







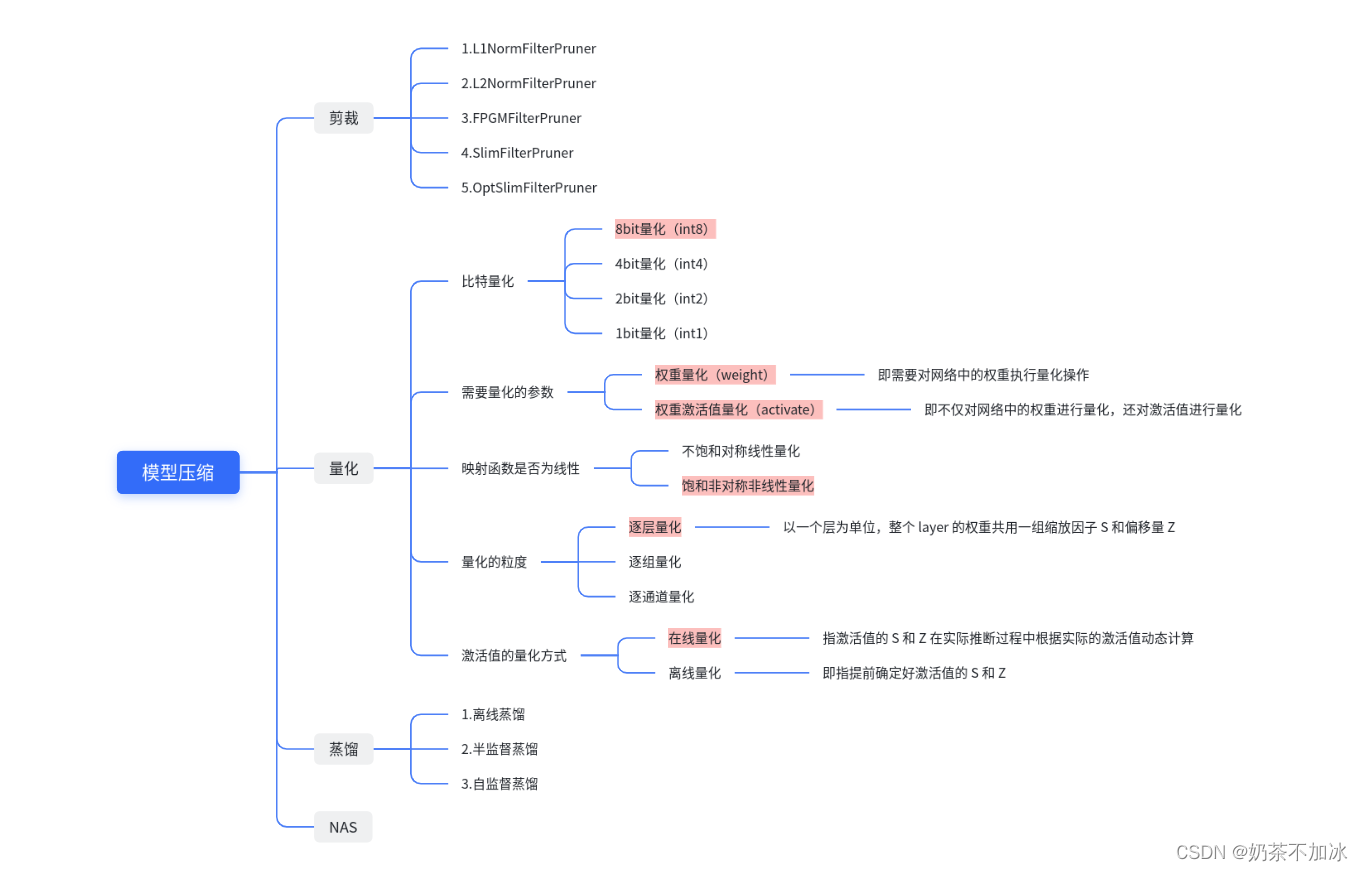
1.裁剪(pruning)
定义:裁剪是指对卷积网络的通道数进行裁剪,减少大模型的参数量
1.1 L1NormFilterPruner
论文:https://arxiv.org/abs/1608.08710
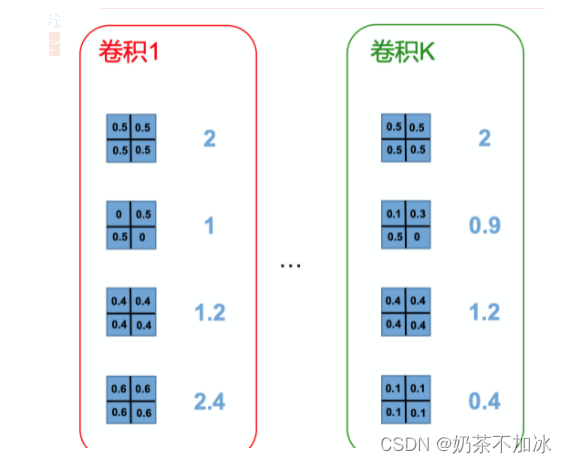
使用L1-norm统计量来表示一个卷积层内各个Filters的重要性,L1-norm越大的Filter越重要。
L1Norm直接计算各滤波器的L1范数,根据范数大小来决定裁剪哪个滤波器,如下左图,第二个滤波器L1范数最小,所以裁剪第二个滤波器,同理裁剪右图的第4个滤波器
1.2 L2NormFilterPruner
L2Norm计算各滤波器的L2范数,根据范数大小来决定裁剪哪个滤波器。

