








这是TCSVT 2022 的一篇自监督暗图增强的文章,其中untrained NN priors部分、去噪部分、直方图均衡损失部分都非常值得研究
- 文章提到了一个我没了解过的概念:untrained NN priors,好像蛮有意思的,有机会得看看这一段的参考文献,了解一下这个领域,似乎是说用一个固定的随机矩阵作为网络的输入来训练网络,并且是zero-shot learning的,也就是在针对某种图片要求预测结果时,利用该图片直接进行训练,然后给出测试结果。
网络整体结构
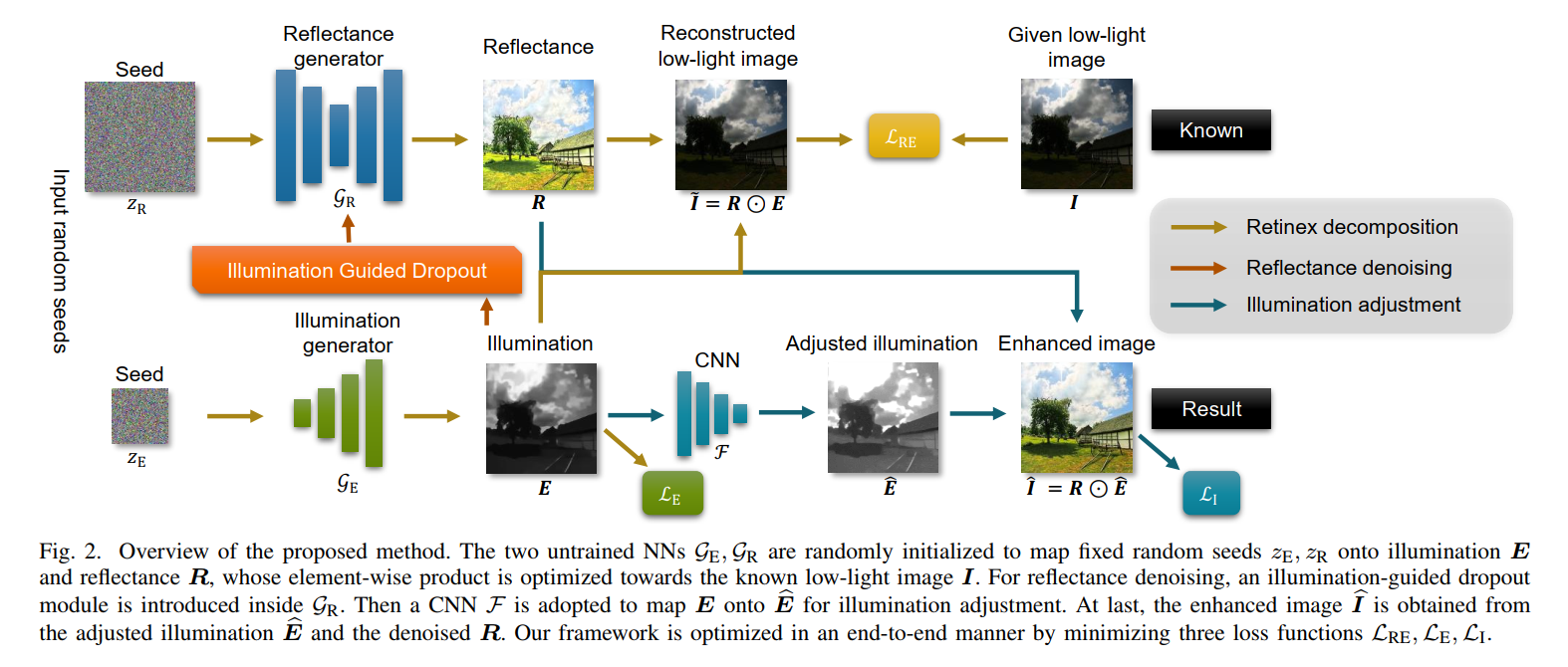
- 网络是基于retinex 模型设计的:
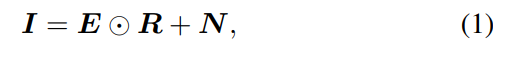
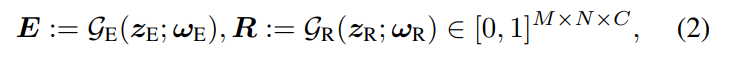
- 首先通过两个子网络来生成照度分量E和反射分量R。其中R和图片大小相同,而E可能比图像小,在后续的增强网络再上采样回到图片大小。


- 然后通过一个增强网络
F
F
F 生成增亮后的
E
^
\hat E
E^,预测的增强结果
I
^
\hat I
I^即为
E
^
\hat E
E^与
R
R
R的乘积。损失函数由下面三部分组成,分别是重建损失、
E
E
E的正则损失和
I
^
\hat I
I^的正则损失。
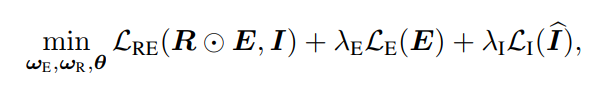
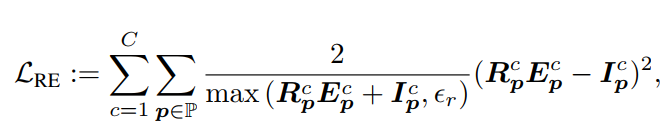
