







前三节已经对Stable Diffusion的文生图界面的操作功能进行了详细的介绍,接下来开始对Stable Diffusion的图生图界面进行讲解。往期文章详见:
微信公众号:Rain要努力啊。
四、Stable Diffusion界面功能介绍(图生图)
Stable Diffusion的图生图界面和文生图界面的主要区别就在于「生成」模块,所以接下来会重点讲解「生成」模块的内容,其他与文生图一致的内容这里就不再赘述了。下面对图生图参数、涂鸦、局部重绘、上传重绘蒙版、批量处理等进行详细介绍。
1、图生图的由来
使用文生图功能进行AI绘图时,会存在下列问题:
-
文字表达一张图片,很难全面、清晰的描述出图片内容,造成最终生成的图片效果不及预期
-
大模型由于训练数据集的问题,有些东西生成不出来,或者理解的不好,造成生图结果不理想。
文生图只有文字一个纬度去控制图片生成,而图生图除了文字纬度,还增加了图片的参考,使得SD的生成结果更佳。下图展示了图生图的使用效果:
| 原图(上传的参考图) | SD生成的图片(三次元模型) | SD生成的图片(二次元模型) |
|
|  |  |

2、图生图的原理
首先SD会对上传的图片铺上噪点,铺设噪点的数量取决于重绘幅度。之后SD在噪点图的基础上逐步去除噪点,最终得到新的图。
