







在当今信息爆炸的时代,如何高效地从海量文本中检索出最相关的信息,是自然语言处理领域面临的一项重大挑战。传统的文本嵌入技术虽然在一定程度上实现了语义的向量化表达,但它们往往受限于训练数据的质量和规模,难以捕捉到语言的丰富性和多样性。为了适应不同的下游任务,研究者们不得不构建特定于任务的嵌入模型,这不仅增加了工作量,也限制了模型的通用性和灵活性。
谷歌团队新提出的Gecko模型,正是为了突破这些限制,提出了一种全新的解决方案。Gecko模型的核心优势在于其能够从大型语言模型(LLMs)中提取和蒸馏知识,这些大型模型拥有庞大的参数量和卓越的少样本学习能力,它们在广泛的领域内积累了深厚的知识。通过创造性地利用这些已有的大型语言模型,Gecko模型不仅能够生成丰富多样的合成训练数据,还能够通过精细的重标记过程,识别出对于特定查询最相关的正面和负面文本样本。
这种从LLMs中提取知识的方法,使得Gecko在保持模型紧凑性的同时,实现了强大的检索性能。在Massive Text Embedding Benchmark(MTEB)上的实验结果表明,即使是具有256维嵌入向量的Gecko模型,也能超越其他具有768维嵌入向量甚至更高维度的模型。最亮眼的是768维的Gecko模型在多个任务上的平均表现,与比其大7倍的模型相媲美,充分证明了Gecko在文本嵌入领域的突破性进展。
什么是文本嵌入模型?
文本嵌入模型是自然语言处理(NLP)中的基石,它们将文本输入转换为固定大小的向量,使得语义相似的文本在向量空间中彼此接近。这些嵌入模型广泛应用于多种NLP任务,如语义相似性度量、文档检索、聚类和分类等。早期的嵌入模型,例如Word2Vec和GloVe,主要关注于词或短语的嵌入。随着技术的发展,像SBERT和Universal Sentence Encoder这样的模型开始提供更通用的文本嵌入,以支持广泛的下游任务。然而,这些模型在跨任务和跨领域的泛化能力上仍面临挑战。
对比学习是提高文本嵌入质量的一种有效方法,它通过区分正样本和负样本来学习更好的文本表示。在文本嵌入的上下文中,正样本通常是语义上相似的文本对,而负样本则是语义上不相似的文本对。找到合适的负样本尤其重要,因为它可以帮助模型更好地学习区分不同文本的能力。一些工作通过使用信心分数来筛选硬负样本,而其他方法则利用交叉注意力机制来重新排序和选择负样本,从而提高嵌入的质量和性能。
Gecko模型介绍
在将文本嵌入模型应用于新任务和领域时,经常会遇到缺乏足够标注数据的问题。为了解决这一问题,一些研究提出了利用大型语言模型(LLMs)生成合成查询的方法。这些方法通过少量示例提示(few-shot prompting)LLMs来创建特定领域的训练数据集,从而在零样本(zero-shot)或少样本(few-shot)的情况下提高模型在新任务上的表现。这种方法已被证明在信息检索基准测试中非常成功。
Gecko模型的提出,正是在这些现有工作的基础上,进一步探索如何通过知识蒸馏从大型语言模型中提取知识,并利用合成数据生成技术来创建高质量的训练样本。Gecko模型的核心创新在于利用大型语言模型(LLMs)中的知识,通过一个两步蒸馏过程来提升文本嵌入的性能。首先,使用LLM生成多样化的合成配对数据;然后通过检索每个查询的候选段落集,并使用相同的LLM重新标记正面和硬负面段落,进一步提高数据质量。