1.3 FPGMFilterPruner
论文: https://arxiv.org/abs/1811.00250
该策略通过统计Filters两两之间的几何距离来评估单个卷积内的Filters的重要性。直觉上理解,离其它Filters平均距离越远的Filter越重要。
1.4 SlimFilterPruner
论文:https://arxiv.org/pdf/1708.06519.pdf
该策略根据卷积之后的batch_norm的scales来评估当前卷积内各个Filters的重要性。scale越大,对应的Filter越重要。
1.5 OptSlimFilterPruner
论文:https://arxiv.org/pdf/1708.06519.pdf
2.量化
定义:将float32(占用4bit)计算量化为int8(1bit)计算,使得模型的计算量和参数量减少
量化是指将信号的连续取值近似为有限多个离散值的过程。可理解成一种信息压缩的方法。在计算机系统上考虑这个概念,一般用“低比特”来表示。也有人称量化为“定点化”,但是严格来讲所表示的范围是缩小的。定点化特指 scale 为 2 的幂次的线性量化,是一种更加实用的量化方法。
原理:模型量化为定点与浮点等数据之间建立一种数据映射关系,使得以较小的精度损失代价获得了较好的收益。
2.1 tensorrt (低比特推理)
前提,使用float32高比特的数值进行训练,训练得到的网络精度较高,有一定的容忍度。训练时使用高比特的数值表示,可以让网络以很小的计算量修正参数。而,使用低比特的数值来表示网络参数以及中间值,会带来一定误差,但是低比特数值引进的误差是在网络的容忍度之内的,所以对预测精度不会产生大的影响。

图2.1 不同比特的数值表示动态范围
将float32降为int8的过程,也就是相当于信息再编码,将使用float32来表示的一个tensor用int8来表示,这里面的float32转换为int8需要对每一层的输入tensor和网络中学习到的参数都需要进行转换。
2.1.1线性量化(线性映射,又叫对称映射)
映射前后的数值(float<->int8)满足以下关系式

sf是每一层相对于上一层tensor的比例因子。
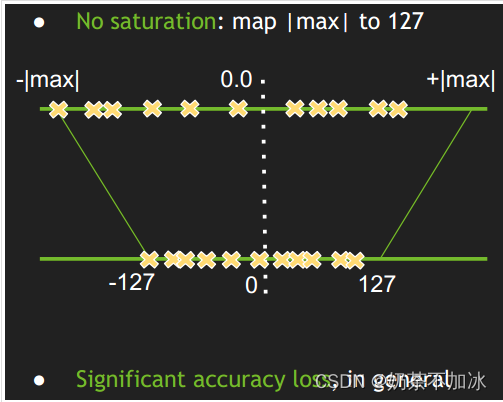
图2.2 不饱和对称映射
如上图,是一个对称映射示意图,简单的将一个tensor中的-|max|和|max|(float32)数值映射到-127和127(int8数值表示范围),中间值也按照线性关系进行映射。
实验结果表明,上述的映射方式会产生很大的精度损失
2.1.2 tensorrt的做法(不对称映射)
![[图片]](https://img-blog.csdnimg.cn/8453cdd74b5f4170987a3d74eb13fb44.png)
图2.3 饱和不对称映射
如上图,不直接将原数值土|max|映射为土127,而是使用一个阈值|T|,将土|T|映射为土127,阈值|T|值是小于|max|。具体一点,就是超出阈值土|T|的数值直接映射为土127,如上图的红色数值。阈值T选取变成关键。