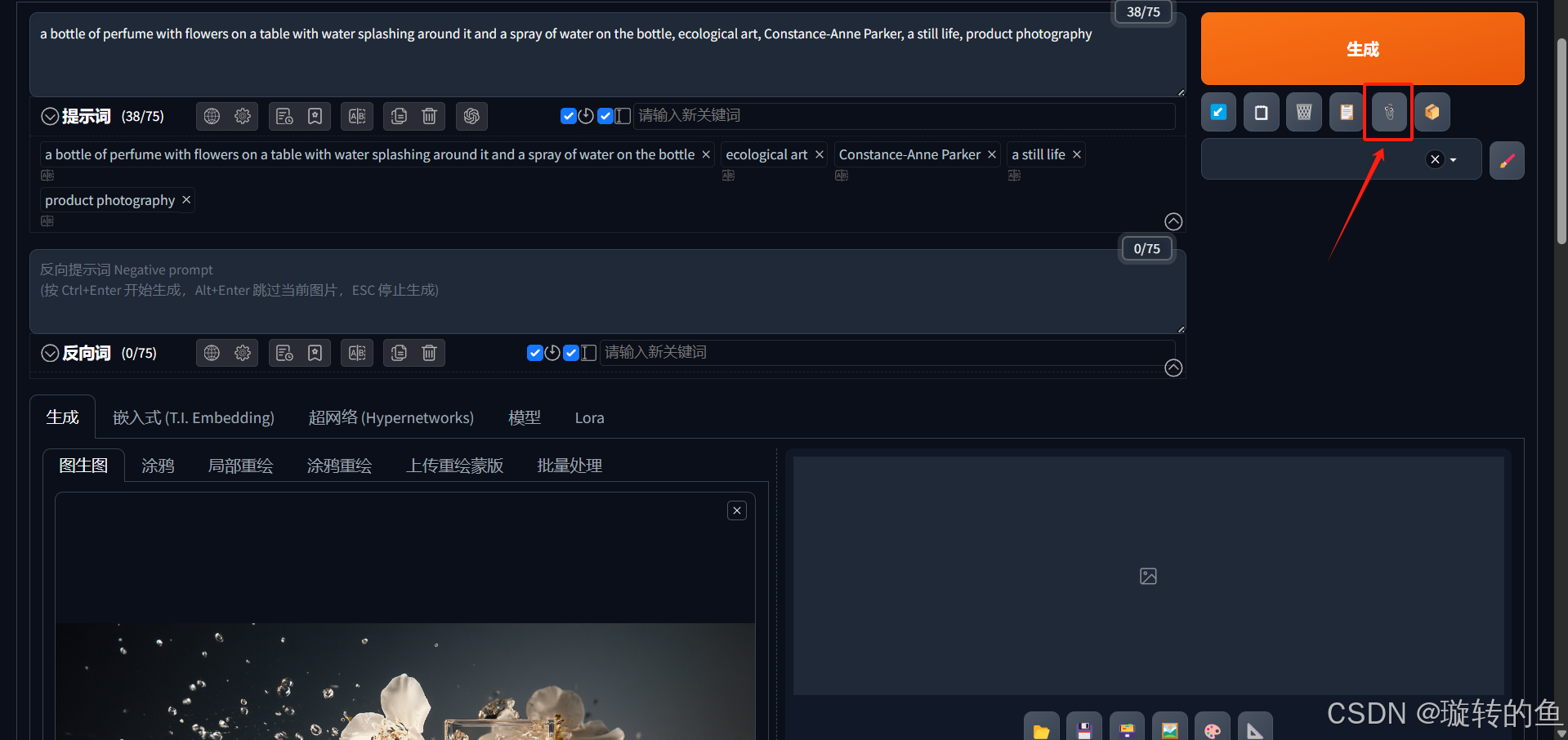
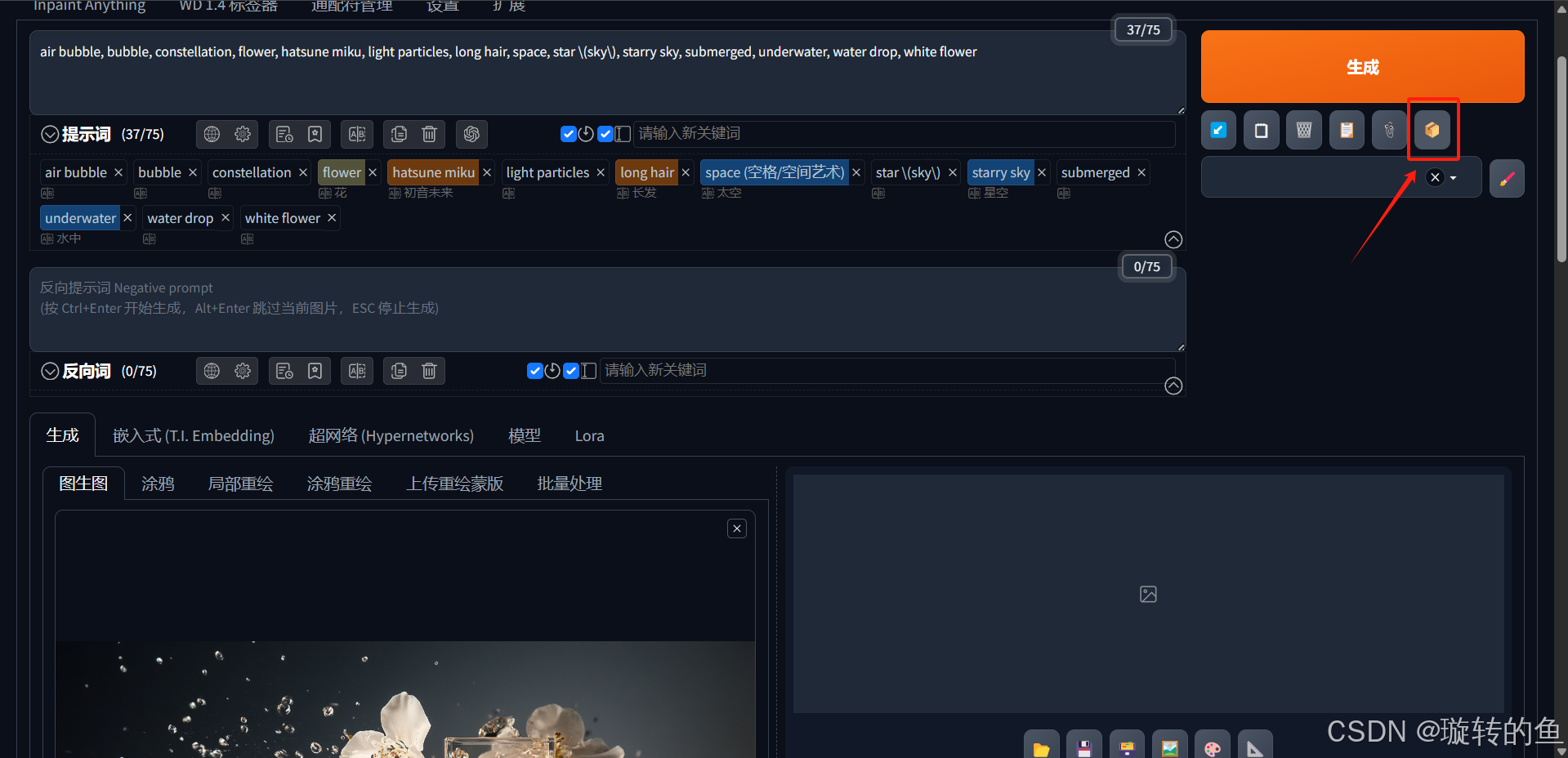
3、提示词反推
图生图的提示词是需要写最终想要生成图片的提示词,而不是写上传图片的图片描述。SD提供了2种提示词反推功能,分别是:
-
CLIP反推:根据图片反推出来的提示词为句子。
-
DeepBoorn反推:根据图片反推出来的提示词为单词。基本已经被淘汰了。
需要注意的是,无论使用哪种反推方式,反推的结果都不可能全面,需要我们自己根据反推结果进行修改。下表展示了针对同一张Midjourney生成的香水静物图,分别使用2种提示词反推方式进行反推的效果对比:
| 原图 | CLIP反推 | DeepBoorn反推 |
 | a bottle of perfume with flowers on a table with water splashing around it and a spray of water on the bottle, ecological art, Constance-Anne Parker, a still life, product photography | air