






| 论文名称 | Horus:用于云数据中心的细粒度网络任务调度 |
| 作者 | Parham Yassini ...SFU 西蒙菲莎大学(Simon Fraser University) |
| 状态 | 待开始 阅读中 已读完 |
| 简介 | 背景:交互式数据中心应用程序中,短期任务很普遍。 存在问题/困难:设计调度器将任务分配给整个数据中心的工作人员,满足us级决策时延、高吞吐量、最小化尾部响应时间。 目前相关工作实现:仅在单个Rack内,实现低时延任务调度。 Horus:一个In-network的任务调度器,用于在数据中心规模上的短任务调度。 效果:Horus与可编程交换机上实现上的最先进的网络调度器比较,使用27K台主机和数千台交换机的数据中心模拟各种动态负载。Horus可扩展到大型数据中心、尾部响应时间、吞吐量性能优异。 |
背景
应用需求:大型应用程序(键值存储、多媒体应用、分布式交互分析、网络功能虚拟化、web搜索)采用微服务模式、功能即服务模式,增强多核可用性、降低部署成本。
做法:对数据中心计算资源做精细化管理——“颗粒计算范式”
举个例子:应用程序被分为大量短期任务,任务可以在跨多个服务器Rack的100-1000个核心上运行。单个任务响应时间10-100us之间。根据“木桶效应”,应用程序的性能受到最慢的任务的影响。因此,“颗粒计算”最小化尾部响应时间。并且,随着并发用户数量及其应用需求的增长,要求高调度吞吐量。
如何管理应用程序和计算资源?
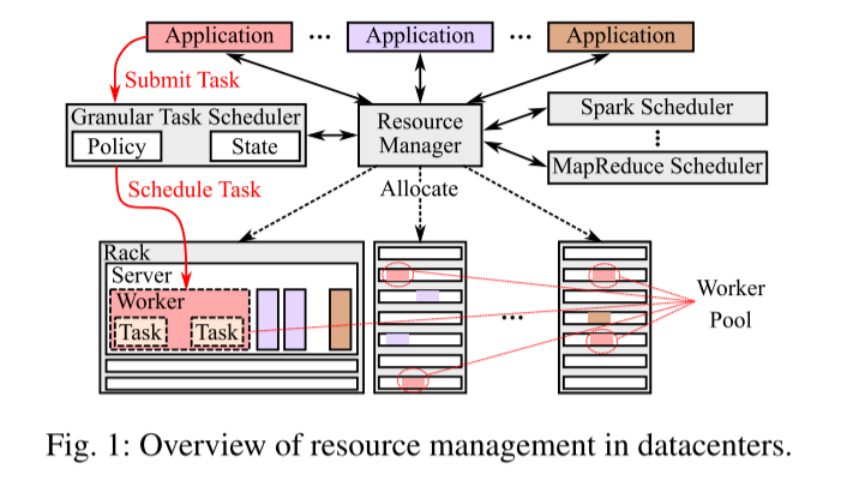
资源管理器:负责根据应用程序所需的容错级别和性能,为其分配一个工作池。
工作池:用于存储应用程序提交的任务,包括任务处理所需的各种资源。
任务调度程序:负责将任务从工作池分配给工作线程。
本文Horus:针对延迟敏感型应用程序设计的细粒度任务调度程序。
相关工作对比
将任务分配给worker执行的相关工作
| 服务器内调度器 | Shinjuku [43] 、ZygOS [64] | 支持us级任务 | 任务调度器仅限单个服务器 |
| 使用负载平衡器、服务器调度器,扩展到单个服务器之外 | Zhu et al. [78] RackSched | 支持Rack机架级 | 长尾响应时间。因为负载均衡器采用对数据包中的各种字段散列,进行决策。 |
| 跨Rack | Facebook调查时延敏感的流量,大多不是Rack本地的; 公共数据中心,避免资源不可用、提高容错性,租户将vm放置在不同的Rack内。 | 容错性、可用性 | 负载平衡器对工作线程的当前队列长度不敏感,还会受到执行时间多样性的影响。 |
只能调度单Rack内的任务:
[48] Ibrahim Kettaneh, Sreeharsha Udayashankar, Ashraf Abdel-hadi, Robin Grosman, and Samer Al-Kiswany. Falcon: Low latency, network-accelerated scheduling. In Proc. ofEuroP4’20, pages 7–12, Barcelona, Spain, December 2020.