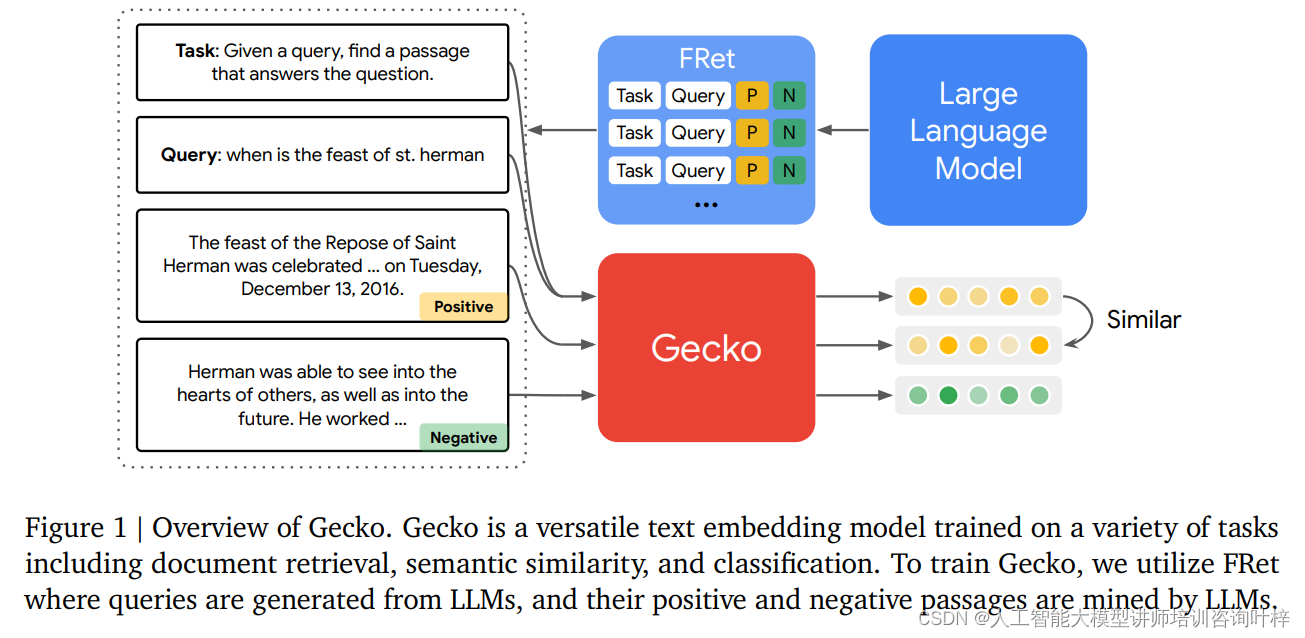
图1提供了对Gecko模型的全面概述,展示了其作为一个多功能文本嵌入模型的核心特点和训练过程。Gecko模型能够处理包括文档检索、语义相似性比较和分类在内的多种任务。这一模型的关键在于其训练方法,即利用大型语言模型(LLMs)生成查询,并通过同样的LLMs挖掘正面和负面的文本段落。
多功能性: Gecko模型的多功能性体现在其能够适应不同的NLP任务,这使得它不需要针对特定任务进行重新训练或调整。这种灵活性是通过在训练过程中使用多样化的数据和任务类型来实现的。
训练过程: Gecko的训练过程依赖于FRet数据集,这是一个通过LLMs生成的合成数据集。在这一过程中,首先使用LLMs来生成与给定文本相关的查询。然后,利用LLMs的推理能力来从大量文本中检索出与每个查询最相关的正面段落,以及用于对比学习的负面段落。
LLMs的作用: LLMs在Gecko模型中扮演了至关重要的角色。它们不仅用于生成任务和查询,还用于评估检索到的文本段落的相关性,从而选择最有力的正面和负面样本。这一步骤对于提高模型的泛化能力和检索性能至关重要。
FRet数据集: FRet数据集是Gecko训练方法的核心组成部分。它由LLMs生成,包含了丰富的任务类型和查询,以及对应的正面和负面文本段落。这种数据集的设计使得Gecko能够在没有大量标注数据的情况下进行有效的训练。
训练优势: 通过使用LLMs和FRet数据集,Gecko模型的训练方法具有显著的优势。它不仅能够减少对大规模标注数据集的依赖,还能够提高模型在多种任务上的性能和泛化能力。
Gecko模型的训练过程基于一个具有1.2亿参数的预训练变换器语言模型,并通过两个关键的额外训练阶段来进一步提升模型性能:预微调和微调。这两个阶段的目的是在保持模型紧凑性的同时,实现对多样化下游任务的强有力支持。
预微调使用大量未标记的文本数据来增强模型的语言理解能力。在这个阶段,Gecko利用了两种类型的数据集:大规模的社区问答对和从互联网上爬取的标题-正文对。这些数据对的多样性帮助模型学习到了广泛的语言模式和结构。预微调的目标是让模型在处理各种文本对时能够捕捉到它们之间的细微差别,为后续的微调阶段打下坚实的基础。
在预微调过程中,模型通过对比学习目标来优化。具体来说,模型学习将相关的文本对拉近,同时将不相关的文本对推远。这种方法不依赖于硬负样本,而是通过在每个小批量中使用负样本来提升模型的区分能力。通过这种方式,模型能够更好地理解文本之间的相似性和差异性。
FRet数据集的生成是Gecko训练方法的核心创新点。这个过程通过两步LLM蒸馏来生成高质量的合成数据,用于训练多任务文本嵌入模型。
第一步是利用LLM生成多样化的查询。LLM被引导阅读网络语料库中的样本,并生成与这些样本相关的任务描述和查询。这种方法允许模型探索不同的任务类型和语言风格,从而生成多样化的查询。
第二步是正面和负面样本的挖掘。在生成查询之后,使用预训练的嵌入模型来检索与查询最相关的文档。然后,LLM再次被用来对这些文档进行排名,以识别最相关的正面样本和具有挑战性的硬负面样本。这一步骤至关重要,因为它确保了训练数据的质量和相关性。

