







目录
1.把获取到的html字符串数据转成 selector 解析对象,返回的就是selector对象
一、安装requests、parsel和pdfkit库
确保已经安装了requests、parsel和pdfkit。以下是安装命令:
pip install pdfkit
pip install parsel
pip install requests
安装失败可能的原因:
1.pip不是内部命令
需要设置python的环境变量
2.安装到一半出现很多红色报错
网络连接超时,切换成国内镜像源
3.安装成功了,但是pycharm调用失败
I.是否安装多个python版本
II.pycharm里面python解释器是否设置好
二、获取发送请求的url地址
搜索标题,Response就是服务器给我们返回的文章内容。
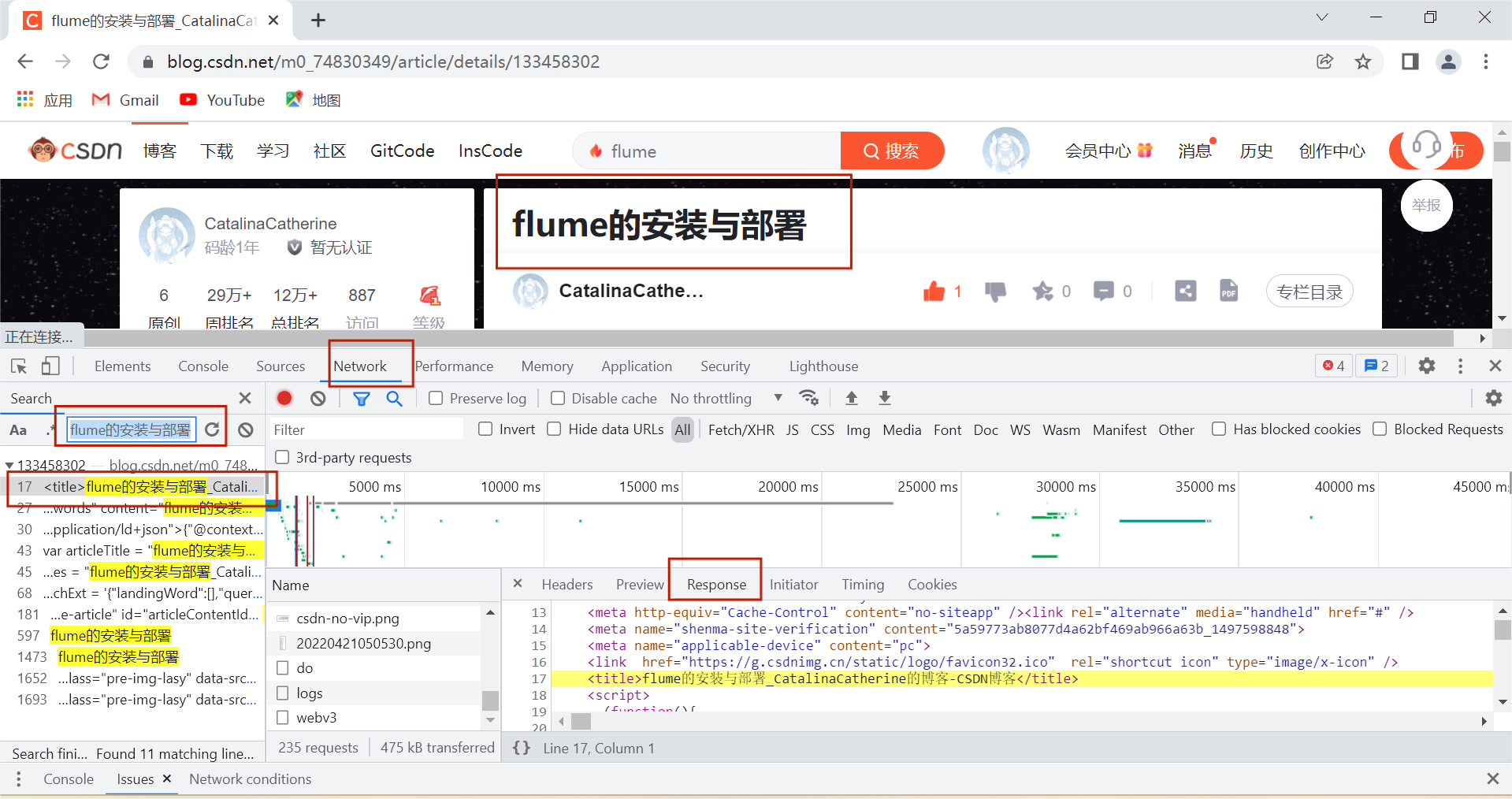
点击Preview就是预览的意思。
-
Request URL:发送请求的url地址
https://blog.csdn.net/m0_74830349/article/details/133458302 -
Request Method:请求方式
-
Request Headers:请求头,参数就在这个里面
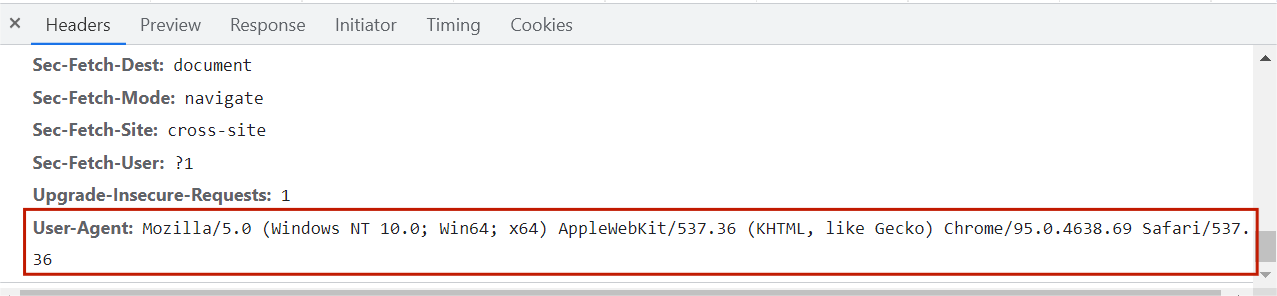
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36

三、获取数据