[50] Marios Kogias, George Prekas, Adrien Ghosn, Jonas Fietz, and Edouard Bugnion. R2p2: Making rpcs first-class datacenter citizens. In Proc. ofUSENIX ATC’19, pages 863–880, Renton, WA, July 2019.
[78] Hang Zhu, Kostis Kaffes, Zixu Chen, Zhenming Liu, Christos Kozyrakis, Ion Stoica, and Xin Jin. Racksched: A microsecond-scale scheduler for rack-scale computers. In Proc. ofUSENIX OSDI’20, pages 1225–1240,November 2020.
Horus 第一个datacenter-wide in-network 调度系统的工作。
Horus工作包括两个部分:
1.Assign tasks to worker.
2.Track、Aggregate、Maintain the load on workers.
这两项工作在交换机完成,并且独立优化,目标实现高效的粒度任务调度。
前期工作
RS-LB(RackSched with datacenter Load Balance)
JSQ(Join Shortest Queue)全局版。JSQ跟踪每个服务器上的队列长度,将任务调度到队列最短的服务器上。
场景:任务执行时间分布,指数和双峰分布。
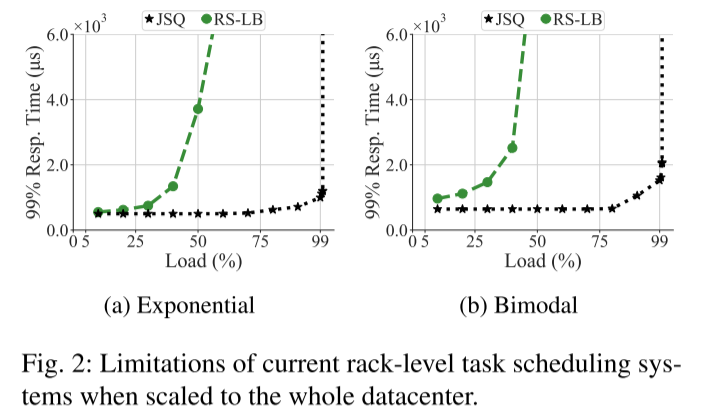
尽管JSQ理论上达到最佳效果,但是不可能实现在大规模数据中心,特别是时延敏感的任务中。
1.JSQ需要全局服务器上的队列长度。探测服务器(>=1RTT)、等待服务器发送更新(异步到达延迟/聚合延迟)。因此,在确定最小负载服务器时,实际服务器负载情况已经发生了变化。
2.一旦报告最小负载服务器,调度器可能会继续向其发送任务,直到服务器发送更新。会造成较长的响应时间。
3.特别对时延敏感的任务,任务执行时间相比,更新时间更久。会造成下次更新之前,已经将太多任务发送到服务器,导致负载不平衡。
4.实现JSQ需要数据中心规模的大量计算资源。
Horus设计
1.设计原则
P1负载感知调度。zero-queue 调度系统,有效跟踪worker负载,最小化尾部响应延迟,避免任务聚集。zero-queue实现不在交换机中缓冲任务,内存需求独立于任务速率,有助于Horus扩展。
P2惰性状态更新。根据维护状态,进行调度决策。可以用当前状态,进行决策。更新状态条件:计算实际负载值、调度程序中可用的负载信息之间的drift,并且当drift会对调度质量产生影响时,才会更新状态。
P3本地化状态。Horus对分布式调度器逻辑分组(会不会以Rack为一组呢?),在每组中维护状态。
2.Horus总览和工作流
Horus由一组调度器、一个集中控制器、每台服务器一个代理和APIs。
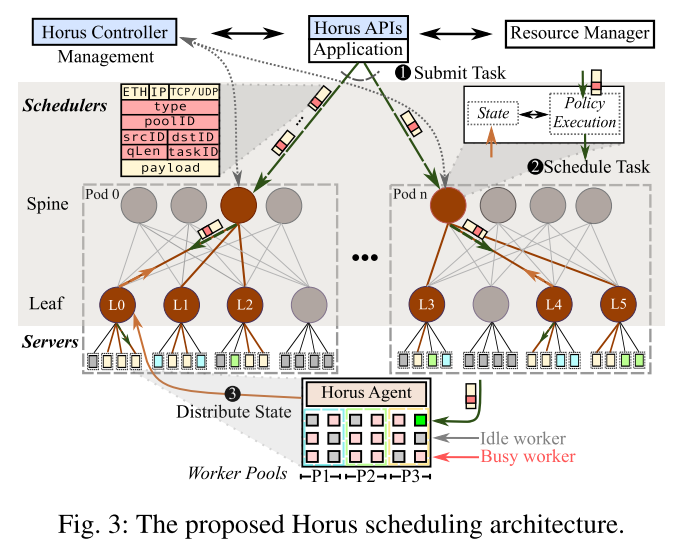
Scheduler调度器分为两部分:第一部分,维护和聚合worker的load信息。第二部分,使用维护的信息执行调度策略,将任务分配给worker。
