







Linux企业运维——Kubernetes(二十)Prometheus监控
文章目录
一、Prometheus简介
除了资源指标(如CPU、内存)以外,用户或管理员需要了解更多的指标数据,比如Kubernetes指标、容器指标、节点资源指标以及应用程序指标等等。自定义指标API允许请求任意的指标,其指标API的实现要指定相应的后端监视系统。
Prometheus是第一个开发了相应适配器的监控系统。

Prometheus是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件Prometheus服务器定期从静态配置的监控目标或者基于服务发现自动配置的目标中进行拉取数据,新拉取到的数据大于配置的内存缓存区时,数据就会持久化到存储设备当中。
如上图,每个被监控的主机都可以通过专用的exporter程序提供输出监控数据的接口,并等待Prometheus服务器周期性的进行数据抓取。如果存在告警规则,则抓取到数据之后会根据规则进行计算,满足告警条件则会生成告警,并发送到Alertmanager完成告警的汇总和分发。当被监控的目标有主动推送数据的需求时,可以以Pushgateway组件进行接收并临时存储数据,然后等待Prometheus服务器完成数据的采集。
二、k8s部署Prometheus
server2添加apphub仓库源

查找prometheus-operator并拉取

在harbor仓库新建一个项目名为kubeapps

真实主机将prometheus-operator包发送给server1

server1加载prometheus-operator镜像

将prometheus-operator镜像上传至仓库

server2解压prometheus-operator包并进入目录,编辑values.yaml

把报警、Grafana、Prometheus三个组件的Ingress打开,将所有镜像(8个)都指向私有仓库




248 repository: kubeapps/quay-alertmanager
991 repository: kubeapps/ghostunnel
1008 repository: kubeapps/kube-webhook-certgen
1177 repository: kubeapps/quay-prometheus-operator
1184 repository: kubeapps/quay-configmap-reload
1190 repository: kubeapps/quay-prometheus-config-reloader
1204 repository: kubeapps/k8s-gcr-hyperkube
1417 repository: kubeapps/quay-prometheus
编辑完成后去依赖性子目录charts/中,可以看到三个组件:
- kube-state-metrics:
Prometheus提供的多项指标数据格式与k8s数据格式不兼容,还需要一个中间组件,kube-state-metrics负责从prometheus的数据格式转换为k8s集群可以识别的格式。 - prometheus-node-exporter:
安装在被监控端,负责采集多种数据。Prometheus通常去不同client端拉取数据,但有些应用数据无法拉取,这时候这些应用将数据push到Pushgateway网关,由Pushgateway网关将数据发送给server端。 - grafana:
是用来展示指标的图形化管理工具

进入grafana/目录下,编辑values.yaml配置文件,打开Ingress,配置hosts,将镜像指向私有仓库

52 repository: kubeapps/grafana
65 image: "kubeapps/bats"
91 repository: kubeapps/curl
209 repository: kubeapps/busybox
432 image: kubeapps/k8s-sidecar:0.1.20
进入kube-state-metrics/目录下,编辑values.yaml配置文件

将镜像指向私有仓库

进入prometheus-node-exporter/目录下,编辑values.yaml配置文件
将镜像指向私有仓库
创建prometheus-operator命名空间,将prometheus-operator安装在prometheus-operator命名空间下
(注意宿主机和集群虚拟机时间要同步,因为Prometheus是以时间序列方式采集数据)

查看所有pod

控制器也就绪
prometheus-operator-kube-state-metrics:兼容数据

查看prometheus-operator命名空间内的ingress也正常运行

为测试访问,为真实主机添加域名解析

通过浏览器访问prometheus.westos.org,进入status菜单栏内的service discovery

服务正常显示

访问grafana.westos.org,输入配置文件中设定好的用户名和密码

在设置中,数据源默认为prometheus

显示数据源正常工作,点击测试
找到prometheus将其添加到监控面板

可以看到监控页面正常运行

三、Prometheus监控nginx访问量
通过图形化界面直接安装nginx

应用名称设置为nginx,使用9.4.1版本,服务类型为LoadBalancer

副本数量选择1个,打开Prometheus监控选项,Prometheus专门监控nginx的agent插件:nginx-exporter

修改yaml配置文件,更改镜像仓库地址

设置镜像仓库和标签

下图是我们刚指定的镜像

指定服务部署在prometheus-operator命名空间内

整体配置如下图所示

配置完成后等待镜像部署完成

通过浏览器访问上图nginx应用的URL,可以看到正常访问
在命令行界面查看pod信息,可以看到刚创建的nginx及其服务和外部访问地址

为nginx添加release=prometheus-operator这个标签

现在在图形管理界面可以看到nginx服务

点击Graph,将访问流量统计图添加进统计页


可以看到nginx访问流量效果图

四、Prometheus实现hpa动态伸缩
server2查看pod信息可以看到prometheus-operator-kube-state-metrics

执行 kubectl api-versions 查看api group ,metrics为v1beta1版本

查找prometheus-adapter插件,拉取到本地并解压,编辑values.yaml配置文件

配置镜像地址和prometheus的服务地址

配置文件中的prometheus的服务地址可以通过下图命令查看

可以拉起一个新的容器并进入,测试是否能访问到上面prometheus的服务地址

在prometheus-operator命名空间下安装prometheus-adapter,复制下图指令

查看prometheus-operator命名空间下的pod信息,都正常运行

可以查看到刚才复制的指令中的api

执行刚才复制的指令

再次执行刚才复制的指令,这次指定命名空间、pod和监控指标

指定的监控指标名字就是下图红框部分
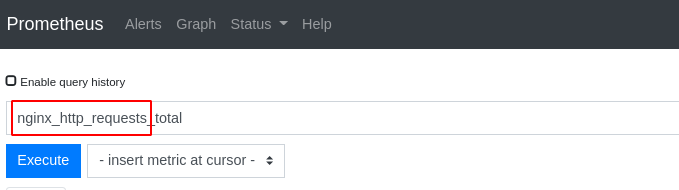
也可以编写python脚本运行指令进行参数配置

编辑hpa-nginx.yaml配置文件并应用
[root@server2 helm]# cat hpa-nginx.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-example
spec:
maxReplicas: 10 #最多伸缩到10个副本
minReplicas: 1 #最少伸缩为1个副本
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
metrics:
- type: Pods
pods:
metric:
name: nginx_http_requests #指定监控nginx访问流量
target:
type: AverageValue #伸缩依据是均值是否在10
averageValue: 10

查看hpa详细信息,HPA可以根据pods的nginx访问流量度量成功计算副本计数

hey用来进行压力测试,真实主机把hey复制到/usr/local/bin,赋予可执行权限

命令行输入hey可以看到参数用法

真实主机运行hey进行访问测试,参数设置总共访问一万次,每秒访问五次,5个线程并发

kubectl get hpa hpa-example -w查看hpa的动态状态变化,可以随着访问压力的增大hpa开始生效并增加副本数量,逐渐扩容到3个

可以看到图形化展示
















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