1.headers
headers请求头,把python代码伪装成浏览器进行请求,可以在开发者工具里面进行查询。
user-agent:浏览器的基本信息。
response对象:200状态码,表示请求成功。
import requests
url = 'https://blog.csdn.net/m0_74830349/article/details/133458302'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
print(response)
2.获取响应体的属性内容,获取网页源代码。
# print(response)
print(response.text)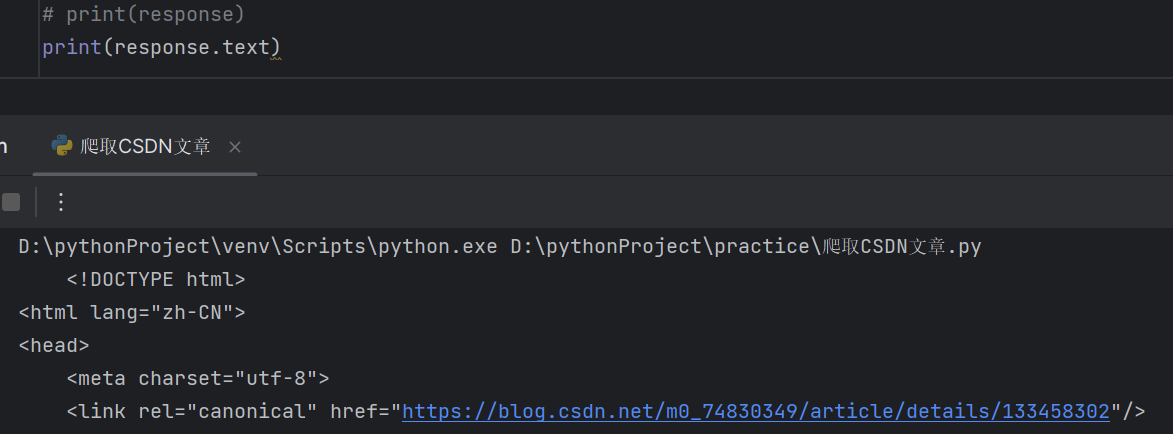
四、解析数据
进入主页,url地址改变了:
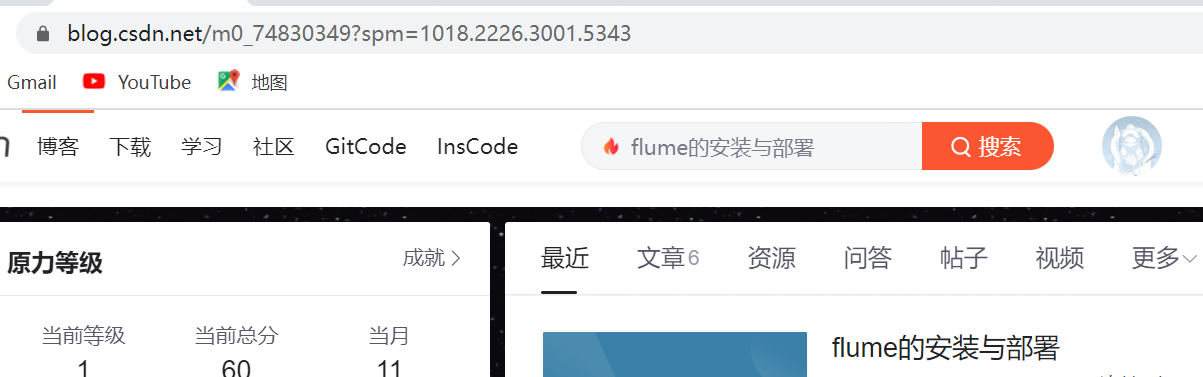
import requests
import parsel
url = 'https://blog.csdn.net/m0_74830349?spm=1018.2226.3001.5343'
headers = {
'user-agent 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3939
3939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