调度器作为数据平面程序,在spine和leaf交换机上运行。core交换机上没有调度程序。
流程:leaf调度器,跟踪并使用他们Rack内的worker的load信息(P1)。leaf调度器聚合并有效的发送这些load信息给spine调度器(P2)。
Controller控制器的工作:
1.与资源管理器交互,检索每个应用程序的worker的位置。
2.为每个调度器分配固定的ID。
3.为每个Rack分配一个leaf shceduler,将每个leaf scheduler分配一个spine scheduler。
4.Horus将每个组与Pod对齐(其中一个Pod具有32-64个Rack)。
Worker state由每个pod的本地化、维持。
Horus Agent:运行在服务器上的轻量级进程,用于跟踪工作负载。不参与调度决策。
Horus APIs:为了使Horus与各种路由协议兼容,Horus在报文上附加了一个第4层头,头包含每个任务唯一的ID taskID。
Horus Workflow:
1.任务以递归的方式被调度。当任务提交执行时,数据包被随机转发给该应用程序的一个spine scheduler中。Spine scheduler的随机选择,是与每个pod的worker数量成比例。
2.spine scheduler负责选择下游leaf scheduler来处理任务,leaf scheduler将任务分配给Rack上的worker。
3.工作线程完成任务后,运行在该工作线程上的agent将最新的加载信息,包含在应答包的头部中,并发送给Rack的leaf scheduler。leaf scheduler收到应答包后,更新内存中的负载信息,如果需要进一步更新,leaf scheduler聚合状态更新,向上游的spine scheduler 发送更新消息。
3.调度网络任务
Switch Model:
(1)原子内存更新。允许数据包在每个阶段最多访问一个内存位置。
(2)有界数据包延迟。限制处理阶段的数据包数量。
数据包在交换机内各个阶段的可用处理和内存资源有限。
Proposed Scheduling Policy:spine和leaf scheduler使用相同的调度策略,并且维护相同的数据结构。调度策略的抽象:调度程序将到达的任务,分配给较低层节点。spine scheduler的节点就是Rack,leaf scheduler的节点是worker。优化调度任务:就是需要知道下游节点的负载,并将任务分配给负载最少的节点,实现了类似JSQ策略。但是,前面也提到JSQ难以在数据中心大规模实现。
理解:Horus是JSQ在数据中心规模的实际部署版本。
实际部署的限制:工作负载的动态特性、可编程交换机的限制。针对可编程交换机原子内存更新(运允许数据包在每个阶段最多访问一个内存位置),有界数据包延迟(限制了处理阶段的数据包数量)重新规划了新的数据结构(解决办法),不断探索可编程交换机的功能上限。
(1)当有一些空闲节点可用时。
spine scheduler把任务发送给leaf scheduler,leaf scheduler再找到空闲工作线程的worker。
最大的难点:如何大规模跟踪空闲节点,并用一种在可编程交换机上实现的方式。
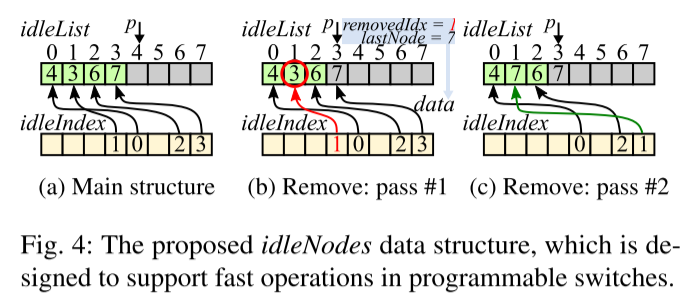
如何跟踪空闲节点,收到空闲节点的idleAdd消息时,如何将节点添加到idleNodes中?
