








-
CVPR2023的一篇暗图增强的论文,电子科技大以及李重仪老师的合作论文
-
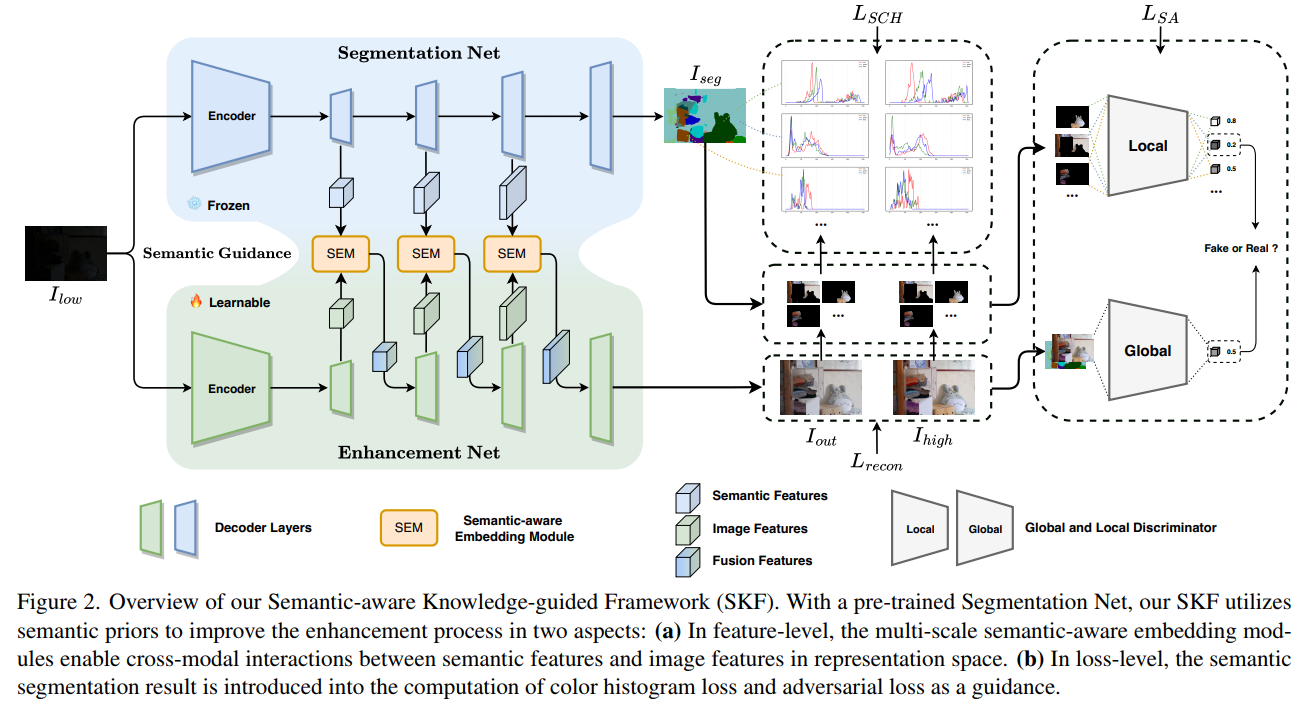
文章网络结构如下图所示。从图示可以看出来,语义分割任务以三种形式参与了暗图增强的训练,第一种形式是直接的语义分割网络的特征图通过SEM注入到暗图增强网络中,第二种形式是通过语义分割的结果计算各个分割区域的增强结果直方图和GT直方图之间的分布差,第三种形式是各个分割区域的增强结果和GT的对抗损失:
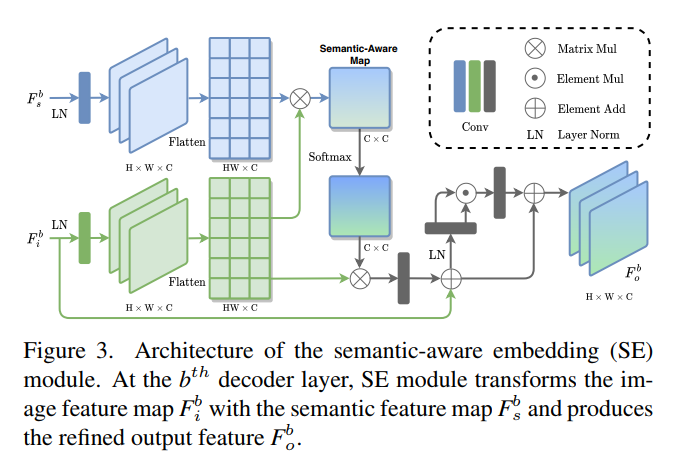
SEM模块如下图所示,是基于注意力的交互:
-
直方图损失则直接用L1计算两个直方图(用sigmoid提取直方图)之间的差:

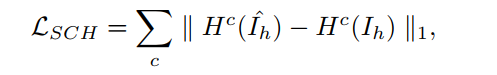
-
对抗损失分为局部和全局。全局就是把分割图和图片concatenate到一起送进discriminator,局部则是对各个mask的部分分别算discriminator的分类输出,然后取分类器输出为fake概率最高的那个计算损失,更新权重。
-
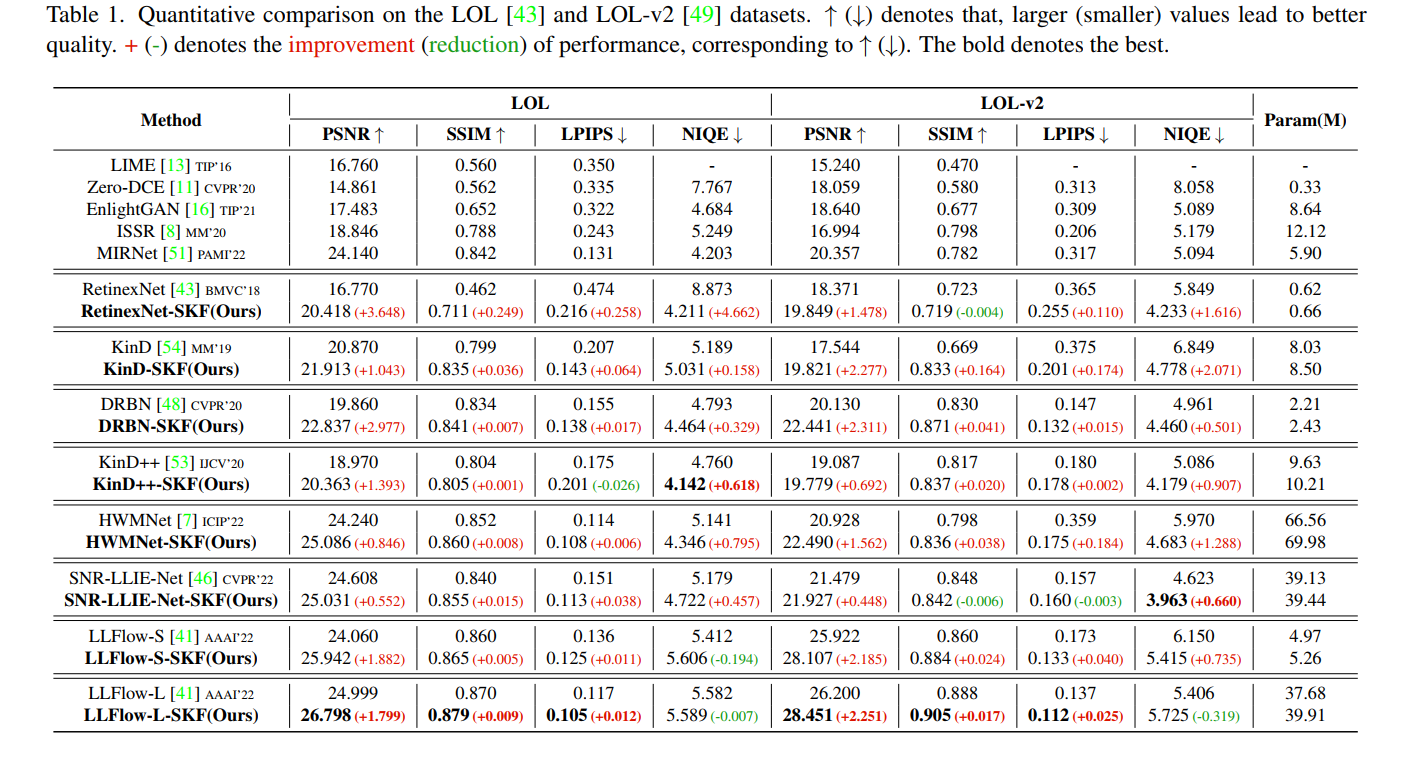
从实验结果看,各个根据本文提出的SKF改进的有监督方法都能从语义信息中得到性能的提升:

-
- 在暗图增强中引入语义信息来使得增强结果更加真实是我之前就有在考虑的内容,但是这个太难了而且网络搭起来可能比较复杂,今天看到有人做了还是挺惊喜的。















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









