他基线模型相比,他们的LLAVA-HOUND-DPO模型在视频QA任务上取得了显著的性能提升。

为了克服现有基准评估的局限性,研究者们提出了一种新的评估方法,该方法使用GPT-4V生成的详细字幕作为支持证据。他们为基准数据集中的相同视频生成了新的问答对,并应用了前面提出的奖励系统。这种新的长形式QA评估能够更全面地支持评估响应的相关性、准确性、清晰度和完整性。

研究者们还分析了预训练对视频字幕生成能力的影响。他们展示了模型在不同数据集上的表现,涵盖了总共900k的蒸馏数据实例。使用GPT-4V进行自评估,作为性能的上限,而Video-LLaVA模型则作为比较分析的基线。结果表明,使用更多的蒸馏数据可以显著提高模型在领域内和跨领域数据集上的性能。尽管如此,与GPT-4V模型相比,仍存在一定的性能差距。
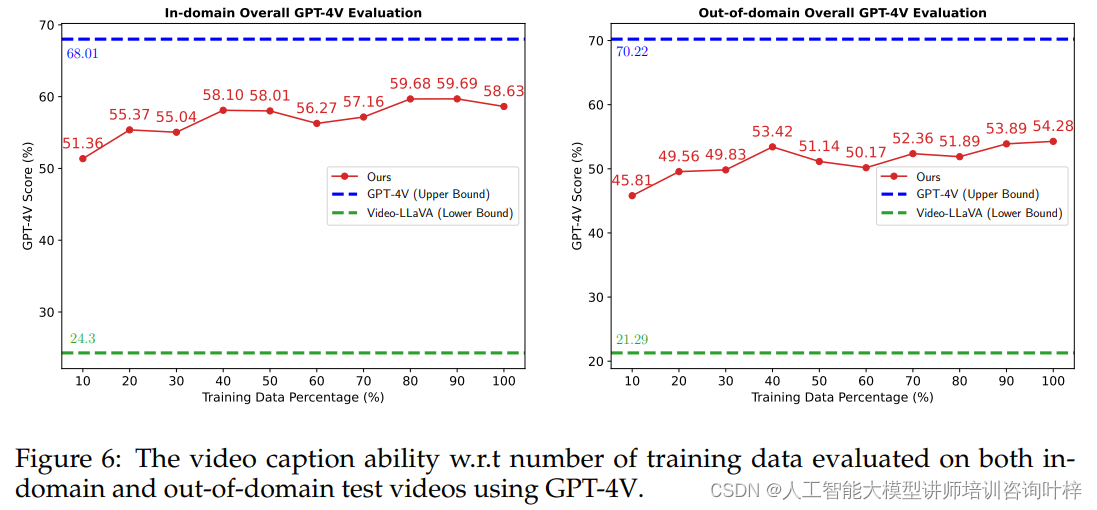
研究者们还评估了特定数据子集的泛化潜力,揭示了不同类型数据集在训练时面临的不同泛化挑战。例如,WebVid子集侧重于相对静态场景,需要较少的数据即可有效训练,而VIDAL子集则以动态场景转换和多样化的视频主题为特点,可能需要更多的数据来实现有效的训练。
本研究不仅展示了预训练对提升视频字幕生成能力的重要性,而且还突显了在多样化数据集上进行训练的必要性。随着人工智能技术的不断进步,本研究的发现不仅为视频理解和多模态交互领域提供了宝贵的见解,也为未来的研究和模型开发奠定了坚实的基础。
论文链接:https://arxiv.org/abs/2404.01258
GitHub 地址:https://github.com/RifleZhang/LLaVA-Hound-DPO




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