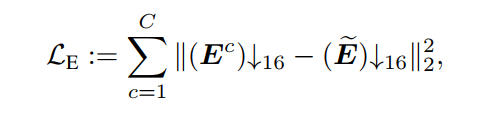
- 其中p表示position坐标,c表示通道坐标
retinex decomposition
- 基于 E E E 分量通常较为光滑,并且低计算复杂度的神经网络通常倾向于预测更加平滑的纹理,作者将分解网络生成 E E E 的部分 G E G_E GE设计为一个小网络,生成 R R R 的部分 G R G_R GR设计为一个大网络,并且对预测的 E E E 进行正则惩罚。
- 看论文的伪代码,发现untrained NN priors原来指的是一种特殊的无需图像数据集训练的Zero-Shot learning方式,在针对某张图片作为输入要求获得增强结果时,针对该图片进行训练,训练的输入是一个随机生成的从正态分布中采样出来的噪声(shape等同于图片的随机矩阵),通过在这样的随机矩阵数据集上训练可以获得针对该图片的无监督损失函数的一个适应性,训练完成后直接针对该图片获得预测结果。
- 为了应对噪声,在 G R G_R GR的训练过程加了空间上的dropout,并且这些drop-out是基于预测的 E E E的。文章认为,R的预测受噪声的影响较大,容易overfit,而加drop-out能一定程度上使得预测的R受噪声影响较小(这一思想应该是借鉴自无监督去噪Noise2Void);另一个理由是,信噪比较高的区域受噪声影响小,因此可以有较小的drop-out 几率,反之亦然。而基于E值高的区域信噪比高的认知,最终用1-E作为drop-out rate对R的前向传播过程进行drop-out以消除噪声。而在测试过程中,并不关掉drop-out,而是继续使用随机的drop-out,并对同一图片多次预测结果进行平均以消除噪声影响。(这个方法很有意思,我觉得很值得试试)
