








目标网站
import re
import requests
from bs4 import BeautifulSoup导库
res = requests.get('https://pubmed.ncbi.nlm.nih.gov/34311758/')
print(res.status_code)向目标网页发送请求
string = res.text
soup = BeautifulSoup(string,'html.parser')利用BS库对网页进行解析,得到解析对象soup
li_list = soup.find('div', class_='abstract-content selected').find_all('p')定位<p>标签,得到的结果:
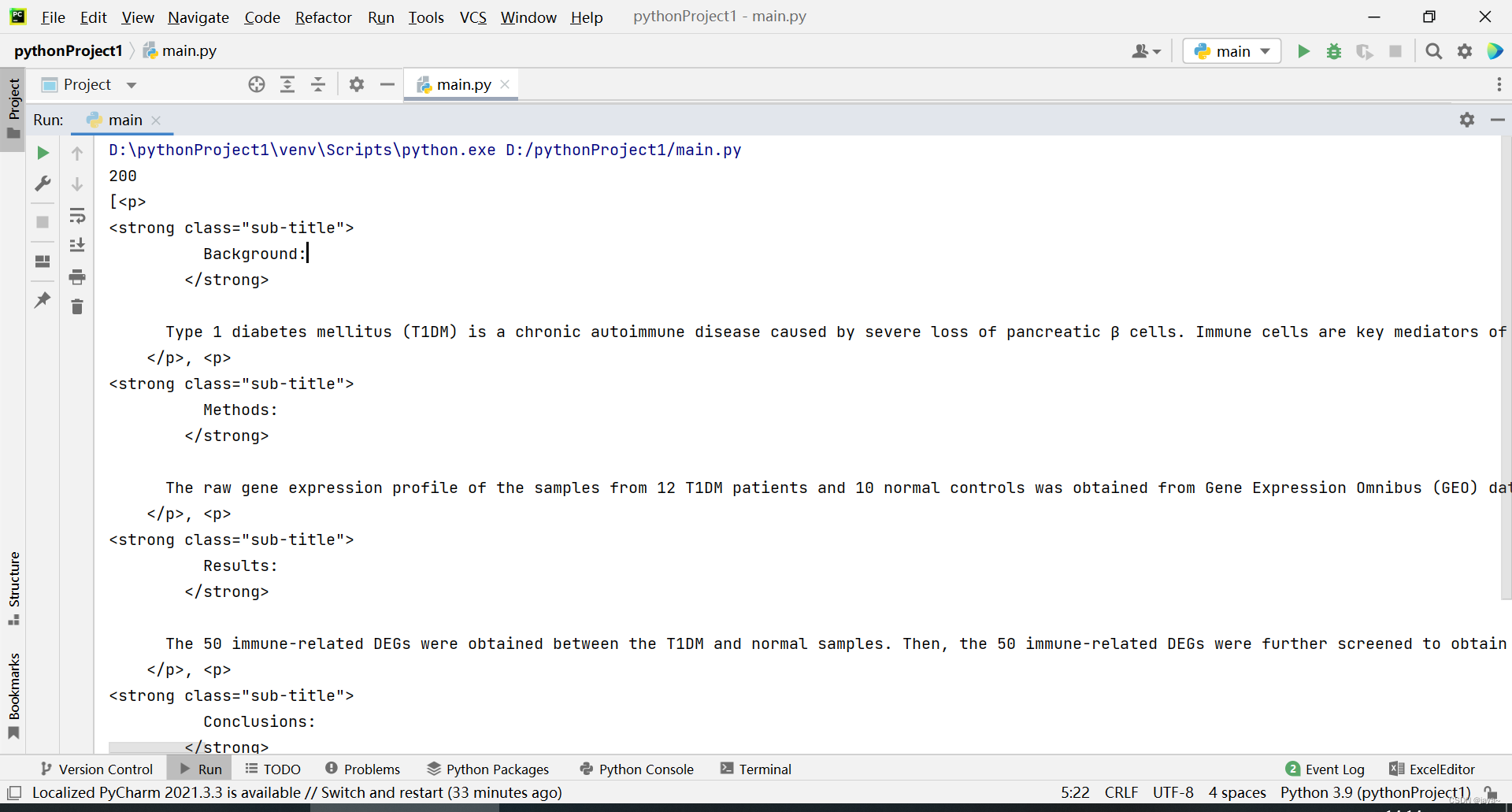
#预处理解析结果
li_list_Process = []
for i in li_list:
#print(type(str(i)))
i = str(i).replace('\n','')
i = re.findall(r'<\/strong&g 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