1.增加空闲节点:调度程序将空闲节点n的ID写入idleList[p]中,将p写入idleIndex[n]。当前可编程交换机支持在单个阶段的原子read-modify-write操作。意味着调度程序,可以在一个阶段中,读取当前的p,增加p,并将p重新写回。
2.删除空闲节点:leaf scheduler 减小p,并清除idleList[p-1]。【为了确保保持所有空闲节点连续放在List顶部的不变性。保证spine scheduler的数据结构的操作和leaf scheduler保持一致。】spine scheduler只有在收到leaf scheduler传来的idleRemove消息,才会删除Node。
3.如何实现删除任意位置的node,同时保持空闲节点连续放置在列表项顶部(内存空间连续性)。由于可编程交换机不允许数据包在同一个pass中多次访问相同的内存位置。因此,采用两个pass完成。
pass1(Fig4.b)调度器检查idleIndex,获得idleList中n的索引值(索引值为1),该索引值成为removedIdx=1。同时,调度器递减p,检索到idleList中最后一个空闲节点的ID(lastNode = 7)。
pass2(Fig4.c)调度器重新提交带有附加数据(removedIdx=1,lastNode = 7)的数据包,最后idleIndex[removedIdx] = lastNode。
要想保证处理阶段少,就要保证在原子读-修改-写操作时,第一步读取到的就是正确的。所以采用空闲节点连续放置的策略。
(2)当所有节点都很忙时。
scheduler从节点的队列长度中随机选取2个样本,在采样值中选取负载最小的节点。成为power-2策略。
每次调度时候,仅随机选取2个节点样本,是有效的吗?或者说是否足够有说服力?
作者给出2点解释:①仅选取两个样本,可以缩短响应时间。特别对于细粒度任务,任务执行时间很短,因此更容易受到worker负载更新的响应时间的影响。②随机化防止任务群集。粒度任务更容易受到任务群集的影响。
由于交换机模型的限制,不允许从同一块内存中读取每个数据包的多个项目。
办法:Horu用两个阶段,维护两个相同的loadList副本,每个数组存储所有下游节点的负载。
loadList
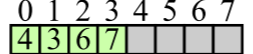
loadList copy
实际队列长度:
![]()
,其中lm是q队列的实际负载值,dm是q队列的drift偏移负载值,dm定义为调度到节点的,但未反映在其负载值中的任务数。
所有节点的drift值存储在driftList 数据结构中。
driftList
![]()
![]()
![]()
,
![]()
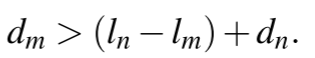
此时,m的drift值才会影响下一步的调度决策,此时才会重新提交报文更新load更新lm和ln值。如果是小于,调度算法对节点m的每个driftList副本中相应的drift值+1。
