







代码运行:
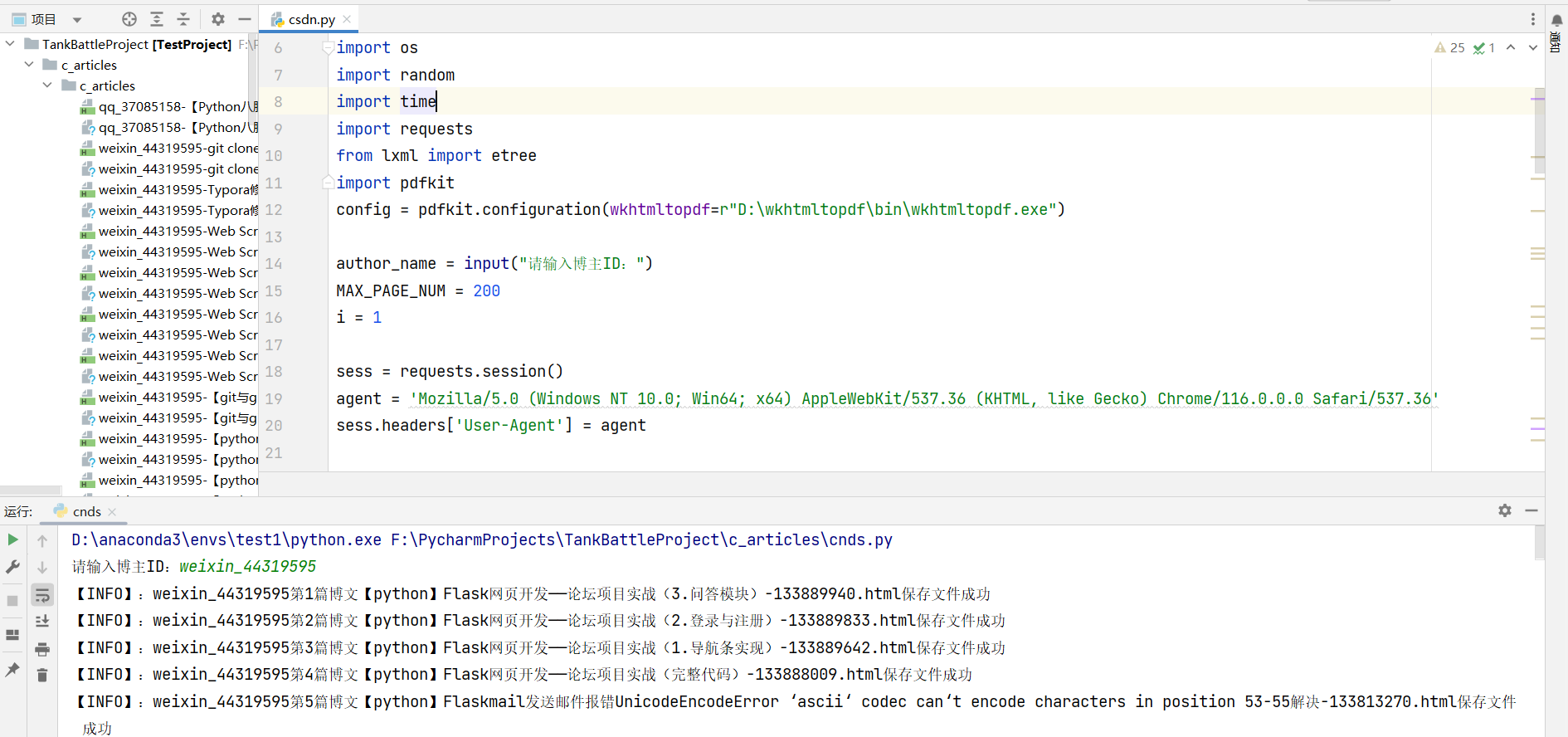
pdf展示
需要下载wkhtmltopdf,html转换为pdf
wkhtmltopdf下载网址:https://wkhtmltopdf.org/downloads.html
代码:csdn.py
"""
step1:爬取博主的所有博文的article_ids
step2:根据article_ids,爬取这篇文章的html,拿到想要的部分
step3:保存为html格式,再保存pdf格式
"""
import os
import random
import time
import requests
from lxml import etree
import pdfkit
config = pdfkit.configuration(wkhtmltopdf=r"D:\wkhtmltopdf\bin\wkhtmltopdf.exe")
author_name = input("请输入博主ID:")
MAX_PAGE_NUM = 200
i = 1
sess = requests.session()
agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
sess.headers['User-Agent'] = agent
def crawler_blog_by(author_name,article_id,title):
article_request_url = f'https://blog.csdn.net/{author_name}/article/details/{article_id}'
response = sess.get(article_request_url)
selector = etree.HTML(response.text)
head_msg = selector.xpath(r"//head")[0]
head_str = etree.tostring(head_msg,encoding='utf8',method='html').decode()
body_msg = selector.xpath(r"//div[@id='content_views']")[0]
body_str = etree.tostring(body_msg, encoding='utf8', method='html').decode()
if not os.path.exists('c_articles'):
os.mkdir('c_articles')
title = title.replace("/","-").replace(":","")
save_file_name = os.path.join('c_articles',f'{author_name}-{title}-{article_id}.html')
with open(save_file_name,'w',encoding='utf8') as writer:
writer.write(f"""<head><meta charset="utf8"></head>
{body_str}""")
html_to_pdf(save_file_name)
global i
print(f'【INFO】:{author_name}第{i}篇博文{title}-{article_id}.html保存文件成功')
i += 1
def html_to_pdf(file_html_name):
pre_file_name = os.path.splitext(file_html_name)[0]
pdfkit.from_file(file_html_name,pre_file_name+'.pdf',configuration=config)
#循环爬取分页html
for page_no in range(MAX_PAGE_NUM):
try:
data = {"page": page_no,
"size": 20,
"businessType": "blog",
"orderby": "",
"noMore": False,
"year": "",
"month": "",
"username": author_name}
pages_dict = sess.get('https://blog.csdn.net/community/home-api/v1/get-business-list',
params=data).json()
for article in pages_dict['data']['list']:
article_id = article['articleId']
title = article['title']
crawler_blog_by(author_name,article_id,title)
time.sleep(random.uniform(0.4,1.0))
except Exception as e:
print(e)
















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