在微调阶段,FRet数据集与人类标注的数据集相结合,形成了一个统一的微调数据集。这个数据集包含了任务描述、输入查询、正面段落和负面段落,它们以统一的格式进行编码,使得模型能够在多种任务上进行微调。
微调的目标是进一步优化模型,使其能够区分正面样本和硬负面样本。通过使用标准的损失函数,模型学习在各种任务上进行有效的文本嵌入。此外,为了支持不同维度的嵌入,Gecko还采用了多维度表示学习(MRL)损失函数来优化子空间的表示。
通过这种综合的训练方法,Gecko模型不仅能够学习到丰富的语言知识,还能够在多种NLP任务上展现出卓越的性能。这种结合了预训练、预微调和微调的多阶段训练策略,为构建高效、通用的文本嵌入模型提供了一个强有力的框架。
实验
研究者们主要在Massive Text Embedding Benchmark(MTEB)上对Gecko模型进行了评估,这是一个包含56个数据集的广泛基准测试,涵盖了检索、语义文本相似性(STS)、聚类、分类、成对分类、重排和摘要等任务。Gecko模型在所有这些任务上的表现都显著超越了具有相似尺寸和参数量的基线模型。特别是,256维的Gecko模型在性能上超越了OpenAI的text-embedding-3-large-256模型,以及其他几个知名的嵌入模型。而768维的Gecko模型甚至能够与比其大7倍的模型相媲美或超越它们。

除了在MTEB上的表现,研究者们还训练了一个多语言版本的Gecko模型,并在多语言信息检索(MIRACL)数据集上进行了评估。尽管FRet数据集仅以英文提供,但多语言Gecko模型在18种不同语言的检索任务上表现出色,优于其他基线模型。这表明,即使仅使用英文数据进行训练,Gecko模型也能够很好地迁移到其他语言任务中。

在分析部分,研究者们深入探讨了Gecko模型的不同组件以及它们对性能的贡献。他们测试了不同的正面和硬负面样本选择策略,发现使用LLM选择的最相关段落作为正面样本总是优于使用原始生成查询的段落。
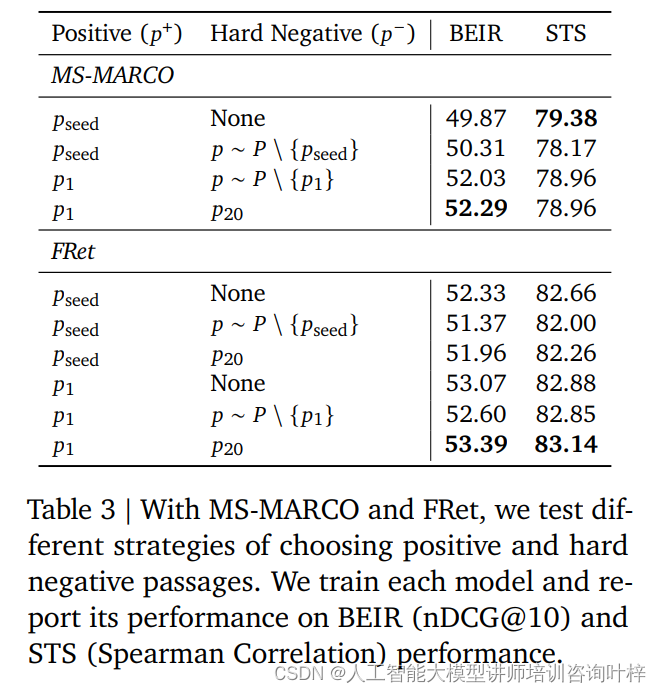
研究者们还探讨了FRet数据集的多样性对模型泛化能力的影响,发现在不同任务上均匀采样的FRet数据能够提高模型在MTEB上的整体性能。

研究者们还展示了Gecko模型如何通过使用对称格式和相同的塔负样本来更好地学习语义相似性。结合自然语言推理(NLI)数据集,Gecko模型在STS任务上的性能平均提高了1.6。此外,通过结合分类数据集,Gecko在分类任务上的性能也得到了显著提升,同时在其他任务上的性能并未显著下降。
最后研究者们通过一些具体的例子来展示LLM重标记的优势。他们提供了原始种子段落、生成的任务和查询,以及LLM挖掘的正面和负面段落。这些例子显示了LLM在生成多样化任务和查询方面的能力,以及它在为生成的查询找到更直接和相关答案方面的优势。

通过这些实验,研究者们不仅证明了Gecko模型在多种文本嵌入任务上的卓越性能,还展示了LLM在数据生成和模型训练中的潜力。这些结果为未来文本嵌入技术的发展提供了有价值的见解和方向。
论文链接:https://arxiv.org/abs/2403.20327

















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