以上就是惰性状态更新算法,只有在影响未来调度决策时,才会重新提交数据包。
4.状态分配
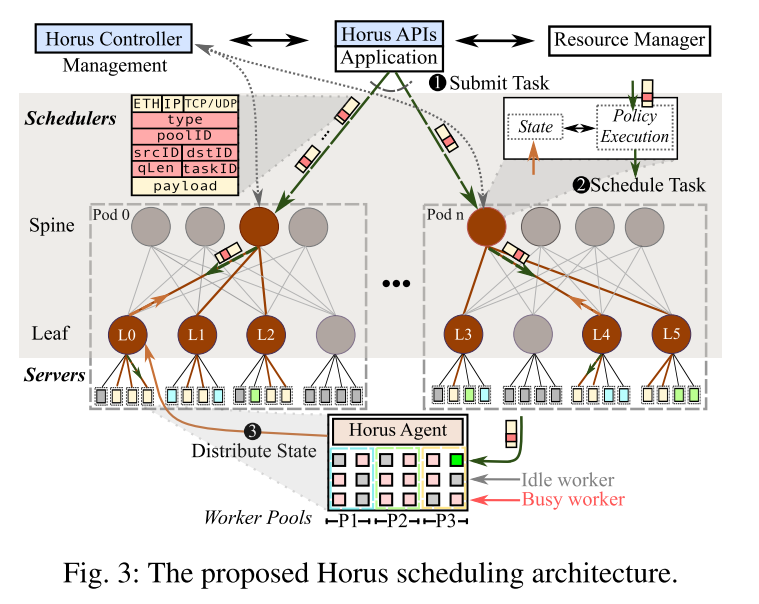
(1)worker状态分配给leaf scheduler
Agent应答包修改报文头部的qLen字段,向leaf scheduler报告更新后的load,如果应答包表示工作线程处于Idle worker,那么leaf scheduler会把srcId加到idleList中,并为相应的索引更新lodeList。
(2)分发Rack状态到spine
①Rack的空闲。leaf scheduler发送idleAdd包给spine scheduler。当Rack中的所有worker都处于Busy状态,发送idleRemove。
②Rack的平均负载。每个leaf scheduler计算Rack中工作线程的平均负载,并将其发送到spine scheduler。【注意:由于可编程交换机的编程模型限制,直接计算平均值是不可行的,A.2中介绍了如何近似平均值。】只有当当前的平均负载和之前的平均负载之间的差值大于/等于1时,leaf scheduler才会发送更新消息。
Horus部署优势
1.可以部署在各种网络中,不依赖数据中心的结构,因为利用的第4层报头。
2.可以增量部署在数据中心中,将一小部分spine和leaf 交换机升级为可编程,用于支持延迟敏感的应用。Horus的集中控制器可以配置为仅使用可编程骨干交换机。
3.Horus也可以仅替换spine交换机,leaf交换机需要引导worker和Agent获取load信息,但是这步操作的延迟是有限、可容忍的。
4.即使没有任何可编程交换机,Horus的idea都可以在软件中实现,leaf功能很好做,spine的功能可以与处理任务提交的数据中心负载平衡器集成。
Tofino交换机测试平台
1.配置场景
3.2Tbps的Tofino有两个hardware pipeline,其中一个运行spine scheduler,另一个配置运行4个 leaf scheduler。每个leaf scheduler代表一个Rack。spine和leaf之间逻辑链路是100G,每个leaf通过10Gbps连接7台服务器。
2.代码量
Golang 6K code,实现了交换机和集中式控制器。使用DPDK在C中实现了一组API来提交任务和接受结构。用100行 c实现了Horus代理。
3.Single Rack中与RackSched对比
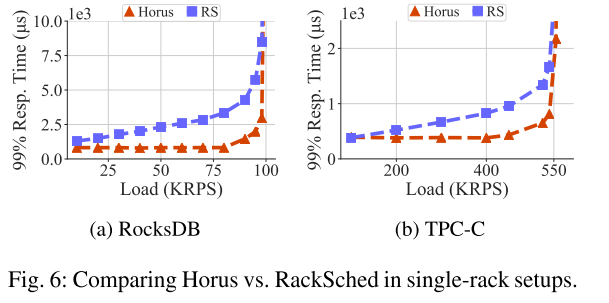
Horus可以跟踪并使用Rack内空闲的worker,RS不显式跟踪空闲的工作线程,使用power of 2策略,会导致任务并不总是分配给空闲线程。
4.DataCenter中与RackSched对比
RS-LB集成负载平衡器,将任务统一的分配给leaf,leaf再运行RS,将任务分配给worker.