bubble, bubble, constellation, flower, hatsune miku, light particles, long hair, space, star \(sky\), starry sky, submerged, underwater, water drop, white flower |
4、缩放模式
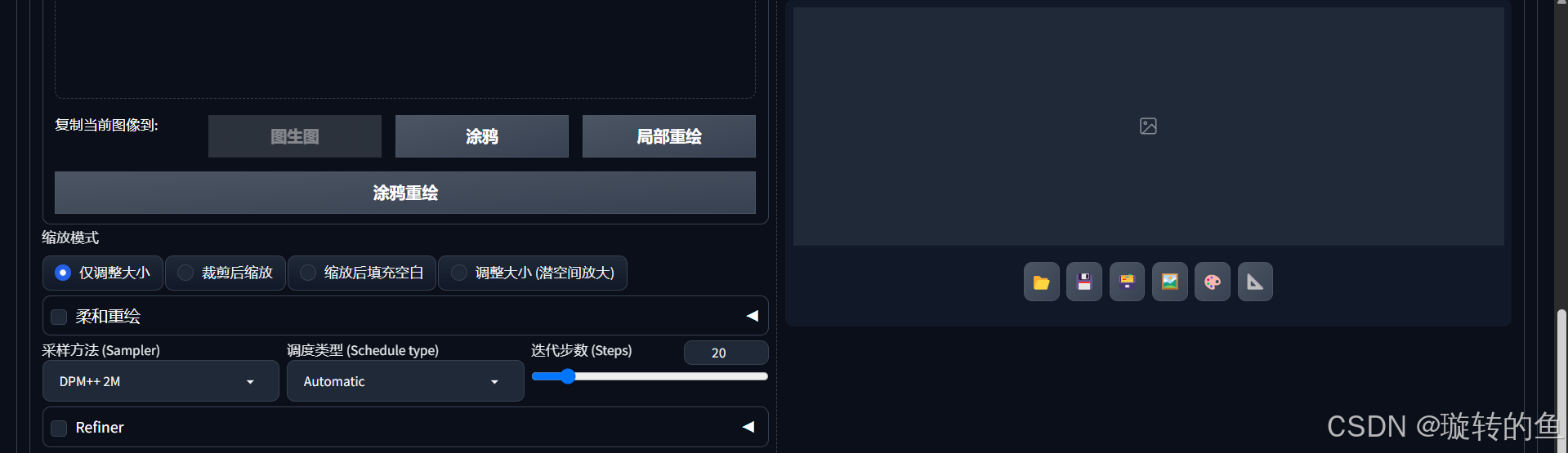
缩放模式用于在图生图中,调整输入的图片的尺寸与最终生成图片的尺寸不同的问题。SD提供了4种缩放模式,分别是:
-
仅调整大小:
-
按照设置的生图结果尺寸进行生成。该模式会强行把图片拉伸/压缩到目标尺寸,无视原始比例,会导致图片变形。
-
当生成的结果图尺寸和原图比例接近时较为适用。
-
-
裁剪后缩放:
-
将原来的图片进行适当裁剪,最终生成的图片只显示裁剪后相应尺寸内的内容。
-
类似于用剪刀剪掉边缘部分,只保留中间部分,再将图片缩放到需要的尺寸。该模式会保持比例不变,但会丢失裁剪区域外的内容。
-
-
缩放后填充空白:
-
将参考图片整体进行缩小,缩小到设定的尺寸内,再自动填充空白部分内容。
-
类似于把手机竖拍照片放到横屏电视上,照片左右两边留黑边,再让AI根据黑边生成内容。该模式会保留完整原图内容,但边缘空白可能被AI随机填充。
