








C. Guo et al., “Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1777-1786, doi: 10.1109/CVPR42600.2020.00185.
- 这是CVPR2020的一篇低光照图像质量增强的论文,指标上很高,方法也很新颖
亮度调节公式
-
文章并不直接预测增量后的结果,而是首先设计一个带参数的亮度调整公式,然后用网络来预测这个公式中的参数,公式如下:
-
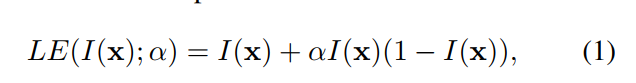
-
这是最简单版本的公式, I ( x ) I(x) I(x)即输入图片(归一化到0-1之间),等式左边为增亮结果, α \alpha α即为亮度调节所需参数,可以将等式除以 I ( x ) I(x) I(x),得到亮度调整倍数为 1 + α ( 1 − I ( x ) ) 1+\alpha(1-I(x)) 1+α(1−I(x)),即当 α \alpha α大于0时,调整倍数为大于1,即为增亮,并且 I ( x ) I(x) I(x)越大倍数越低,也就是说暗的增亮倍数大,亮的增亮倍数小; α \alpha α大于0时, α \alpha α越大,增亮倍数越大。因此这就实现了一个由参数 α \alpha α控制的自适应增亮公式
-
然后其实这个公式可以反复应用,也就是说利用这个公式增亮一次后,可以把增亮结果作为输入再来一次,因此得到迭代版本的公式:
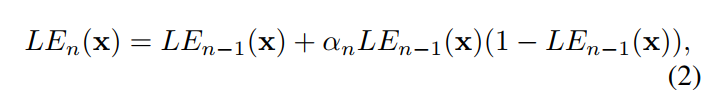
-
然后如果 α \alpha α是pixel-wise的,也就是说对于每个像素点有各自的 α \alpha α,网络的预测结果是一个 α \alpha α的map而非一个值,就得到最终版本的亮度调节公式:
-
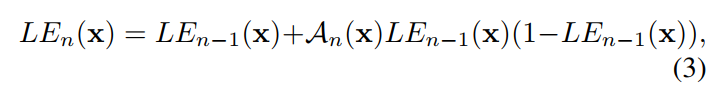
-
这里还有一个值得注意的点是,对于RGB三个通道,也是有各自的A的,因此,如果迭代次数为8,图像大小为 224 × 224 224\times224 224×224,那么网络的输出的shape则是 24 × 224 × 224 24\times224\times224 24×224×224
网络
- 然后产生预测值 A n ( x ) A_n(x) An(x)的网络是一个简单的7层卷积神经网络,并且没有BN和下采样,全部由3x3的32通道卷积和relu激活层组成
loss
- 文章用了四个non-reference的loss:
- Spatial Consistency Loss:衡量的是增亮前后 “每个像素与周边像素之间的差” 的差,个人觉得这个loss是为了维持纹理和内容不变。其中
Y
Y
Y是增亮后的像素值,
I
I
I是增亮前的输入值,
Ω
\Omega
Ω是像素的相邻像素
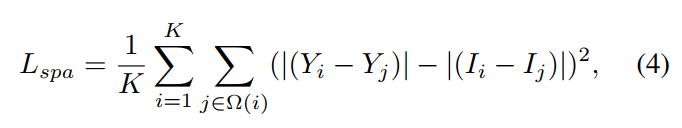
- Exposure Control Loss:E是人为设定的一个常数值,为0.6(文章说0.4-0.7之间都可以,效果变化不大),
Y
k
Y_k
Yk是一个patch的均值,将图片分为不相交的patch,然后算每个patch的均值与0.6之间的绝对差,作为一个loss,说是为了抑制过曝和欠曝。
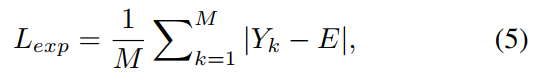
- Color Constancy Loss:即对增量结果的RGB三个通道各自的均值之间求差,是希望三个通道的均值尽量一样,也就是说整张图片看起来既不偏红也不偏蓝或绿。
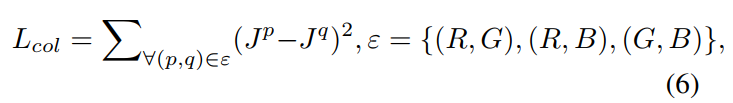
- Illumination Smoothness Loss:即TV Loss,约束梯度,使得预测结果尽量平滑
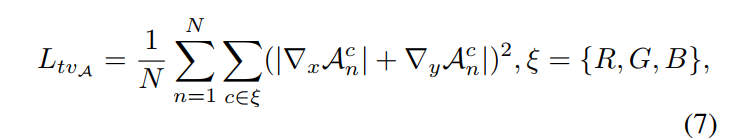
- 最终的loss function:
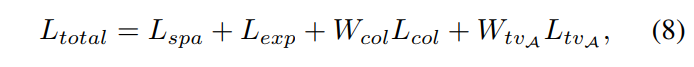
训练
- 鉴于这四个loss并不需要成对或不成对图像,因此是zero-reference的,只要有图就能训练,因此文章用的是现有的图片数据集,细节是当数据集的曝光程度更加多样均衡时,模型效果会更好。
Zero-DCE++
- 在文章的TPAMI版本 “Chongyi Li, Chunle Guo, and Chen Change Loy. Learning to enhance low-light image via zero-reference deep curve estimation. TPAMI, 2021. 3” 中,还提到了模型可以进一步轻量化,主要从三点考虑:
- 模型换成这个:“F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in CVPR, 2017, pp. 1251–1258”
- 8个curve map的差别其实很小,所以 可以只预测一个,用8次就行
- 本模型对scale不敏感,所以可以把图片downsample后送入网络,生成的curve map再upsample到原图大小进行亮度调整,可以节约计算资源。















 8178
8178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