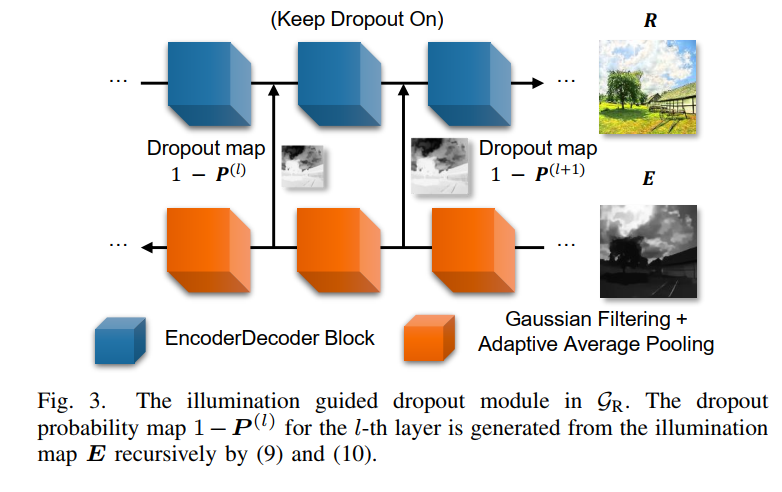
- G R G_R GR的网络结构是一个encoder-decoder结构, G E G_E GE是一个上采用的decoder结构,注意 G E G_E GE的输入是下采样的结果,并且输出只有一个channel,copy成3份变成三个通道以进行后续的运算。
Illumination Adjustment
- 对 E E E进行增强生成 E ^ \hat E E^的操作是Gamma校正: f γ ( x ) = m a x ( x , ϵ f ) γ f_γ(x) = max (x, ϵ_f)^γ fγ(x)=max(x,ϵf)γ
- Gamma校正所用的
γ
\gamma
γ是通过一个轻量的CNN预测的,而损失函数如下:该损失函数是基于直方图均衡化设计的,最小化该损失等效于直方图的均衡化。其实就是把0-255一共256种像素值作为256个类别,求的损失是这256个类别的熵,因此增强结果只有在直方图均衡的情况下能够使得该熵最小。

实验结果
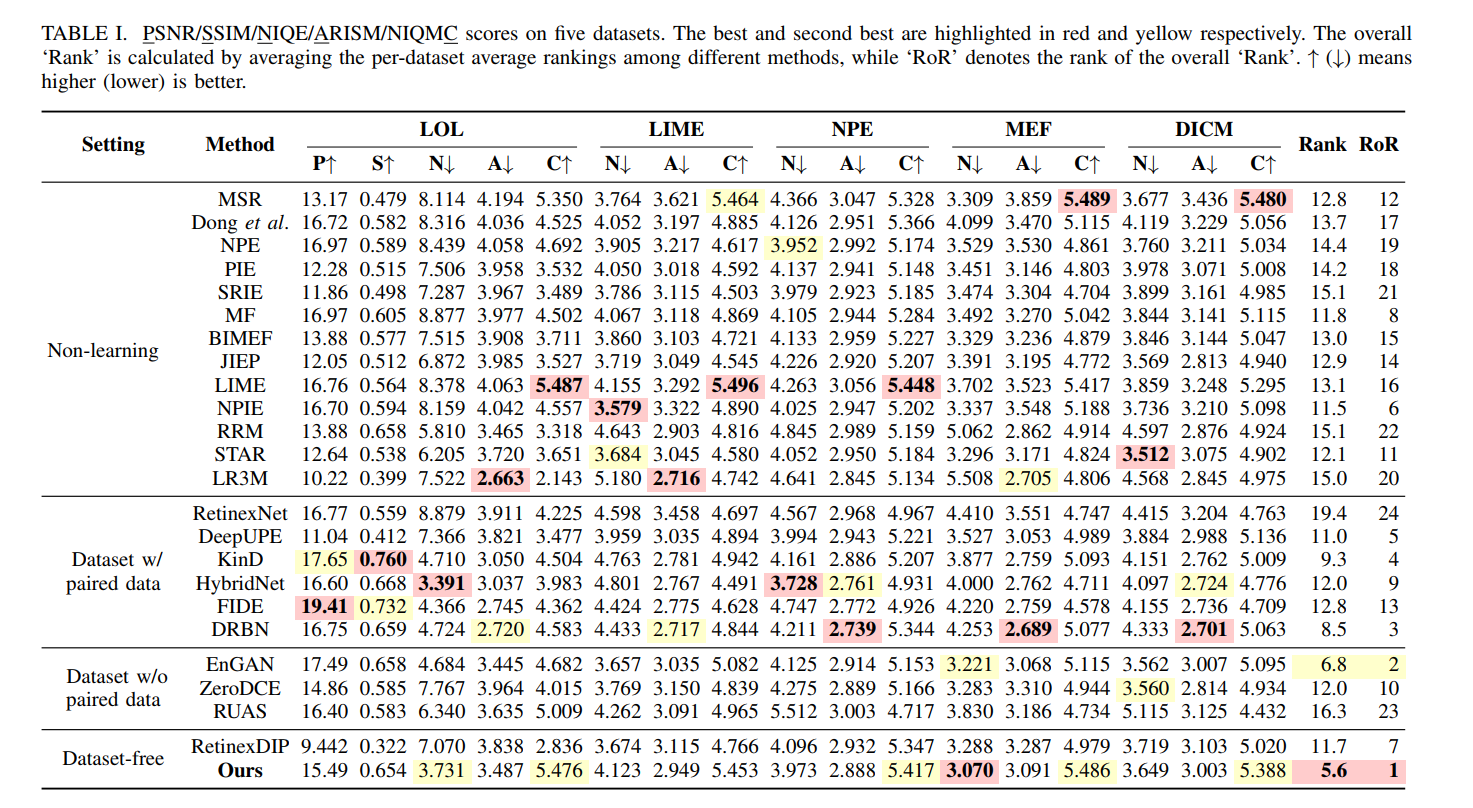
- 文章比较了在多个成对数据集上的PSNR、SSIM、NIQE等指标。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