RS-H spine运行RS,将任务分配给leaf,leaf上再运行RS,将任务分配给worker。
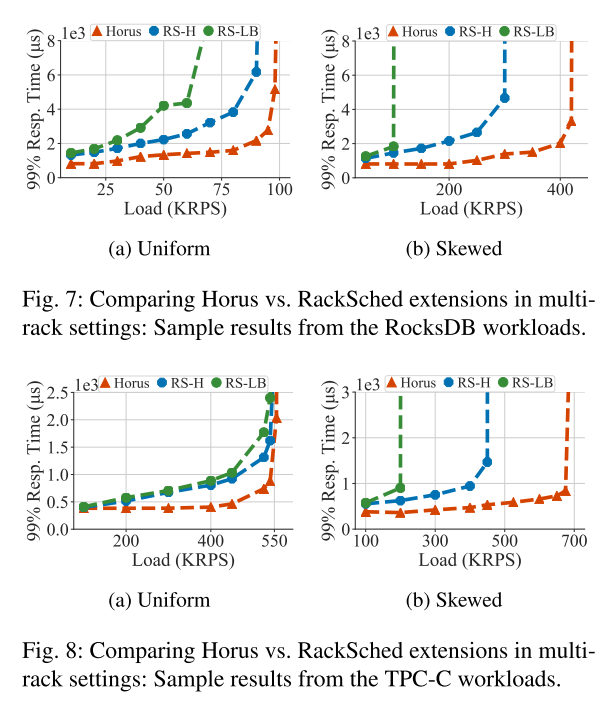
1.跟踪并分配空闲工作线程。
2.当所有线程都Busy时,可以用power-of-2计算出最短的load的线程。
3.利用延迟更新(Lazy更新)维护load的最新信息,减少通信响应延迟。避免群集效应,减少了worker间负载不平衡。
5.Horus对动态事件的响应能力
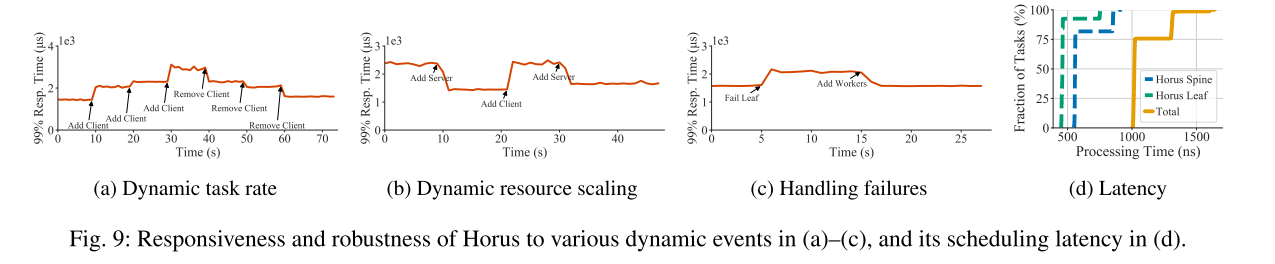
大规模仿真实验
1.规模
1152个leaf 交换机、每个leaf交换机连24台服务器。总共27648台服务器。每台服务器32核,最多可以容纳32个worker。交换机间平均延迟为5us
2.对比Single Rack
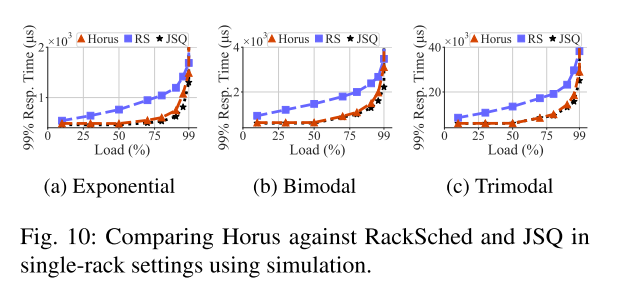
JSQ在实际环境中,不可实现,模拟了一个假设的交换机,使用0延迟状态更新执行JSQ。
Horus更准确的跟踪worker上的负载,与理论界限相差很低。
3.对比Datacenter
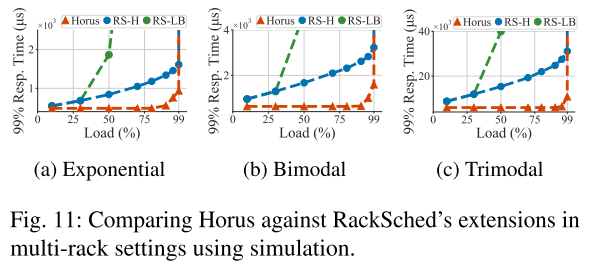
在执行时间和离散程度很高时,Horus能够展现出非常明显的增益。