-
-
调整大小(浅空间放大):
-
利用模型内部技术调整生成图片的尺寸,减少失真。
-
类似“无损放大”——先在模型内部压缩过的空间(潜在空间)调整尺寸,再还原为清晰图像。适合放大图片时保留细节(比如人脸更清晰,文字边缘更锐利),但耗时可能较长。
-
5、涂鸦
上传图片后可以通过画笔工具,在图片上进行涂鸦绘画。SD会针对涂鸦修改后的图片进行图生图操作。比如上传了一个女孩的图片,希望女孩的毛衣上能印上图案,可以通过画笔在原图上进行绘画,最终生成的效果如下:
| 原图上的涂鸦 | SD生成的图片1 | SD生成的图片2 |
| 1、在毛衣上画黑色"YS"字母
2、在毛衣上画一个红色爱心,爱心中用黑色写着"Love" |  |  |
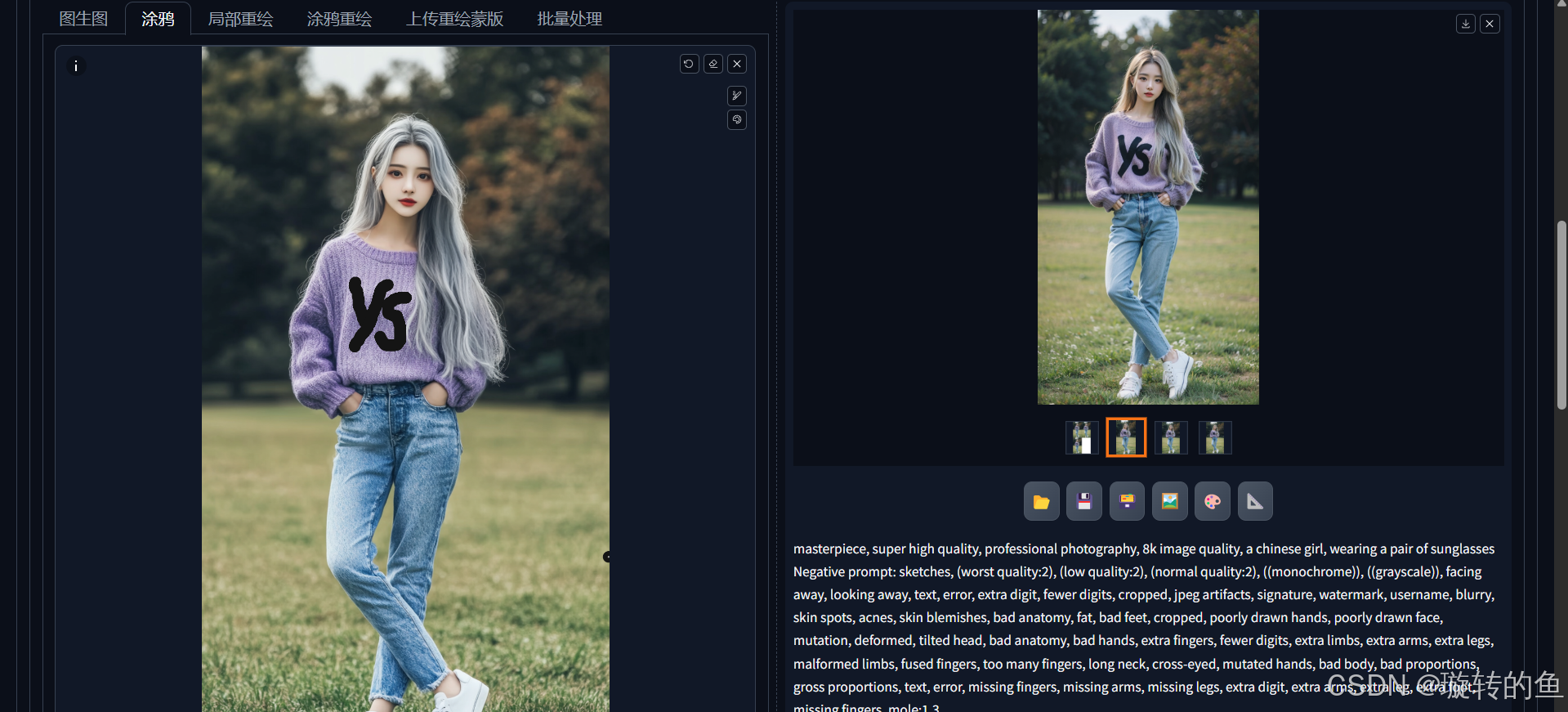
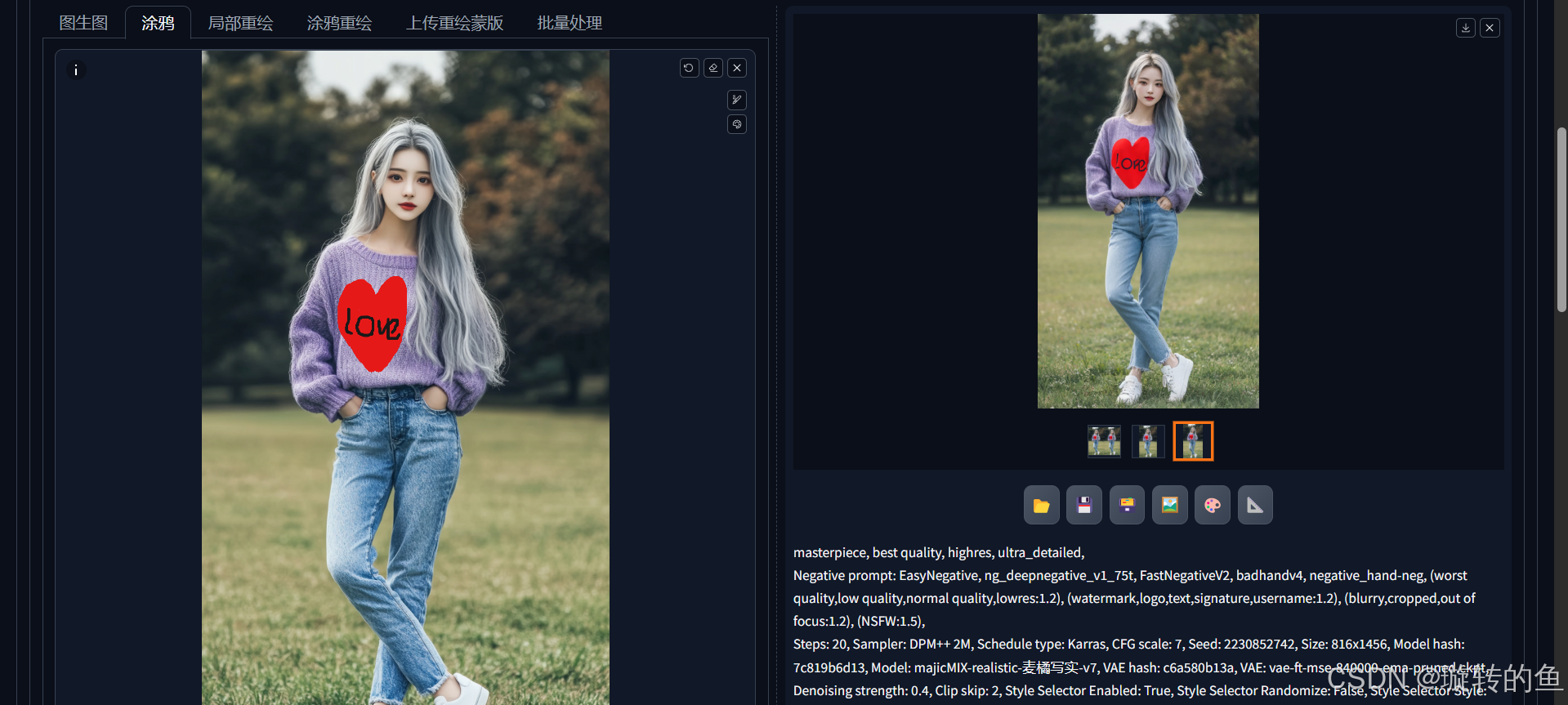
6、局部重绘
如果需要对图片的局部进行修改,比如要给女孩带个墨镜,这种情况下使用涂鸦就几乎不可能完成了,需要使用到局部重绘功能。局部重绘,顾名思义,只对图片中选定的指定区域进行重绘。通常可以用于人物换脸、给人物换衣服等等。局部重绘功能在电商领域使用的很多。
