




 该文章介绍了一种CVPR2021的论文,其创新点在于使用一个分类模块对图像patch进行简单、中等、困难的分级,并据此采用不同复杂度的超分辨率网络进行重建。训练策略包括先训练超分辨率模块,然后联合分类模块进行训练。尽管实验结果显示分类对最终超分辨率结果的影响有限,但该方法在计算效率(FLOPs)方面有所提升,避免了所有patch都通过最复杂网络处理。
该文章介绍了一种CVPR2021的论文,其创新点在于使用一个分类模块对图像patch进行简单、中等、困难的分级,并据此采用不同复杂度的超分辨率网络进行重建。训练策略包括先训练超分辨率模块,然后联合分类模块进行训练。尽管实验结果显示分类对最终超分辨率结果的影响有限,但该方法在计算效率(FLOPs)方面有所提升,避免了所有patch都通过最复杂网络处理。

这是CVPR2021的一篇文章,核心思想是利用一个分类模块将patch划分为简单中等困难三个等级并对其进行分别的超分辨率重建,对难的patch用更深更复杂的网络,简单的patch用更浅更简单的网络。
-
分类模块采取的损失是经典的两种基于熵的无监督分类损失:Class-Loss 和 Average-Loss, Class-Loss使得单次预测的分类更加趋向于one-hot,也就是说具有更高的置信度和更低的熵;Average-Loss使得多次预测的均值更加的分散,多个类别都有所涉及,也就是说平均起来具有更高的熵。这两个损失的结合是很常见的无监督分类损失。
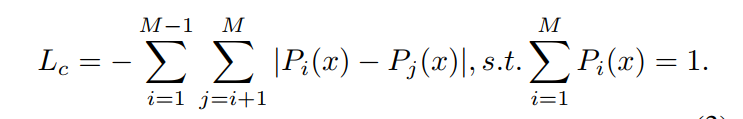
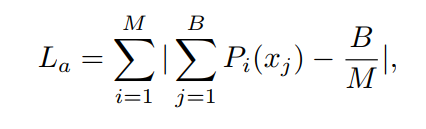
-
训练策略是先用Image-Loss单独训练SR模块,然后fix SR模块,串联起来,用三个损失训练分类模块。训练的时候,每张图片仍然是要通过全部的三个SR模块的,但是根据分类值的输出对这些SR模块的输出结果进行加权平均,对加权平均的结果计算图像超分辨率损失,而测试则只选取最高概率值的那一个去SR。
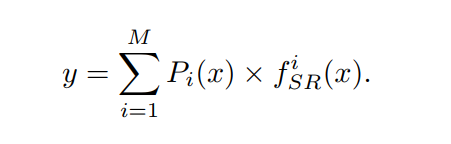
-
但其实从实验结果来看好像分类并不带来多少影响:

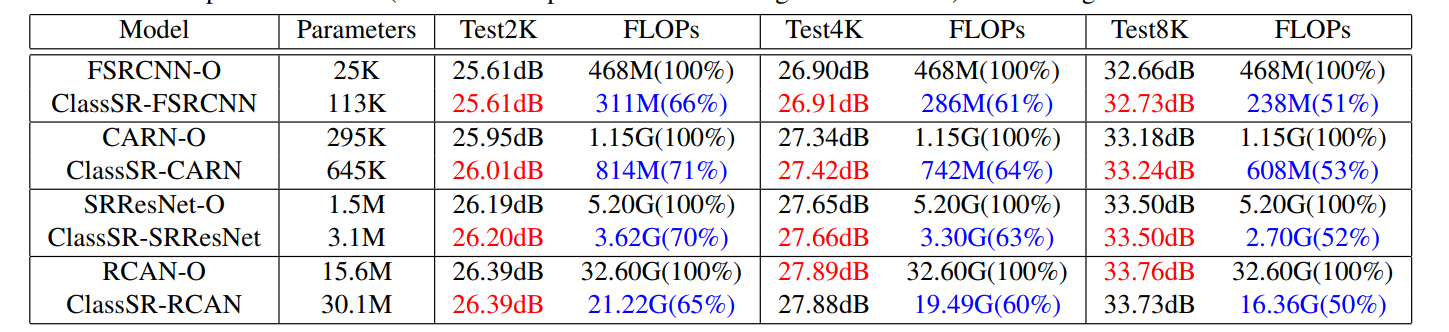
-
总的来看,优势并不在最终SR的结果上,这是可以理解的,毕竟除了分类模块,SR模块用的是现有的,所以不可能超过现有的。参数量也增加了,也是可以理解,毕竟用了多个SR网络和一个分类网络。优势在于FLOPs,因为并不是全部的patch都需要经过最大的那个SR网络。

















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