4.在极端情况下的影响
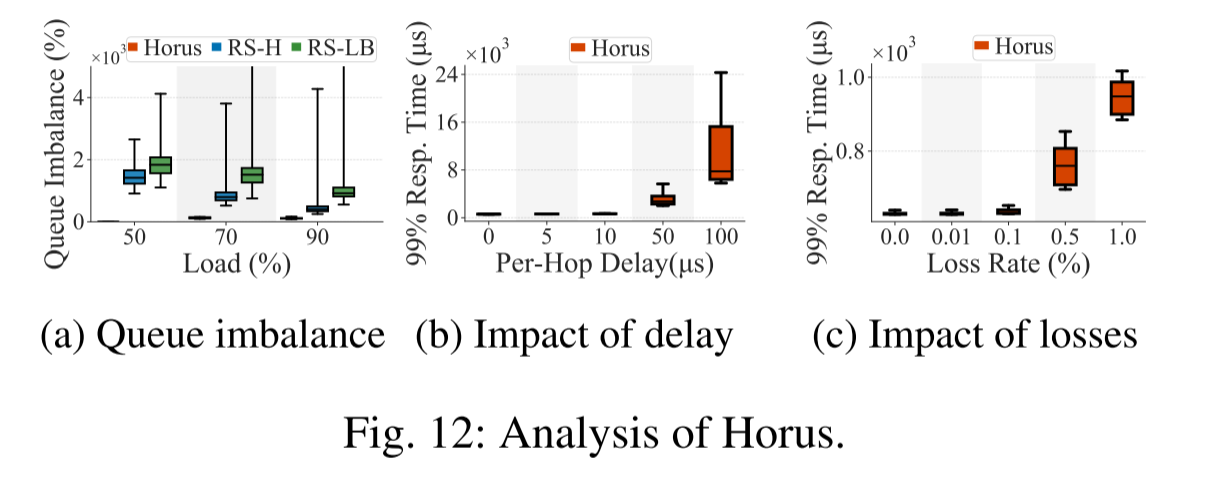
总结与启示
1.Horus是用于多租户数据中心的粒度任务调度程序,本文对Horus对设计、实现和大规模评估。
2.将时延敏感的调度任务,和worker的负载信息,转移到网络交换机上,以高速率实时调度。
3.探索了可编程交换机的能力边界,比如:原子内存更新、有界数据包延迟、近似平均值计算。
4.针对能力边界,提出了有效的设计思想:
①跟踪并分配空闲工作线程。
②当所有线程都Busy时,可以用power-of-2计算出最短的load的线程。
③利用延迟更新(Lazy更新)维护load的最新信息,减少通信响应延迟。避免群集效应,减少了worker间负载不平衡。
和数据结构:idleList和idleIndex。
启示:
NSDI文章:对可编程交换机硬件能力的探索。实验部分并不是很多,对比RackSched(原型及RS-H、RS-LB),在负载、时延、丢包率变化下,Horus的容错能力。
设计方法并不是很复杂、也谈不上巧妙。缺乏场景和问题。















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