局部重绘的原理:只在图片选中的区域铺加噪点,然后逐步去噪生成结果。注意:当选择使用局部重绘时,提示词中只需要描述需要需要重绘的部分内容即可(即只需要描述蒙版内容)
通过局部重绘来给女孩带墨镜的操作如下:
-
先用画笔涂上需要重绘的区域,这里需要对女孩的脸部进行涂选。
-
提示词中输入带着墨镜。
-
适当调整绘图参数后即可生成戴墨镜的图片。
| 戴墨镜局部重绘操作图 | 生成的结果图 |
| 1、涂选重绘区域
2、写提示词:wearing a pair of sunglasses |  |
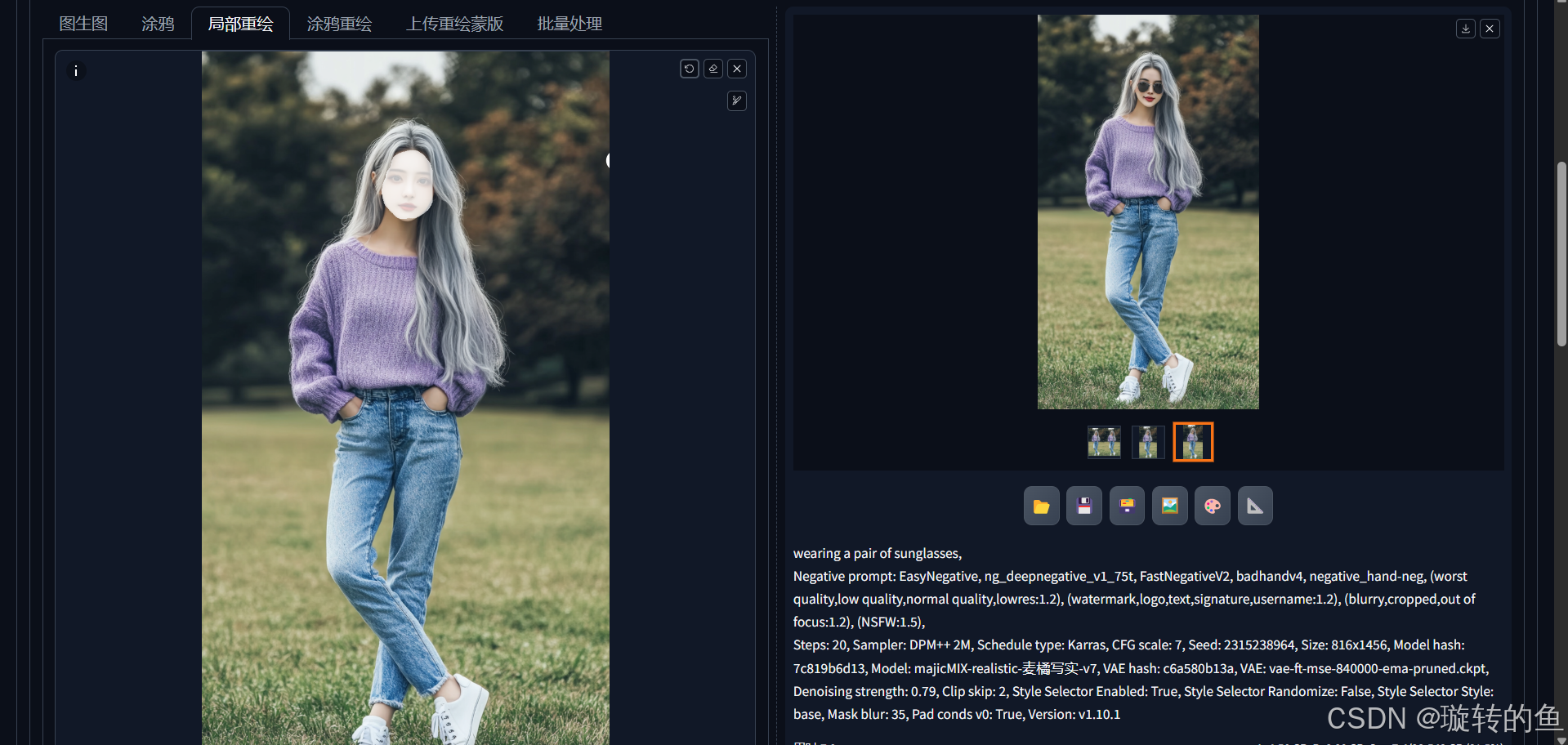
局部重绘的参数介绍:(从截图可以看出,局部重绘的参数中都带有“蒙版”。简单来说,蒙版就像是一块板子,把图片中需要进行重绘的部分给遮住,这样SD就会在图片被遮住的部分进行重新绘画。)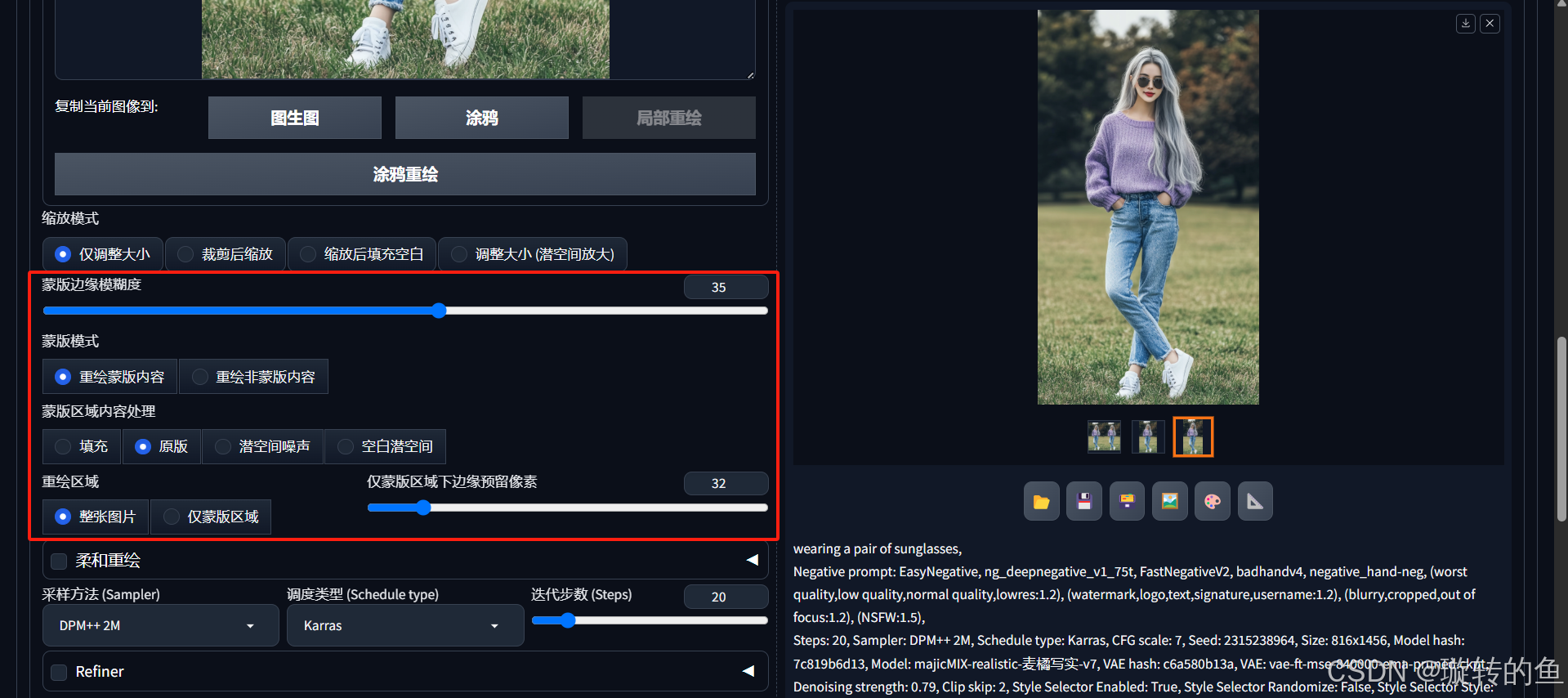
-
蒙版边缘模糊度:给图片添加蒙版后,蒙版边缘与图片之间会存在间隙,蒙版边缘模糊度就是用来调整蒙版边缘的羽化程度的。该参数的数值越大,蒙版区域与原图的接缝感就越弱,生成的图片效果就越好。下表对比了不同蒙版边缘模糊度数值下的生图效果:
| 蒙版边缘模糊度=1 | 蒙版边缘模糊度=10 | 蒙版边缘模糊度=20 | 蒙版边缘模糊度=30 |
|
|  |  |  |

-
蒙版模式:这个很好理解,重绘蒙版内容就是对蒙版的内容进行重绘,而重绘非蒙版内容,就是对蒙版选中区域外的内容进行重绘。
-
蒙版区域内容处理:为了去除掉蒙版区域原像素对生图结果的影响,需要对蒙版区域的内容进行预处理,然后再铺加噪点进行降噪。SD提供了4种预处理方式:
-
填充:重绘区域使用原图模糊化后的像素进行填充,略微参考原图色调进行重绘。使用时重绘幅度应该设置大于0.8。
-
原版:重绘区域使用原图来填充,参考原图进行重绘。使用时重绘幅度在0~1之间皆可,一般不高于0.7。
-
浅空间噪声:噪点以像素方式进行填充(把噪点当成像素来填充),彻底重绘,抹去原图信息。使用时重绘幅度应该大于0.8。
-
空白浅空间:使用统一的棕色来填充,彻底重绘,抹去原图信息。使用时重绘幅度应该大于0.8。
-
下图使用不同处理方式测试了下生图效果(ps:由于个人技术问题,生图效果不好,见谅)
| 蒙版图 | 填充 | 原版 | 浅空间噪声 | 空白浅空间 |
|
|  |  |  |  |

-
重绘区域:分为整张图片和仅蒙版区域。两种方式的对比见下表:
| 区域/对比 | 作用 | 优点 | 缺点 |