如何确定T?
引入一个衡量指标相对熵(又称为KL散度),来衡量不同的int8(Q)分布与原来的float32(P)分布之间的差异程度。计算公式如下:
[图片]
公式左边的P,Q分别称为reference_distribution、quantize_distrbution
确定每一层的|T|值也称为校准(Calibration)过程
2.1.3 校准(calibration)->确定|T|值
从验证集选取一个子集作为校准集,激活值的分布就是从校准集中得到。过程如下:
1)首先在校准集上进行原精度(float32)推理;
2)遍历网络的每一层,收集每一层的激活值,并制作成直方图,分成若干个组别;
3)对于不同的阈值|T|进行遍历,选取使得 KL_divergence(ref_distr, quant_distr) 取得最小值的|T|;
4) 返回一系列的|T|值,创建校准表
![[图片]](https://img-blog.csdnimg.cn/bf6c13cec01e4c63bd1c38c43dfd7759.png)
计算KL散度 KL_divergence(P, Q)的时候,(P,Q序列的长度需要一致)
2.1.4 DP4A(Dot Product of 4 8-bits Accumulated to a 32-bit)
![[图片]](https://img-blog.csdnimg.cn/7f2b442a3314485db48aa8548ab2c7d9.png)
tensorrt int8卷积计算使用到DP4A计算方式。首先使用int8的输入与int8的权重相乘,得到int32的输出,然后强制转换为float32,并将float32的偏置乘上缩放因子与前面计算得到的float32数值进行相加,然后激活,最后再将float32转为int8。
2.1.5 可提升的方向
对阈值|T|进行微调,用户自定义比例因子等
2.2 动态量化与静态量化
动态量化:对于动态量化,缩放因子(Scale)和零点(Zero Point)是在推理时计算得到的,并且特定用于每次激活,优点是准确率更高,缺点是带来了额外的计算开销,一般常用于RNN,transform的模型中量化方式;
静态量化:使用校准数据集离线计算缩放因子(Scale)和零点(Zero Point),这样网络中所有的缩放因子和零点都一样,一般常用于对卷积神经网络模型的量化方式。
2.3 离线量化与在线量化
离线量化:又叫训练后量化,仅需要使用少量校准数据,确定最佳量化的参数降低量化误差,优点是需要的数据量少,但是量化模型精度低于在线量化。
在线量化:

3.蒸馏
定义:将大模型的知识迁移到小模型上,来提升小模型的精度。通过构建一个轻量化的小模型(student模型),利用性能更好的teacher模型来监督student模型进行训练
3.1 离线蒸馏
需要在已知数据集上训练一个teacher模型,然后用该teacher模型对student模型进行监督训练来达到蒸馏的目的。(teacher模型的精度与student模型精度差值越高,蒸馏的效果越好)
3.2半监督蒸馏
利用teacher模型的预测信息作为标签,对students模型进行监督学习。在输入students模型训练之前,将未标注的数据,利用teacher模型进行预测,输出的标签信息再作为训练数据输入到student模型当中。
这种方式,减少了数据标注的时间,可以让student模型学习更多的数据,提高精度。
3.3自监督蒸馏
整个过程由student模型本身的训练完成,不需要teacher模型进行监督。实现方式有,先开始训练student模型,然后在整个训练过程中的最后几个epoch,利用前面训练好的student模型作为监督模型,在剩下的epoch中,对模型进行蒸馏。
4.NAS(Network Architecture Search)
定义:自动神经网络搜集,是一种自动设计神经网络的技术,根据搜索空间使用一定的搜索算法来自动设计出高性能的网络结构。
首先需要定义一些神经网络结构,将数据和网络结构随机组合,让神经网络自己选择下个模块,一个模块预测一个模块,最终组合成一个完整的神经网络
参考链接
[1] https://blog.csdn.net/qq_40035462/article/details/123361763
[2] https://zhuanlan.zhihu.com/p/374374300















 5107
5107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