| 整张图片 | 整张图片的像素会全部纳入计算,考虑全图内容生成局部内容。分辨率决定了最终图片的大小。 | 生成的图片精准度高 | 无法重绘超大图;重绘小尺寸的图片精度低 |
| 仅蒙版区域 | 只考虑重绘部分生成局部内容,分辨率只填充局部的像素密度。 | 不受分辨率的影响,再大的图都可以重绘;小尺寸的图也可以高精度重绘 | 重绘部分的融合度较差 |
-
仅蒙版区域下边缘预留像素:在给定填充部分像素密度的情况下,降低蒙版内部的像素密度。该参数的值越大,蒙版内填充的像素就越稀疏,画面就越模糊。
最后,简单说下使用局部重绘时的注意事项:
-
局部重绘可以配合Lora模型完成对人物给定脸型的替换。
-
当重绘精度不足时,可以配合controlnet来增加精确度。
7、涂鸦重绘
在局部重绘的时候同时修改原图的像素。已经淘汰了,因为蒙版和像素颜色改变功能高度耦合,涂鸦重绘显得非常不实用,这里就不过多介绍了。
8、上传重绘蒙版
如果直接用画笔在原图上绘画蒙版,会存在局部重绘蒙版精准度低,绘制困难等问题。比如我要给图片上的女孩把紫色毛衣换颜色,换成红色,如果直接用画笔去描边圈出蒙版区域,会非常困难,因为有头发等干扰,且边缘无法准确对齐。可以利用PhotoShop、Photopea插件、inpaint anything插件等对图片进行抠图,扣除蒙版区域后,直接上传重绘蒙版。(重绘蒙版图为黑白图,黑色部分表示不需要SD重绘的部分,白色部分为需要SD进行重绘的部分)
下表展示了在SD中通过画笔来画蒙版区域,以及在PS中通过抠图方式来制作蒙版的对比,可以看出使用画笔来涂蒙版对于毛衣边缘的处理很难,而PS会相对容易,
| 原图 | 通过SD画笔绘制的蒙版图 | PS中抠图的蒙版图 |
|
|  |  |

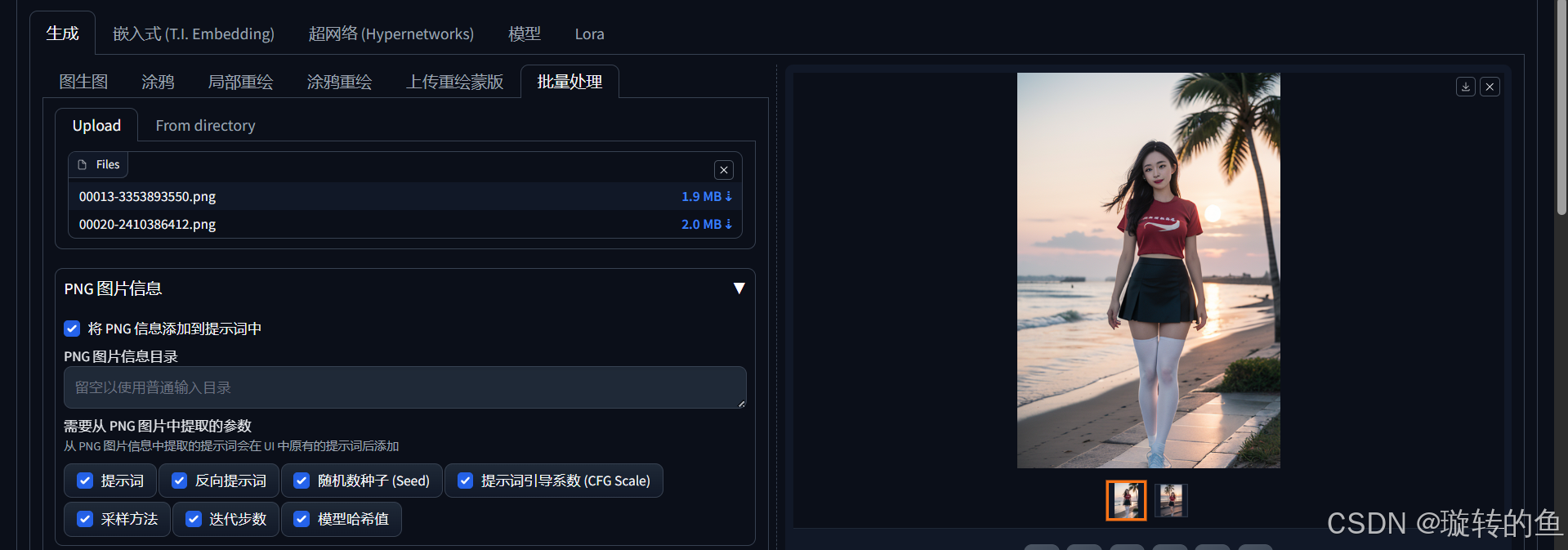
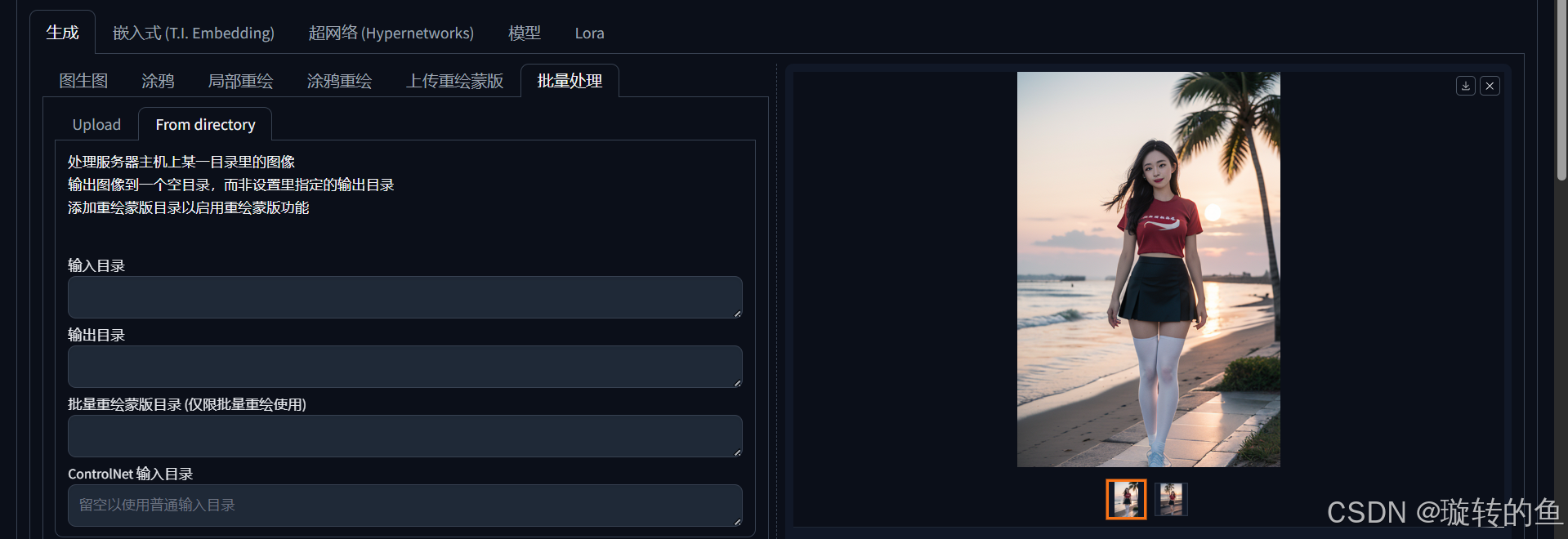
9、批量处理
批量处理主要是用来让SD参考多张图片进行生成图片。可能通过Upload上传图片,也可以通过From directory输入需要上传的图片目录,这样SD会自动读取目录下的全部图片。至于PNG图片信息,看着勾选就好了,很好理解的。
以上就是SD的图生图部分的介绍,至此已经基本将SD的文生图、图生图的基本操作讲解完了。后续会对SD的进阶玩法(比如controlnet等插件使用)进行介绍。


















 3293
3293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











